All Summaries for Latent Space: The AI Engineer Podcast — CodeGen, Agents, Computer Vision, Data Science, AI UX and all things Software 3.0

The podcast by and for AI Engineers! We are the first place over 50k developers hear news and interviews about Software 3.0 - Foundation Models changing every domain in Code Generation, Computer Vision, AI Agents, and more, directly from the founders, builders, and thinkers involved in pushing the cutting edge. Striving to give you both the definitive take on the Current Thing down to the first introduction to the tech you'll be using in the next 3 months! We break news and exclusive interviews from tiny (George Hotz), Databricks, Glean, Replit, Roboflow, MosaicML, UC Berkeley, OpenAI, and more. www.latent.space

Doing it the Hard Way: Making the AI engine and language 🔥 of the future — with Chris Lattner of Modular
Want to help define the AI Engineer stack? Have opinions on the top tools, communities and builders? We’re collaborating with friends at Amplify to launch the first State of AI Engineering survey! Please fill it out (and tell your friends)!If AI is so important, why is its software so bad?This was the motivating question for Chris Lattner as he reconnected with his product counterpart on Tensorflow, Tim Davis, and started working on a modular solution to the problem of sprawling, monolithic, fragmented platforms in AI development. They announced a $30m seed in 2022 and, following their successful double launch of Modular/Mojo🔥 in May, have just announced their $100m Series A.While the performance claims of Mojo🔥 and its promise as a fully multithreaded compiled Python superset stole the show, we were amazed to learn that it is a side project - and the vision for Modular’s Python inference engine is at least as big.Listeners will recall that we last talked with George Hotz about his work on tinygrad and how he wants to replace PyTorch with something faster and lighter, handwriting a “reduced instruction set” of operators himself. But what if the problem could be solved at even lower level - with the Python engine/runtime itself?Chris on CompilersChris’ history with compilers is well known - creating LLVM during his PhD (for which he won the 2012 ACM Software System Award), hired straight into Apple where he also made Clang and Swift (the iPhone programming language that replaced Objective-C), then leading the Tensorflow Infrastructure team at Google where he built XLA, a just-in-time compiler for optimizing a lot of the algebra behind TF’s workloads, and MLIR, a modular compiler framework that sat above LLVM to optimize ML graphs and kernels that were hard to represent in the LLVM IR. So as pretty much the best compiler engineer in human history, you’d justifiably assume that Chris is simply choosing to take his compiler approach to Python. And yet that is not how he thinks about compilers at all. As he says in our chat,“How do you enable invention? How do you get more kinds of people that understand different parts of this problem to actually collaborate? And so this is where I see our work on Mojo and on the engine……I don't have a compiler hammer that I'm running around looking for compiler problems to hit.”Today a small number of people at companies like OpenAI spend a lot of time manually writing CUDA kernels. But an optimizing compiler for AI leads to compilers as a means to an end for increasing software collaboration, expanding the ability of people with different skillsets and knowledge.“…What is the fundamental purpose of a compiler? Well, it's to make it so that you don't have to know as much about the hardware. You could write everything in very low-level assembly code for every single problem that you have… But what a compiler really does is it allows you to express things at a higher level of abstraction.”For Chris, compilers are also ways to properly automate generalized optimizations that might otherwise be manually coded and brittle abstractions, like operator fusion:“So NVIDIA goes and they build this really cool library called FasterTransformer. The performance point of using it is massive. So a lot of LLM companies and other folks use this thing because they want the performance.…Here's the problem. If you want to go innovate in transformers, now you're constrained by what FasterTransformer can do, right? And so, again, you come back to where are compilers useful?They're useful for generalization. If you can get the same quality result or better than FasterTransformer, but with a generalized architecture, well now you can get the best of both worlds, where you have orthogonality and composability, you enable research, you also get better performance.”Done correctly, these operator optimizations being implemented at the compiler level amount to an “AI Engine” that can not only survive, but enable major architecture shifts should a credible alternative LLM architecture come along someday.Modular — the Unified AI EngineModular’s original goal was to build the “Unified AI Engine” to speed up AI development and inference - one that doesn’t assume an “AI = GPUs” world that only benefits the “GPU-rich”, but one that treats AI as “a large-scale, heterogeneous, parallel compute problem”.Modular itself is an engine (separate from Mojo, which we cover below) that can run all other frameworks between 10% to 650% faster on CPUs (with GPU support coming in the fall):At Google, Chris’ job wasn’t to build the best possible compiler for AI. The goal was to build the best compiler for TPUs, so that all TensorFlow users would have a great Google Cloud experience. Similarly, the PyTorch team at Meta isn’t trying to make AI faster for the world, but mostly for their recommendations and ads systems. Chris and Tim realized that the AI engine and developer experience isn’t a product prioritized by any of the big tech companies (they tried) - so they see Modular as the best way to deliver the AI development platform of the future. The modularity of Modular shines through in the hot-swapping Inference Engine demo, which has to be seen to be believed.Mojo 🔥 — Blazing Fast PythonThe other piece of Modular is Mojo, a new programming language for AI that is a superset of Python. In some sense it is “the ultimate yak shave”: We were shocked to learn that Chris and the team didn’t initially set out to create Mojo, but it started life as an internal DSL to make themselves more productive.Mojo adopted Python’s syntax since it’s by far the most used language in machine learning and AI. It also lets them supports all existing PyPi packages, requiring no code changes for developers to go from Python to Mojo. Mojo comes with a lot of different underlying design choices that lead to much better performance:* It’s compiled rather than interpreted like Python* No GIL which allows for multi-threading* Better heap representation* Leverages MLIRIn the perfect test scenario that leverages all of these improvements, Mojo is up to ~68,000x faster than Python 🔥 (fire emoji is a valid file extension for Mojo files, btw!). Of course, that is just one microbenchmark, but as Jeremy Howard explains, most Python codebases should run between 10-100x faster simply by moving to Mojo with very minor adjustments. A community member port of Llama2 from Python to Mojo shows it inferencing >100x faster than Python, and 20% faster than the handcoded raw C implementation.The Modular team is embarking in one of the hardest technical challenges we’ve seen a startup tackle, and we can’t wait to see what comes out of it. We had an amazing conversation with Chris diving into all the details, which we hope you enjoy!Show Notes* Modular AI* Chris’ personal website* Scott Forstall* Bret Victor’s Playgrounds* Karpathy’s Tweets* Speculative Execution* Llama memory constraints* LLVM* Clang* Swift* TensorFlow* PyTorch* XLA* MLIR* TPUs* Guido van RossumTimestamps* [00:00:00] Introduction* [00:00:40] Chris's background - LLVM, Clang, Swift* [00:03:01] Chris's experience with Google TPUs and XLA* [00:05:47] The limitations of current frameworks like TensorFlow and PyTorch* [00:08:03] The benefits of using compilers for AI systems* [00:13:14] Enabling more collaboration between researchers through better systems* [00:20:55] Starting with CPU optimization instead of just GPUs* [00:24:36] Design principles and goals behind Modular* [00:32:41] The benefits of starting from a general compiler architecture* [00:35:13] Origins of deciding to create the Mojo language* [00:44:43] Goals for Mojo to become a true Python superset* [00:48:12] Thoughts on tinygrad* [00:52:00] ggml, quantization, etc* [00:57:00] Speculative execution and other gains from making Mojo more parallel* [01:01:50] Future of Mojo’s toolkit* [01:07:00] Why Modular is a company and not a foundation* [01:11:00] Learnings as a first time founder and engineering leader* [01:25:00] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai. [00:00:19]Swyx: Hey, and today we have Chris Lattner in the house. Welcome, Chris. [00:00:21]Chris: Hi both. Thanks for having me. [00:00:24]Swyx: We're so excited to have you. We have so many questions and we'll try to get through as many as we can. You're one of the easiest people to research I've ever had on the pod, because you document yourself extensively on https://nondot.org/sabre/. What's the story behind that, just quickly? [00:00:40]Chris: I mean, I've had that website for, since, I don't know, the mid-90s. So it's been a very, very, very long time, and I originally had a big personal page. Again, this was the mid-90s with all the scroll tags and all that kind of stuff. Yeah, exactly. [00:00:56]Swyx: The animated gifs. “Under construction.” [00:00:57]Chris: Yeah. It has been rebooted a few times, and web design is not my strong point, but the server was originally named after some fish we had. That was the origin of non-dot. [00:01:08]Swyx: I love it. I looked on Tanya's page and she has some spaniels. [00:01:12]Chris: Yep. We're dog people. We love many animals. [00:01:15]Swyx: So your quick bio, you did your PhD in CS in 2005, and then immediately went into Apple working on LLVM, the compiler framework that you created during your PhD. In our prep, you also maybe had a favorite Scott Forstall story. [00:01:32]Chris: Well, so I got to work with a lot of really interesting people at Apple. Scott was actually pretty famous. Scott is responsible for many things across the years, but he really drove the iPhone. At least the iPhone software, specifically. And so Scott was super interesting because he was kind of a high-maintenance person. He was very difficult to work with. He did not mind making other people wait for him. So there'd be all these exec reviews of Scott where the entire room is full of people. He's sitting across the hallway in his office for a half hour making people wait for him. And so when Scott was at Apple, I wasn't his biggest fan, I'll admit, but I actually have a lot of respect for a lot of the things he did. He drove a lot of the early iPhone stuff. He made the bet on Siri and a bunch of other stuff that he did. And so he's a very impressive person. I guess he's out of tech these days, but yeah, so many fascinating. [00:02:25]Swyx: My favorite story was the keyboards and how they basically had to invent predictive typing or it wouldn't work. [00:02:31]Chris: Yep. It's all software. So much of that, it feels obvious now because it's been developed for years and years and years, but it was like pure research and nobody knew if you could get all of that software to fit on such a constrained device for 1.0. So it's just an amazing time. [00:02:45]Swyx: Incredible. So I'll fill out the bio a little bit. You started working on Clang while at Apple, I think, as a front-end for C and Objective-C. You created Swift as well in 2010. And then in 2012, won the ACM Software System Award for LLVM, which I think is a crowning accomplishment for a lot of things. [00:03:01]Chris: I love to build things. [00:03:03]Swyx: You were VP of Autopilot at Tesla and then Senior Director and Distinguished Engineer at Google for TensorFlow. And then most recently, President of Product Engineering at RISC-V, or at SiFive, which builds RISC-V. [00:03:15]Chris: They're the inventors and they drive so much of RISC-V is a really fancy new instruction set for a lot of computing needs and led to a lot of AI chips and so much that exists out there. So it was a lot of fun. And so that was actually driving and building hardware. And so most of my career I spent on the software side of it. And so it was a lot of fun to be able to see the other side of how hardware comes together, how you design it, how you think about it, what are the trade-offs in that entire space. And so for a lot of years, I've been just on that hardware-software boundary. [00:03:48]Swyx: That's a lot of what we're going to talk about today with Modular Mojo. Well, so that's the brief history and you started Modular in 2022, about 20 months ago. What's one other thing on the personal side that people should know about you that people don't see on the LinkedIn because you're all into hardware-software boundaries and stuff? [00:04:05]Chris: I have kids, I like to do woodworking, I like to walk. And so often, I like to go walking with people and do walking one-ones and things like that. [00:04:15]Alessio: What's the latest woodworking project you've worked on? [00:04:18]Chris: Oh, I mean, I just built a Lego robotics table for my kids, so helping out with the school. And so, yeah, not the most fancy furniture, but I've also built furniture and many other things for the house. [00:04:29]Alessio: So I think the easiest thing for people to grasp so far has been Mojo, which is a superset of Python. And I think everybody talks about that because it's easier to grasp, but Modular's goal is to build a unified AI engine. And when I see unified, it implies things are not unified today, there's a lot of fragmentation, a lot of complexity. So let's start from the origin. What are some of the problems that you saw in the AI research and development space that you thought needed to be solved? [00:04:58]Chris: Yeah, great question. So if you go back just a few years ago to 2015, 2016, 2017 timeframe, AI was really taking off. It wasn't to the point where it is now, where it's obvious to everybody, but for those of us who were following, amazing things were happening. And that era of technology was powered by TensorFlow and powered by PyTorch, right? And PyTorch came a little bit later, but they're both kind of similar designs in some ways. The challenge there is that the people building these systems were driven by the AI and the research and the differential equations and the auto diff and all these parts of the problem. They weren't looking to solve the software-hardware boundary problem. And so what they did is they said, okay, well, what do we need to build? We need a way for people to set up layers. So we need something like Keras or NNModule or something like that. Well, underneath the covers are these things called operators. And so you get things like convolutions and matrix multiplications and reductions and element wise ops and all these different things. Well, how are we going to implement those? Let's go take CUDA and let's go take the Intel math libraries, Intel MKL, and let's build on top of those. Now doubt really well, but the challenge with that is that whenever you come out with a new piece of hardware, even if it's just a new variant of an Intel CPU, you have initially a small number of these operators. But today TensorFlow and PyTorch have thousands of operators. And so what ends up happening is each of these things get what's called a kernel. Each of these kernels ends up being written generally by humans manually. And so if you bring up a new piece of hardware, you have to then re-implement thousands of kernels. This makes it very difficult for people to enter the hardware space. The other side of it though is research, right? So if you're a researcher, very few people know how these kernels work, right? [00:06:41]This is coming in vogue. You hear about people writing CUDA kernels, for example. And I mean, the people who do this are amazing and I love them, but there's very few of them and the skill sets required to do that are just very different than innovating in model architecture, right? And so one of the challenges that we've seen with a lot of these AI systems has been the scalability problem of I can't find experts who can go write these kernels. Now, when I got involved with work at Google, we were working on Google TPUs. Google TPUs are one of the most successful at-scale training accelerators that exist. And one of the challenges that we face as a team is this challenge of saying, how do we bring up a novel piece of hardware given you have thousands of these different things? And really the goal at Google initially was catalyze and enable a ton of research. Now, one of the things that was done before I got there and that was novel and it attracted me there is people said, hey, let's use compilers for this. So instead of handwriting thousands of kernels and rewriting all of these operators and trying to do what Intel or what NVIDIA had done, they said, let's take a different approach. And compilers can be way more scalable than humans because compilers can allow you to mix kernels in different ways. And there's a number of these optimizations that are really important that you've talked about before, including kernel fusion, which can massively reduce memory traffic and things like this, and these other reassociations and optimizations that you want to be able to do. [00:08:03]Chris: And a compiler can do that in a very general way. Whereas if you're doing it with traditional handwritten kernels, what you get is you get a fixed permutation of the ones that people thought were interesting. And so the things that worked are the things that have already been important, not the things that researchers want to do next. And a lot of research is doing new things, right? And so the investment in compilers led to this thing called XLA, which is part of the Google stack. Really great, enabled massive exaflop scale computers, tons of amazing work was done with that. But there was another problem, right? The big problem was that, okay, well, it was brought up to enable one piece of hardware, in that case, Google TPUs. And it turns out building compilers is hard. And there's a different scalability problem, where before it was hard to hire lots of humans to write lots of kernels. Now you have to hire compiler engineers. And there are even fewer compiler engineers that know machine learning and know all this stuff. And so what actually happened there is that there's a bunch of technical innovation and a lot of good things that came out of it. But one of the challenges was something like XLA is it's not extensible. And so you can technically extend it if you're at Google and you work on TPUs and you have access to the hardware, right? But if you're not, then it becomes a real challenge. And so one of the things I love about the NVIDIA platform in particular is that if you look at CUDA, like many people get grumpy about CUDA for various reasons, but you go all the way back to when AI took off, like deep learning took off with the AlexNet moment, for example, right? So many people will credit the AlexNet moment as being a combination of two things. They say it's data, ImageNet, and compute, the power of the GPUs coming together. And that's what allowed the AlexNet moment to happen. But the thing they often forget is that the third part was programmability, because CUDA enabled researchers to go invent convolution kernels that did not exist, right? There was no TensorFlow back then. There was none of the stuff that existed. And so it's actually this triumvirate between data compute and programmability that enabled a novel kind of research to kick off this invention that became the entire wave of deep learning systems, right? And so to me, learning from many of these things, you have to learn from history, coming to modular saying, okay, well, how do we take the next step? How do we get to the next epoch in terms of this technology where we can get the benefits of humans who have amazing algorithmic innovation and ideas and sparsity and like all the things that are kind of on the edges of the research that could become relevant? How do we get the benefit of compilers? And so compilers do have amazing scale and generality to new kinds of problems. And then how do we get the benefit of programmability and mix all these things together? That set of insights is what led to modular and what we're doing with the AI engine. [00:10:44]Alessio: I think in one of your previous podcasts, you mentioned leaving people behind, you know, that are like not experts in certain things and they can't contribute. CUDA is great. And we had Tridao who created FlashAttention on the podcast. And when the new Cutlass version came out, he made FlashAttention too, because Cutlass was so much better. And like, he didn't have to worry about that. He could focus on it. How do you see the future of like AI development in kind of like a post-modular world? You know, do you think there's going to be a lot more collaboration at different levels of teams coming together? Or is one of your goals like allowing people that are not compiler experts to like not even think about it and assume they already got the best? [00:11:22]Chris: Yeah, well, so I mean, my general belief is that humans are amazing, but we can't always fit everything in our head, right? And so you have different kinds of specialities, different kinds of people. And so if you can get them to work together, you can get something that's bigger than any one of them, right? I have certain skill sets, but I barely remember differential equations, right? And so it turns out that I'm not going to be inventing the next great model architecture, [00:11:45]Swyx: right? [00:11:45]Chris: But I'm useful for some of the systems problems. And so if we can get these people working together and collaborating together and understanding how these things work, like new breakthroughs can happen. And so Tree's interview with you, I think is a great example of that, right? He explained how, you know, he was working on different parts of the stack. He got interested in the systems. And he's a research group with Chris Ray, right? They have applications people that they work with, right? And so it really does, in my opinion, come back to like, how do you enable this flywheel? How do you enable invention? How do you get more kinds of people that understand different parts of this problem to actually collaborate? And so this is where I think that, you know, you see our work on Mojo and on the engine and things like this, what we're doing is we're really trying to drive out the complexity of this problem because so many of these systems that have been built up, you know, they're just aggregated together, right? It's like, here's a useful thing that enables me to solve the problem I want. And it wasn't really designed top to bottom. And I think the modular world provides is a much simpler stack that's much more orthogonal, much more consistent, much more principled. And that enables us to like reduce complexity all the way up the stack. Whereas if you're building on top of all this fragmented kind of mess of history, right? You just kind of have to cope with it. And a lot of the AI, particularly on the research systems, right? They have this happy path. And so if you do exactly the demo, the thing will work. But if you try changing anything just a little bit, everything falls apart and performance is awful or it doesn't work or whatever. And so that's an artifact of this fragmentation at the bottom. [00:13:14]Swyx: So you kind of view compilers and languages as medium for which humans can collaborate or cross boundaries. [00:13:20]Chris: I like compilers. I've been working on them for a long time, but work backwards from the problem, right? And if compilers are useful or the technology is compiler technology is useful to solve the problem, then that's cool. Let's use it. I don't have a compiler hammer that I'm running around looking for compiler hammer. Compiler problems to hit. Yeah, exactly. And so here, you say, what good is a compiler? Like what is the fundamental purpose of a compiler? Well, it's to make it so that you don't have to know as much about the hardware. You could write everything in very low level assembly code for every single problem that you have. But what a compiler or a programming language or an AI framer really does is it allows you to express things at a higher level of abstraction. Yeah. Now that goal serves multiple purposes. One purpose is that you make it easier, right? Second goal is that my opinion is that like, if you push a lot of complexity out of your head, you make room for new kinds of complexity. And so it's really about reduction of accidental complexity so that you can wrestle with the inherent complexity and the problem. Another is that by getting abstraction, right, you enable, for example, one of the things that compilers are good at, particularly modern ones like we're building, is that the compilers have infinite attention to detail. Humans don't, right? And so it turns out that, you know, if you hand write a bunch of assembly and then you have a similar problem, well, you just like take it and hack it a little bit without doing a first principles analysis of the best way to solve the problem, right? Well, compiler can actually do a lot better than that because CPU cycles are basically free these days. [00:14:42]Swyx: Yeah, exactly. [00:14:42]Chris: And also higher levels of abstraction give you other powers. And one of the things I think is really exciting about deep learning systems and things like what Modular is building is that it has raised compute to this graph level. Once you have gotten things out of for loops and semicolons and, you know, out of the muck and into something that's more declarative, well, now you can do things where you transform the compute. This is something that I think that many people don't yet realize because it's kind of possible, but it's really such a pain with these existing systems is that, you know, a lot of the power of what this abstraction provides is the ability to do things like Pmap and Vmap, like where you're taking a computation and then transforming it. And one of the things I was very inspired by my time at Google is, you know, we started out with these very low level things and, you know, single node GPU machines and then clusters and then async programming, like all this very little stuff. And by the time I had left, we had had, you know, researchers in Jupyter Notebook training petaflop supercomputers. You just think about that. That is an enormous lift in terms of the tech. And that was made possible by a lot of very layered and well-architected systems, by a lot of, you know, novel HPC type hardware, by a lot of these breakthroughs that had happened. And so what I'd love to see is for that technology to get even more widely adopted, generalized and get out there and also kind of break down a lot of the complexity that got built up along the way. Beautiful. [00:16:09]Swyx: You use very precise terms, AI engine, AI framework, AI compiler. And I think that means special things for you, especially within the modular context. Do you care to define them so we can have context for the rest of the conversation? Yeah, absolutely. [00:16:22]Chris: That's a great point. When I think about framework, I'm usually talking about things like TensorFlow and PyTorch. These are things that, you know, most people building a model will use something like PyTorch to build it and train it and do things like that. Underneath that, you end up getting a whole bunch of ways to talk to the hardware. And often it's CUDA or Intel MKL or something like this. And so those things are the engine. And that interface of the hardware is generally what I think of when I talk about an engine. [00:16:48]Swyx: Right. And modular is a new engine. Yes. [00:16:51]Chris: And modular is providing a new engine that plugs into TensorFlow, PyTorch, and a whole bunch of other stuff. And then allows you to drive, manipulate, program the hardware in a new way. [00:16:59]Swyx: Which I would recommend everyone check out the products launch demo where you swapped it out in real time and it just kept working. [00:17:06]Chris: Yep, yep. [00:17:07]Swyx: That was a big flex. [00:17:08]Chris: So I believe in properly modular, properly layered, properly designed technology. And so if you get the abstractions right, you can do really cool things like this. [00:17:16]Alessio: Let's start diving deeper. So as you mentioned, you said between the framework level and the hardware level. So when it first got announced, I went on the website and I was like, wow, I wonder how many petaflops they get on an A100. And then I open and it's all CPUs. So my question is, everybody's trying to make GPUs go brr. Why are you making CPUs go brr first? [00:17:40]Chris: So this is the problem with doing first principles work. Is that you have to do all of the work from the beginning. And if you do it right, you shouldn't skip over important steps. What is an AI system today? Lots of people say, oh, it's a GPU. People are fighting over GPUs. They're always talking about, it's all about GPUs, right? AI, in my opinion, is actually a large-scale, heterogeneous, parallel compute problem. And so AI traditionally starts with data loading. GPUs don't load data, right? And so you have to do data loading, preprocessing, networking, a whole bunch of stuff. And then you do a lot of matrix multiplications. You do all the things that people usually talk about. But then you do post-processing and you send stuff out over a network or under disk, right? And so CPUs, it turns out, are necessary to drive the GPUs, right? And a lot of the systems, again, when you say, let's bring up software for the accelerator, what you end up doing is you say, okay, well, what can the accelerator do? It turns out it's a subset of the problem because they decided that the matrix multiplications or whatever they thought was important is the important part of the problem. So you then go build a system that does exactly what the chip will do. And you never have time to go solve the big problem. And so it's really funny when you look at something like a TensorFlow or like a PyTorch, so much of that host side compute problem, the CPU work, ends up being in Python, ends up being in these things like tf.data and stuff like this. Not programmable, not extensible, really slow in many cases, very difficult to distribute. And so there's a huge mess here. Also, if you look at CPUs, it turns out they are accelerators. So CPUs these days have tensor cores. They just get funny names like AMX instructions and things like this, right? And the reason for that is that it used to be that CPUs and GPUs were completely different things. What's happened over time is GPUs get more programmable and more like CPUs, and CPUs get more parallel. And so what's happening is we're getting a spectrum of this technology. And so when we started modular, we said, okay, well, let's look at this from a technology perspective. Hey, it makes sense to build a general thing because once you have a general thing, you can specialize. As I've seen with XLA and some of these other stacks, like it's very hard to start with the specialized thing and then generalize it. Also, it turns out that, you know, where's the spend in AI? Well, I mean, different people are spending different amounts of money, different things, but training scales the size of your research team, inference scales the size of your product and user base and everything else. And so a lot of inference these days is still done on CPU. So what we decided to do is we said, okay, well, let's start with CPU. Let's get improve the architecture. CPUs are also easier to work with and they don't stock out and they, you know, they're easier for a variety of other reasons. And let's prove that we can build a very general architecture that can scale across different families. And so what we showed is we showed, okay, we can do Intel, AMD, we can do this arm Graviton thing and showed a lot of support for, you know, all the different weird permutations of things within even an Intel CPU. There's all these different vector lengths and all this stuff going on and showing that we could beat the vendor software with much more general and flexible programming approaches. And then from there, yes, we're doing GPU. We'll have GPUs coming out soon. And then when you build into that, right, what you get is you get the benefit of a well considered, well layered stack that has got all the right DNA in it. And so then you can scale into these different kinds of accelerators over time. [00:20:55]Alessio: What are some of the challenges to actually build an engine? So I think the CPU point people have. So that's why you see LLAMA, CPP, you see some of this quantization where most people are thinking, let's take the model, quantize it, make it runnable on CPU and do that. You were like, no, I'm kind of like more crazy than that. How about we redo the whole engine? How does that differ in terms of work? So the model work is very kind of like weight specific. Yours is more like runtime, compiler specific. What does your team look like? And what are the challenges that you tackle to make an engine happen? [00:21:29]Chris: In terms of the technology or? [00:21:31]Swyx: Yeah. [00:21:31]Alessio: Kind of like, how do you even start? Like when you started this company, kind of like some people said, I'm going to change the weights and quantize them. You were like, I'm going to change the engine. You know, what are some of the low hanging fruits, maybe some of the initial challenges that you're working on? [00:21:45]Chris: Well, so, so I think a lot of what characterized modular is doing things the hard way to get a better outcome. [00:21:52]Swyx: Right. [00:21:52]Chris: So many of the people on our team, we've worked on all of the systems. So, you know, I worked on XLA and TensorFlow, the people that worked on PyTorch, TVM, the Intel OpenVINO stuff, like all of these weird things that have been created in the industry, Onyx Runtime, right? We have several really great people from there. And so many of these people have been working on these systems. And the challenge with them is that many of these systems were designed like five or eight years ago. [00:22:17]Swyx: Right. [00:22:17]Chris: And so AI was very different back then. There were no LLMs, right? I mean, it was a very different world. And so the challenge is, is that when you build a system, it starts out by being a pile of code and it gets bigger and bigger and bigger and bigger and bigger. And the farther along its evolution you get, the harder it is to make fundamental changes. And so what we did is we said, okay, let's start all the way at the beginning. Just like you're saying, yes, it's much harder. Again, I like to build things and I think our team likes to build things. And so you say, well, how does threading work? By the way, it's not often known, but TensorFlow, PyTorch, all these things still run the same thread pool that Caffe ran on. Widely known to be a huge problem, leads to massive performance problems, makes latency super unpredictable when you do inference. That one, a very specific set of design choices to make the thread pool block and be, you know, be synchronous. And like the entire architecture at the very bottom of the stack was wrong. And once you get that wrong, you can't go back. And so our thread pool assumes that no test can block. You have very lightweight threading, right? This goes directly into everything that gets built on top of it. You then go into things like, okay, well, how do you express kernels? Well, you still want to be able to handwrite kernels and we start by prototyping things in C++, but then you also get up into the mojo land. And so you build, you know, a very fancy auto-fusing compiler using all the best state-of-the-art techniques while also going beyond state-of-the-art because we know that users hate static shape limitations, lack of programmability. They don't want to be tied just to tensors, for example. And so a lot of LLMs have ragged tensors and things like that going on. Tabular data, you have like all these things. And so what you want to be building and one of the benefits of architecting things from first principles is that you can take all the pain that you've suffered and felt in other systems and you've never had a chance to do anything about it because of schedule, because of constraints from various kinds, and you can actually architect and build the right thing that can scale into that. And so that's, that's the approach we took. And so a lot of it was very familiar work, but it's very hardcore design engineering and you really need to know the second and third order effects of each decision. And fortunately, a lot of the stuff isn't research anymore. It's pretty proven. [00:24:31]Swyx: So you mentioned some design goals that you have in first principles. Do you have a list? [00:24:36]Chris: In what sense? [00:24:40]Swyx: Off the top of your head. Like, I think it's very useful when designing systems to have that list of principles. And I think you very much think of yourself as a first principles thinker, but I think your principles differ than most. And you've gained this insight over just studying a lot of AI work over the years. What are they? [00:24:55]Chris: I don't know that I have one set of principles that I, you know, it's like one, one club that I go around and beat things with. But a lot of what we're trying to do is we're trying to unlock the latent potential of a lot of hardware and do so in a way that's super accessible. And so a lot of our starting conditions was not like enable a new thing. It's much more about drive out the complexity that people are struggling with to do the thing. And so it's not research. It's about design and engineering. Now, when you look at this, we're also driving from, okay, let's enable the maximum power of any given piece of hardware. So if you talk to an LLM company and they just spent $200 million on GPUs and their A100 GPUs of a specific memory size or whatever, right? They want to get everything possible out of that chip and they don't want a lowest common denominator solution. Right? And so you want, on the one hand, full power. You want to go all the way down to the metal and be able to unlock these things. And some of these researchers like, like tree and others, I mean, they're freaking amazing. [00:25:57]Swyx: Right? [00:25:57]Chris: But on the other hand, a lot of other people want more portability, generality, abstraction. [00:26:03]Swyx: Right? [00:26:03]Chris: And so the challenge becomes how do you enable and how do you design a system where you get abstraction by default without like giving up the full power? And again, a lot of the compiler systems that have been, you know, compiler for ML type things have really given up full power because they're just trying to cover one specific point in the space. And so owning that and designing for that, I think is really important to what we're [00:26:25]Swyx: doing. [00:26:25]Chris: And other pieces, just sympathy for users, because a lot of people that get obsessed about the tech forget about the fact that the people that will be using it will be very different than the people that are building it. That aspect is actually really important when your developer tools fundamentally is to understand that the developers that are using it, they don't want to know about the [00:26:44]Swyx: tech. [00:26:44]Chris: One of the things that's super funny about working on compilers is nobody wants to know about a compiler. You're building a Mojo app or you're building a C app or whatever, right? You just want the compiler to get out of your way or tell if you did something wrong, right? If you're thinking about the compilers because it's too slow or it's, you know, broken in some way or something. And so AI tech should be the same way, right? I mean, how much of building and deploying a model is fighting with the tools? Get some crazy Python stack trace out of some tool because it covered the special case and now you're off that happy path, right? And so that compassion for users is something I think that, largely because AI infrastructure is so immature, but it's never been really part of the ethos of the people building tools. [00:27:22]Swyx: You chose things like, you know, your third pool has everything non-blocking. The sum of your first principles have led the module inference engine to be two to three times faster than PyTorch and TensorFlow, right? [00:27:33]Chris: Oh, I was trying to look at it. [00:27:34]Swyx: I'll show a decomposition of performance. Okay, well, yeah. So you can talk about that too. [00:27:38]Chris: So one of the really funny things that if you get it wrong, it's very difficult to fix is asynchrony. And so when you think about, I have a CPU and I have a GPU and they talk to each other, most people think about it in terms of CPUs doing some stuff that throws a CUDA kernel across the fence, GPUs go brr, right? And then when there's results, you know, you read it back, right? But that's actually a really inefficient way to run a computer. What you actually want is you want to think about there's two different computers that are both executing and they're sending messages back and forth to each other. So I built hardware, right? If you go all the way down to the gates, when you look at this, these computers, whether they're the tiled cerebrus wafer thing, right? Hardware is implicitly parallel. All of these things are always running all the time and they're communicating with each other. And so starting from an asynchronous programming model means that you can get accelerators that send messages to each other because that's the natural form of the hardware. When you get into CPUs, CPUs, you have, you know, 88 core CPUs or a hundred core CPUs these days, even if you have four, right? What they really are is there are four completely independent computers. And so, yeah, they send cash lines across the fabric at each other, right? But they're async, right? And so much of the programming model that people start with is always sync. And so when you build into the stuff, you say, okay, well, that's a huge problem. The consequence of getting this right is that now you get overlapping work and it comes for free, right? And again, simplicity, the right architecture leads to the thing just magically happening. One of the great projects we did at Google back in the day involved some of this stuff and it led to a 2x improvement in ads throughput. Ads is a very tuned workload, right? And getting TPUs and CPUs to work at the same time and overlap that compute was a huge deal. And the fact that it just falls out of an async architecture is quite important. And again, you look at this at all levels of granularity, networking is asynchronous. So as soon as you distribute a compute problem across a network, async is there, right? And so all of these systems are kind of designed in the wrong way. You go up a level of the stack. So you have these operators, right? Super interesting how this whole ecosystem evolved. If you dig into something like TensorFlow or PyTorch, right? You know, you get to the point where you have a matrix multiplication. And so like you've talked about before on your podcast, kernel fusion is really important. And the way people did that historically is they say, okay, well, I have a matrix multiplication and oh gosh, it's often followed by a ReLU. Well, I'll make a MatMul ReLU fused kernel, right? Cool, and that's a huge performance improvement because ReLU is just a max operation and you avoid tons of memory traffic, all good stuff, right? You run into these scalability problems because now you get things like a fused attention layer. So what is the consequence of saying, I'm going to manually tune the things that are important for mlperf or something, right? Well, what ends up happening is, again, you get these happy paths and they work way better than the default path. And so if you look within the NVIDIA world, for example, there's a ton of focus on transformers. And so NVIDIA goes and they build this really cool library called Faster Transformer. The performance point of using it is massive. Like it's a big deal. And so a lot of LLM companies and other folks use this thing because they want the performance. Performance turns into cost and throughput and all good things. Here's the problem. If you want to go innovate in transformers, now you're constrained by what Faster Transformer can do, right? And so, again, you come back to where are compilers useful. They're useful for generalization. And so if you can get the same quality result or better than Faster Transformer, but with a generalized architecture, well, now you can get the best of both worlds where you have orthogonality and composability, you enable research, you also get better performance. One of the things that you ask, like, how can we beat state of the art? Well, it's because it turns out compilers have more attention span. And it turns out that what's happened, even within like the NVIDIA product line, or even within the Intel product line, or even within one vendor's line of technologies, is that they have to build these little compilers because there's so much variation across the product family. If you look at an Intel product family, for example, they're building software that has to run on many different versions of this architecture. And they come out and they add a cool new dot product instruction, or they add beeflet 16 support, or they add whatever. And so what's been happening in the industry is that each of these companies have been building their own little compilers. And so their own little compilers are, again, they're focused on one part of the PROM domain. They have all these issues. They're not scaled very well. And so you get either, again, another fragmented part of the space where something will work really well, usually for a benchmark, right? But then it doesn't work well when people try to do new things. And so kernel fusion turns out to be one of those things. The programmability side, right? I mean, you just keep working your way up the stack. Matrix multiplication is really important. So who's that thing that hasn't been invented yet? I mean, we have folks that are using our stuff that care about computational fluid dynamics, right? And things like this, where it's really more of HPC, linear algebra, like more general than deep learning, right? And they want to use the same technology because all this technology is general purpose. And so enabling people to express their PROM domains, and often they're experts in fluid dynamics, which I know nothing about, by the way. [00:32:41]Swyx: I mean, diffusion is another one that relatively recent new technique. Yeah, right. [00:32:47]Chris: And so like enabling people to innovate in this way without having to know all that thread pool, right? You know, they don't want to know about a thread pool. And so enabling people to be able to focus on the part of the stack they care about and have it compose in is super important. Again, many systems have been built that tackle individual pieces of these PROMs. They end up usually having very specific constraints and limitations and problems. And so what we're doing is we're saying, okay, let's do the hard thing. Go all the way back. Let's actually build things in the right way and layer them up and do so in a way that composes correctly. And then what that means is you're driving away all that complexity that comes from, you know, the blocks don't plug together. [00:33:25]Alessio: Yeah, even at the hardware level, I'm sure that the cerebros of the world are like really happy that you're building this because now they can offer binding. And then I think that's one of the main complaints from developers is like these chips sound great, but like, how do I use them, you know? [00:33:43]Chris: Well, and that's one. So we're still early in our journey, but I care a lot about hardware and we have many friends in the space. The challenge again, so I worked on TPUs as one example, but certainly not the only one. The challenge, if you're building innovative hardware is you have to build the entire stack from the very bottom to the top. And so if you talk about a cerebros, right, they've built some amazing stuff, but they've had to build their own vertical software stack. And now it doesn't work the same at the top level as anything else. And so even if it's really good, right, it means that there's this huge barrier of entry for a developer to switch to their tech stack. Sometimes they're, some of these things are better than others, let's just say, right? And so it turns out building stuff is really hard. And so a lot of what we're trying to do is, again, we're putting down bricks. Like we have to take steps in logical order. We have to build the technology in the right way. Like I insist that we do everything at a super high quality. But when you do that, what that means is that then you can have a thing that you can plug into. And no, we can't turn a cell phone into a data center supercomputer, right? But if you want to quantize your model, you shouldn't have to use different tools for a cell phone than you use for a supercomputer, right? It turns out the intake's the same. Yeah. [00:34:50]Alessio: Let's keep working our way towards the 35,000 times faster number that is out there. So you kind of keep going up and then you get to the Python level. [00:35:00]Swyx: Yep. [00:35:00]Alessio: And you're building Mojo, which is a Python superset. I'm also sure you didn't wake up one day [00:35:06]Swyx: and you were like, [00:35:06]Alessio: yeah, that sounds like a fun thing to do, creating a Python superset. Yep. What are some of the limitations that you saw there? [00:35:13]Chris: Yeah, well, so I'll tell you where it came from. Because when we started Modular, we had no intention of building a programming language. So this is the, again, it's not looking for reasons to invent a language. But if we have to invent one to solve a problem, then cool, let's do it. So what we did was we said, okay, let's start, again, thread pools and other very basic stuff. How do we integrate with existing TensorFlow PyTorch systems? Turns out that's technically very complicated and very yucky. But then you get into the more, okay, let's get the hardware to go broom, right? Prom, right? And so then what we decided to do is we invented a whole bunch of very nerdy, very low level compiler tech. And so our compiler, yeah, it does autofusion and stuff like this, but it's designed for cloud first compute. Because there's more than one computer in the world, right? [00:36:00]Swyx: And things like this. [00:36:00]Chris: And so caching, distribution, like all these things get built into the compiler. You want to use things like auto tuning, [00:36:06]Swyx: right? [00:36:06]Chris: Because of all the complexity in the hardware and humans are great at algorithms. Attention span is not always the right thing. And so there's these requirements that came out of this. And so what we did is we built this pure compiler technology and validated it to show that we could generate kernels with very high performance. We got to the point where we're building that all and we were writing this very low level MLIR stuff by hand. We're happy enough with it at the time, but our team hated writing the stuff by hand. And so we needed syntax and said, okay, well, this looks like a language. And so what choices do we have? We could either do a domain specific embedded DSL like thing, like Halide, or there's a whole bunch of these things [00:36:45]Swyx: that are out there, [00:36:45]Chris: or we could build a programming language. And so again, saying, let's do it the hard way because it gives you a better result. The problem with the Halide or like the OpenAI Triton thing, or like there's a whole bunch of stuff that's kind of in this category is that they have terrible debuggers. The tools around it are really weird. They demo really well, but often are best used by the people who built the tools themselves, things like this. What we decided to do is say, okay, well, let's go build a full programming language. I know how to do that, built Swift, learned a few lessons. I know both how to do it, but also what a big commitment it is to do that. And the consequence of that is you can do something that's much better. Now you have to go shopping for syntax, right? And so we'd built all this pure technology and we could do anything we wanted. Could use Swift, could use C++, [00:37:31]Swyx: could use whatever, [00:37:31]Chris: but obviously the entire ML community is around Python. And so we said, okay, well, let's go use Python. And then how are we going to do that? Again, you dive into these levels of decision-making and it's like, okay, well, there's a lot of things that are like Python, right? [00:37:45]Swyx: But they're not, [00:37:45]Chris: and they don't get adoption and they have huge problems and they fragment the community and all the things. And so I said, okay, well, let's actually do it the right way. Let's try to build something that it'll take time to get there. But in the end, it's a super set of Python. [00:37:57]Swyx: Why? [00:37:57]Chris: Well, Python syntax isn't actually the important thing. It's the community, the entire body of programmer muscle memory, right? Like all of these things are actually the important thing. And so building a thing that looks like Python, but it's not was never a goal. Let's go actually build and again, do the hard thing that leads to a better quality result that'll be better for the world. Even if it takes a little bit longer to build. I'm shocked. [00:38:21]Swyx: My jaw was like dropped the entire time you were saying this because this sounds like it's just a massive yak shave to improve your tooling to make yourself more productive, [00:38:29]Chris: which is crazy. [00:38:31]Swyx: Like most people start out trying to do the language first, but you came at a great point. [00:38:36]Chris: So we built it and we started on this path to make it so that our team would be more productive. And we say today, like the most important Mojo developers are at modular. And that's actually really important when you're building a language is use it yourself. This was a mistake we made with Swift is we built Swift to solve a people don't like objective C syntax problem. Roughly, but we did not have internal users before we launched it. Not significant ones, right? And so with Mojo, like we're actually using it. And it's the thing that powers all the kernels in our engine. And so it's actually needs to be production quality. But then you realize that shaving the act that finally is actually not actually not worth it, right? [00:39:15]Swyx: And we realized, okay, [00:39:15]Chris: well, Mojo is actually useful to lots of other people. And so this is when we announced it. We said, okay, well, yeah, we'll make this a standalone thing because we think it's valuable and interesting to the rest of the world as well. And then, of course, we'll invest in it more because it's not just us and we can tolerate pain, but we want people to fall in love with good tools. [00:39:31]Swyx: Yeah. And obviously you had a great stack already and good team, but like how long from realization that, oh, we need to start looking around for a language to something that looks like Mojo today? [00:39:41]Chris: Yeah. So the lexer and the parser for Mojo started in October. [00:39:45]Swyx: Wow. [00:39:45]Chris: So it's less than a year old. [00:39:48]Swyx: Yeah. [00:39:48]Chris: This is also another thing is that I'm a very strange person in many ways, right? My ideas of what are hard problems are really different than other people, right? But Mojo is a much smaller language than Swift is. [00:40:00]Swyx: Yeah. [00:40:00]Chris: And even when it's done, it will be a much smaller language. And so compared to building Clang, which is a full C++ compiler or Swift, which is itself a very complicated, fancy system for a variety of reasons, right? This is actually a small project. Yeah. Yeah. [00:40:15]Swyx: You still have to pick design choices from like Rust and whatever [00:40:18]Chris: Yeah, well, absolutely. And so we will see what happens with Mojo over time. I would like a big chunk of our stack that is currently written in C++ to eventually move over. And so having a very good system programming language that scales is quite valuable and useful for lots of reasons. [00:40:32]Swyx: One of the other things [00:40:33]Chris: I'll share with you is that starting from CPU, starting from the general thing that you then specialize leads to these design points, for example, in Mojo, where you say, okay, well, if I care about high performance data loading, that needs to be super parallel. I care about disks being parallel and network being parallel and async and all this stuff that needs to be safe, right? And so with Swift, we built a memory-safe parallel programming abstraction called Actors. We've built all this stuff. And so being able to take the lessons learned from building [00:41:03]Swyx: it the first time [00:41:03]Chris: and driving it into a system the second time means that you can make something that's much better than the first time around when you were just figuring things out. So, but starting from generality is really important. [00:41:14]Swyx: Every single language designer I've ever talked to has emphasized a playground and I was browsing your site and I realized that you had called the Xcode and Swift playgrounds a personal passion and you were inspired by Brett Victor. I guess, what have you learned about building a good playground? Because you just released modular like a few days ago, sorry, Mojo a few days ago, I was able to go in and play with it. What have you learned? And maybe what goes, what is underappreciated about like a good playground? [00:41:38]Chris: Yeah, well, so when we were building Swift, there's this big question about how do we do something better than what Objective-C had? Yeah, right. And so naturally it's like you've gone through all this work, [00:41:48]Swyx: you're building this new thing, [00:41:48]Chris: what can you do with it? When we first launched, we wanted to make something very visual. Apple's a very visual company, right? It likes user interfaces [00:41:56]Swyx: and stuff like this. [00:41:56]Chris: And it turns out that we as humans, many of us are very visual learners and thinkers. One of the things that playgrounds for iOS and for the Mac allows you to do is play with time. And so what happens is that there's a graphical view of a canvas roughly, right? You then run your program and you have a ball bouncing or whatever the thing is that's happening. And now you can scrub through time because it can log and keep track of a bunch of state. And so this is one of the cool things about building systems and controlling it top to bottom is that you can build these kinds of experiences. One of the fun projects I was able to work on at Apple is this thing called Swift Playgrounds. And so it's actually an iPad app. The entire purpose is to teach kids how to code, right? And so one of the cool things about that is that that led to this whole area of research, to me at least, and around UI design for saying, for Playgrounds, how do I do coding on an iPad without popping up a keyboard, right? And so, exactly, very interesting technical problem, very different than compilers, turns out, right? And so we spent a lot of time working on gestures for like, you know, moving braces and blocks and refactoring code and doing all this stuff, making it so that it's super predictably understood what identifiers were in scope. And so complete the identifiers instead of you having to type them, instead of typing in numbers, like you get a little spinner. [00:43:12]Swyx: That's not just for kids. [00:43:14]Chris: And so it's super awesome. One of the things that came out of that is the current iPad keyboard allows you to swipe down on keys instead of going through modifiers. And so that came out of that project. And so there's a lot of the stuff where being able to build this stuff enables you to re-ask old questions. Yeah. [00:43:33]Swyx: Oh, that's great. I love the scrubbing stuff. And Brent actually worked at Apple. It probably overlapped with you. I actually never met him. [00:43:39]Chris: Yeah, so I'm sure it's a giant compound. Yeah, so coming back to Brett Victor, so Brett did a whole bunch of research on user interface paradigms for kind of explaining how code works. And so he wrote up many different, it seems like a worry dream or something is his blog or something. And he has a whole bunch of like concept demos and things like this. And so it was super inspirational. And so a lot of what we were doing was saying, okay, well, can we get this actually out to people to actually use? And so that was a lot of fun. So Mojo doesn't have anything quite as cool like that yet. But we'll see. [00:44:13]Swyx: There's a whole community [00:44:13]Chris: of people building cool stuff. [00:44:15]Swyx: And a lot of people are saying, [00:44:15]Chris: oh, we should have UI libraries and stuff like this. And Mojo is not gonna build a UI library. But there's a lot of cool people on the internet that know how to do this well. And I'd love to see that. [00:44:25]Alessio: Let's list some of the known things about Mojo that people like. It's compiled instead of interpreter. There's like no global interpreter lock. The heap representation is different. Use MLIR. What are maybe some of your favorite or like most underrated things about Mojo that you haven't covered? Well, so I think that [00:44:43]Chris: there's two ways of looking at Mojo. Most common way is it's like a Python plus plus. Again, I've been working on this stuff [00:44:49]Swyx: for a long time. [00:44:49]Chris: It kind of been there before, right? And so if you look at Swift versus Objective-C, what Objective-C is, is it's this really interesting language that many people don't know anymore, but where you have effectively small talk, which has super dynamic objects combined with C, right? And so the way Objective-C worked in the first iPhone and Macs for years were all built with Objective-C. Is that the high-level libraries are all built with the super dynamic, you know, you could inject methods and override things and hack the class hierarchy and all this stuff, completely dynamic object model combined with C, which is really good at executing things efficiently, [00:45:25]Swyx: right? [00:45:25]Chris: And so one of the reasons that Objective-C scaled so well, for example, in the first iPhone, which was super CPU constrained, was that anytime performance was a problem, you could drop down to C. So in the case of Swift, what happened is we said, okay, well, we want to keep all the things that are good about Objective-C. So it has to be dynamic classes. You have to be able to do all this kind of stuff. We have to work with all of the Objective-C frameworks, but then we want to be able to make one thing that scales, so it's not two different worlds glued together. Python is the same thing as Objective-C, [00:45:53]Swyx: right? [00:45:54]Chris: But turn on its head, where instead of being objects and C, it's like what people think of as Python, like a very high-level dynamic, flexible programming model, but then it's also glued onto C for the execution layer, right? And so you look at something like NumPy has a very nice Python layer, or even TensorFlow or PyTorch, very nice Python layer, but underneath the covers, it's all C is C++. And so a lot of what we're doing in Mojo is, you know, we learned a lot from Swift and things like this, but it's kind of conceptually similar, where what you're doing is you're saying, cool, it's not about whether dynamics good or static is good. They're both good. They're good for different problems. So let's put them together in a consistent thing and allow you to reach for the right answer for a given problem instead of being religious about it, like dynamic typing is the right answer, right? Just say like, cool, dynamic typing is great. We can see all the benefits. A lot of people love this and it's super productive and expressive. But if you want better performance, you can reach for static typing, right? And so a lot of, I think what Mojo is, is it's progressive in terms of like, get out of arguing about stupid things that don't matter. Just let people solve problems, right? And I think that is hopefully what people see in it. Now, I mean, we can dive into other things. So Mojo learns from Rust, for example. Rust is a wonderful community with a lot of cool stuff going on. It's kind of hard to learn. And so can we take the type system innovations like lifetimes and features like that, pull them forward into a thing and make them easier to learn? If so, then we get a lot of the benefits of the safety and the other things that Rust gives and performance and all the good things, [00:47:24]Swyx: no garbage collector, [00:47:24]Chris: all the stuff that people love about Rust, do so in a way that's a lot easier to learn, right? [00:47:28]Swyx: And so it'll borrow a checker. [00:47:30]Chris: Do have a borrow checker. But one of the challenges with Rust is that, in my opinion, it's more cultural. I mean, there are definitely language design issues that antagonize it a little bit, but a lot of it is the culture, right? And so a lot of the culture of Rust is very much thou shalt borrow and expose references to everything. And the pervasive library model around Rust ends up being culturally very low level, but you could write much higher level libraries in Rust if you wanted to. And so what we're doing with Mojo is saying, okay, let's take the tech, let's fix some of the language issues [00:48:04]Swyx: and things like that, [00:48:04]Chris: but let's define a new culture. And so as we roll out new features and new enhancements into Mojo, you'll see more and more of that over time. [00:48:12]Alessio: — So one of the things that George Hotz talked about on the podcast is XLA is like a CISC and tanning dry is a risk. You built XLA, so... — Your response. — Exactly. We got the other side of the thing. What are your thoughts on that and what are the right trade-offs to make? [00:48:29]Chris: — Yeah, so I contributed to XLA. I didn't write the whole thing, but yeah. — And you worked on RISC. [00:48:34]Swyx: — Yeah. [00:48:35]Chris: Also, I love George. He's a very interesting person. He's very enthusiastic, and that's really cool. It seems like he's learning his first compiler, though, because what he's doing is he's building what's widely known as a tensor contraction compiler. And so he's identified one sub, sub, sub, sub, sub [00:48:53]Swyx: part of the problem, [00:48:53]Chris: which turns out to be really important, which is how do you express the matrix multiplications and stuff like this. And he's learning how to build a compiler for that. He doesn't care about performance, as he talked about, and performance is not great. And so he has different sets of goals. But what he's doing is he's reductively turning AI into a matmul, something that a polyhedral compiler or something like that would tackle. And that's cool. Been there, done that. The problem with that is it doesn't scale. It turns out that there are a lot of things in AI that are not just matmuls. And so one of the challenges that I predict he'll run into is when you get out to those problems, now suddenly you'll have two systems. Simplest example, this is like the data layer will be completely different, right? And so there'll be this interface. What happens when there's this phase change between how the system works? Is it easy to use? Is it composed? What happens? [00:49:45]Swyx: I don't know, right? [00:49:45]Chris: So George is a super smart guy. We'll see what he comes up with. The other thing I'd say is that he's very focused on building and learning and doing things in an opinionated way that he likes. He's not being super user-centric and meeting people where they are and trying to get and lift people and do the things they're already doing, but do them better. And so it'll be interesting to see if he gets a community of people that are actually building things that are kind of beyond his circle. But he's a very smart guy. And I think that some of the stuff he's doing will be really cool. And I think it's also really interesting because he's showing the world, like the Jaxx people, that you don't need all of PyTorch to build a framework. [00:50:21]Swyx: Right? [00:50:22]Chris: And so that truth, I think, is I think maybe two-sided because on the one hand, the tasteful subset of AI infra, however you want to look at that, is actually relatively small. But the complexity that you need to be able to integrate into a production system, deal with quantization, deal with all these things you actually need for really high performance, like really push the boundaries of what people are doing, that's where it gets hard. And so I have no way to predict where it'll go. But if you want to make a risk versus risk argument, well, it's risk until you want to do new things. And what he's identified as a subset of the problem that you can model in a very, very nice, beautiful way, which is known, but there's a lot of the rest of the problem. And so if you've compressed, you know, he talks about XLA having 150 ops, XLA could have a 10th of that. If you just said it's element-wise with an enum, which is kind of what he does. And so that's not really the right question. The right question is what can you express? And can you express a big enough part of the problem for it to be useful? And so, I don't know, we'll see where it goes. [00:51:24]Swyx: That's fascinating. Some good advice in there, I think, from engineer to engineer. Yeah, well, so, I mean, [00:51:29]Chris: but George's goal and my goal are very different. That's the important thing. It's like George's, he's building a thing to understand it. It's the best way. I mean, from what I understand, I haven't talked with George about this. And he wants it locally run transformers. [00:51:43]Swyx: Well, yeah, which is cool. [00:51:44]Chris: And I want that too. We'll talk about that in a few months, but so we have similar technical goals [00:51:51]Swyx: in some cases, right? [00:51:51]Chris: But the way he's approaching the problem is build a thing to learn it, right? And so he's very happy to talk about how he'll like rip the whole thing up and throw it away. And that's super awesome. He's building it like a research project. Like we're building it in a very different way saying, okay, we know that PyTorch is yucky in various ways or TensorFlow's made some unfortunate design decisions, [00:52:11]Swyx: right? [00:52:11]Chris: It's not about beauty. It's about pragmatism. Because when we talk to people, we say, hey, who here wants to rewrite all your code? Generally, not very many people raise their hand and people are willing to in certain cases and there are certain profiles. But if you look at where the majority of the market and where the community is, it's much smaller. Interesting. [00:52:28]Swyx: Well, you mentioned one of the operations that might be tricky is sort of the data layer. I don't know if I exactly understand what specifically is in the data layer, but I think memory constraints are something that people are talking about a lot. Recently, Georgi Griganov of GGML was showing off just the sheer amount of stuff that he can do on a single MacBook. And the analysis from Andrej Karpathy was mostly that it's just because it's memory-constrained, not compute-constrained. So even though you have a lot less compute on a single machine on Apple Silicon, it doesn't actually matter because you're just ultimately optimizing for token output. What memory-specific optimizations on the Mojo design side would you call out as important design choices? [00:53:10]Chris: Yeah, so I think that a lot of the on-device ML or on-device LLM work has really been around 4-bit quantization and 2-bit and 1-bit and things like this. You called them hacks, I think, on your... Okay. [00:53:22]Swyx: I don't think it's hacks. [00:53:24]Chris: I mean, I think it's funny, like if you want to nerd out about it, like a float 32 is a quantized representation of infinite precision floating point numbers, right? You only have 32 bits to be able to represent all of numerics, right? That's a pretty flexible and useful hack, right, from that perspective. So I'm not here to tell you that there's one right way to run a neural network. I want to make it as easy as possible to be able to explore and research and try new things. And if it works well for you, great. The challenge I have with like the 4-bit numeric stuff and with quantization in general is that the way these things are implemented are hacks. And so often it is very hard-coded kernels. So GGML, wonderful project, lots of really cool and smart people working on this. The kernel libraries are very specific, individual things that are available in very hard-coded ways and they don't compose correctly. You know, you want to walk up to it with a novel model, right? GGML requires a lot of rework before you can do that. And not lots of people know C++ that do this stuff. And so anyways, my goal and my quest is to massively reduce that complexity. Within quantization, here's the thing I'll give you to think about, right? So autofusing compilers are better for performance, memory, and accuracy. And the reason for that is that if you're using autofusion, avoiding go-out-to-memory, good for performance. Automatic is better than manual, so it's good for humans that don't have the attention span to do this. But with quantization, it's really interesting because the way you normally implement a quantized operation is that you have higher internal precision than you do the external precision, right? And so if you write out an activation in memory, you have to re-quantize down to eight bits. But often what you'll end up doing is, or take Flute 16 or something, right? The internal activation, or the internal arithmetic is done as Flute 32. Load from memory, and you do like a multiplication of two Flute 16 things and you get a Flute 32 intermediate result. And so in the CPU or in the GPU, in registers, you have higher precision. So now when you do autofusion, you keep things in the higher precision, and so you have less intermediate rounding. And so when you take a big attention block and you do quantized fusion, you actually get, yes, much more flexibility because you can fuse much bigger regions than people can do by hand. You get better performance because you're not writing things out, but you also get better accuracy. And so that's one of the things that, again, [00:55:46]Swyx: That's a free lunch. [00:55:47]Chris: That's pretty great, right? And so, and also you go back to the complexity and the pain and suffering and the, you know, a lot of what Modular's trying to do is reduce suffering in the world. A lot of the quantization tools are just really bad. And it's because, you know, they have this like unmovable kernel library that has a whole bunch of special important cases and they're trying to like pattern match onto it. And so they often have very flaky problems and it's just a huge pain in the butt. And so by solving some of that low-level compiler nerdery, right, it enables you to have better tools, better accuracy, like all these things actually stack out and just leads to better technology. And then is 4-bit the right answer? I mean, 4-bit's cool, 2-bit's cool. All this stuff is cool, right? I mean, I think that there, it really depends on your application or use case. And so allowing people to play with that, that cannot write the kernels, like that's the whole point. [00:56:35]Swyx: Yeah, they can still quantize, but using your approach, like it's just orthogonal. It's just going to be a straight improvement either way. So, yeah. [00:56:41]Chris: Right, exactly. [00:56:42]Alessio: There's still so much we're figuring out, right? The mixture of experts thing, like a few months ago, like people were not really thinking about, then George kind of leaked it on the podcast. Alerted it on our pod. Yeah, and then people started talking about it. A few other people confirmed it, yeah. [00:56:56]Chris: Yeah, yeah, yeah, exactly. [00:56:57]Alessio: As all these people started talking about it, I was like, I didn't say it. Please don't call me Sam Ullman. Speculative execution is another one. Basically, like Karpathy's thing is like, hey, if you're trying to get one token, getting K token in batch is almost the same time. I'm sure Mojo is great for that because it's not single-threaded like Python. You can run parallel. [00:57:18]Chris: So one of the funny things about this is that you've all been in space for a while. It used to be back in the day, ResNet-50 or something, or MNIST, right? What is a neural network? It's machine learning operators, right? Then reinforcement learning came on the scene, right? And now suddenly you're saying an inference ends up being part of the thing the agent does. And then I have a training job that's driving this thing. And now a big RL system ends up being this massively complicated distributed system where you have traditional AI infra lashed together with all this Python and stuff like this. You come back to like stable diffusion with the units, you go look at yield LLM implementation, all the tokenization stuff's in Python. It's super funny when you look at this because what the world is telling us is that this AI infra, these systems are not flexible enough. And so why do you have to do the tokenization in Python? It's because the data layers, the libraries that people build in this stuff are not programmable and you need flexibility. And so people do this. And by putting this stuff into Python, I mean, it's great and I understand that, or rewriting into C++ to deploy it, right? What ends up happening is you lose the ability to do things like PMAP because the graph, the underlying ML model is a declarative specification of compute. But if you can't represent your computation, then you can't transform it, right? And so one of the real purposes of Mojo and the way it integrates with the engine and stuff like this is to give you the best of both worlds where you can say, cool, I can have full programmability. I can write a completely custom tokenization layer or whatever it is I want to do. Or if I have a really compressed on-disk format or I want three bit, whatever the thing is, I can express that. But now it composes into the stack instead of it being a bolt-on on the side that doesn't work well. I've seen the consequence of not building this stuff. And what it does is it drives all this complexity into the system. Or you look at serving layers. There's these platforms like SageMaker, for example. SageMaker is a very popular hosting solution for doing inference on models. But it's really just a TensorFlow or PyTorch that's wrapped up, right? And so sure, you can give it a TensorFlow graph and say, go ahead and serve my TensorFlow graph. But what if you want some pre-processing? Well, you have to set up a microservice next to it, right? And so now you have all this data going in and out over the network just to do one summarization operator before you send something out to the mobile client that you're talking to or something, right? And so the consequence of these design points drives a huge amount of this external complexity into the systems. It just doesn't need to be there. If you do the hard work, it doesn't need to be there if you do all the hard work of first-printing this stuff. [00:59:50]Alessio: What about the post-transformer world? I think we kind of touched about this. And when you have faster transformer and all these things, it's so easy to just do another transformer model. We just did our WKB episode with Eugene Cha. What do you think about transformer alternatives and how closely are you working with some of these groups as you develop modular? [01:00:12]Chris: Yeah, so we're great friends with Chris Ray's research group, and he's pushing on the hyena models with FFTs and things like this. And so I'm not smart enough to know the right thing there, honestly. My take on that is that there's a lot of smart people. I have a hard time believing transformers are the last major macro architecture that will be invented. And so what I'd love to do is enable more people to be able to play with this stuff. I often get asked of, why does anybody care about AI and for if transformers have solved it? It's a super funny question, because the basic assumption there, which is not wrong, the basic assumption is that transformers have eaten everything. They've eaten so much of vision transformers and everything else. They've eaten all the modalities. Therefore, in the fullness of time, they'll eat everything. But the funny thing about that is that that's a very narrow view of, again, what is AI? Because AI also includes massive recommender models where you have huge embeddings and these big, dense matrix multiplications. It also includes the units and things like this. It also kind of ignores the fact that transformers, as a category, there's a lot of consistency and we still have softmax. But if you go back to the first paper, the modern transformer is actually quite different. And so, yes, there's a lot of really good ideas about attention and things like this. But the evolution of this over time has really refined the approaches and a lot of the activation functions have changed. And a lot of stuff and a lot of innovation is still happening in this field. So, I mean, is it FFTs or is it attention? I defer to smarter people that know that stack better. But what I'd love for them to be able to do is not be held back by the architectures of the systems that were massively over-optimized just for attention. – What else should people be on the lookout for modular? [01:01:50]Alessio: So you just released yesterday Mojo download on Linux systems. You have macOS and Windows coming out soon. What are, say, like six, nine months from now, I don't know how much you can share, what is going to be the toolkit? So there's kind of like modular is the engine, Mojo is like the language. What are going to be the other components that people can leverage? – Yeah, yeah. [01:02:08]Chris: As we record, just yesterday, we announced download support for Linux. I've heard of Macs and Apple platforms. Turns out CI is kind of annoying with them. And so, yes, we'll roll out that kind of stuff. So roll out new platforms, of course. One of the things we're, and within Mojo, Mojo is still a young language. And so we have traits coming, hopefully by the end of the year. We have a bunch of things like that that'll be really a big deal for library design and enable new kinds of things to be expressed cleanly. Mojo will mature, right? And so I think that this is a major thing that we're focused on, is actually building Mojo in the right way. And that'll be super exciting. One of the consequences of that is we want a big community around Mojo to build cool stuff. And so as part of building in towards this, we'll start open sourcing Mojo. I think that's something that'll be really great. We just want to make sure that we do it. And again, if we do anything, we want to do it the best possible way. So we want to figure out what is the right contribution model and all this kind of stuff. We want a permissive license. And so we have to nail down a lot of the details to kind of go into this stuff. Because again, we want to be able to build something that works well and have a whole bunch of people that work well together and not just a gigantic, catastrophic mess. [01:03:14]Alessio: Yeah, there's kind of like the Python 2-3 mess that we all got through and nobody wants to remember about it. What's kind of the relationship with Guido and the Python Foundation? And because some of the Mojo stuff is like, this is so good, why isn't it in Python 2? You know, long-term, how are you planning to keep kind of like the two languages in sync? And how are you involved with each other, so to speak? [01:03:38]Chris: Yeah, so Guido for quite some time, from before the launch. And so he's known about Mojo as it's coming. We've been very fortunate. He spent a bunch of time with our team [01:03:47]Swyx: and things like this. [01:03:47]Chris: He occasionally shows up on Discord and gives me a hard time about things. So that's super awesome. [01:03:52]Swyx: What is his pet topic? [01:03:53]Chris: I think that he enjoys trolling us. And so, which I also enjoy. So it's all good. And so like there's Guido himself, then there's a broader question of Python. I consider Mojo to be a member of the Python family. And so there's a number of members of the Python family, by the way, including things like PyPy and Cython and like all this stuff. And so we want to be a good member of the Python family. And what I expect is that Python will continue to evolve and add new stuff. Mojo will continue to evolve and add new stuff, right? And so the analogy I give to people is to go way back 30, 40 years ago, there was C, and then this newcomer came on the scene in 1983 or something called C++, right? And what was C++? Well, it was C with classes, right? And so Python with not just classes, but all the stuff underneath it that you usually do in C, right? And so what happened back in the day is that C and C++ started as two different communities, but there's tons of intermixing and idea sharing and interpollination of ideas. And a lot of the C++ features ended up in C. And then of course, all the C features ended up in C++. And so I expect that same thing to happen. And so I look at it as Python 3 versus Mojo. Python 3 is really defined by its runtime. It's defined by a specific object model. And it really, I mean, if the Python community wants to change that, that would be really interesting. But Mojo is saying, okay, it's defined by a superset of the expressive capability. And so we have fancy MLIR compilers [01:05:21]Swyx: and things like this. [01:05:21]Chris: And so we can have on-stack representations and things that kind of lead to relatives of each other. And I'd like for Mojo to be a superset, right? In terms of all the capabilities. But each of these things will evolve in parallel. You know, I consider, you know, when people come to me and they say, hey, I want like this crazy feature, which should be in Python. I say, great, go talk to Python. We're here to add the systems programming features. We're not here to just add a general, you know, Walrus 2 operator or something. Ooh, that still burns a little bit. [01:05:49]Swyx: But, you know, Python actually did end up adding no-gill after, like, not long after. Well, they haven't added it yet, but there's been discussion about it. Well, also, yeah, I mean, [01:05:58]Chris: I think the gill stuff is also going to be super interesting. They have a five-year journey to add this. And so it's going to be technically very complicated for the community because one of the most beautiful things and pragmatic things about Python is that you drop right down in C. And so much of the Python ecosystem is actually C libraries or C++ or et cetera, right? But then are wrapped by Python, right? But one of the things the no-gill stuff breaks is it breaks a bunch of that glue. And so, like, the ability to get and set attributes, all the C functions for doing that break, right? And so that's going to cause a lot of churn and complexity. And so I'm not involved in the effort, obviously, but from what I can see, the Python community seems like they're walking into this with eyes wide open. Oh, yeah. They understand the trade-offs. I think they're doing a really, like, well-thought-out approach to this. And so I think that it will probably go really well. Now, that's great also, by the way, because Mojo likes threads, because threads are a thing, right? And so this will make it so that the Python ecosystem is more concurrent compatible, which will be great for us. [01:07:00]Swyx: Yeah, but you're already there, so. [01:07:02]Chris: Yeah, exactly. I mean, again, first principle learning something, it's not like, you know, multi-cores of the future anymore, right? Yeah, yeah. [01:07:08]Swyx: One thing you're doing differently than beyond, in terms of, you know, C, C++, and then, you know, Python, Python++, is that you're choosing to build this as a company. Why a company and not a foundation? I think you kind of answered that with the modular first. [01:07:19]Chris: Yeah, so we didn't start modular to build Mojo. We started modular to solve some AI problems, and then said, okay, well, we need to do a language. So I'll reinterpret your question, if it's okay, as saying, why is modular an independent company instead of part of a big tech? Apple or Google or Microsoft or whatever. So there's a number of reasons. Well, so first of all, I'll say, we tried. We collectively, I'll speak on behalf of all of our, the people on our team. Many of us came from big tech. Yeah. Like I worked at Google. I worked on ML infrastructure at Google, right? Literally working on this problem. And many of our people came out of this context. And the challenge, again, these companies are amazing, right? This isn't to bag on big tech. The challenge is, AI infra is not their product, right? So when I was working on XLA for TPUs, when I was working on XLA, it was to enable TPUs. It wasn't some abstract, let's go solve programming model and hardware and this big problem. It was literally enable this hardware because we just installed exaflops of it, and we needed to get to go and work, right? When you look at what is TensorFlow, it's, by the way, part of the cloud organization within Google. So if you want help with TensorFlow, sign up for GCP, and then they can help you, right? What is their product? Then Meta, right? I mean, what are they trying to solve? Well, they're trying to solve their ad stuff. [01:08:34]Swyx: Meta has never had any interest in, yeah, external facing developer stuff. But Microsoft would have had you, like Satya has, you know. [01:08:40]Chris: Yeah, I wouldn't go so far to say that none of these people care. All these people care. And there's so many good engineers within the PyTorch team that care about external developers. But the way to think about this is that all these projects are more of like a hobby than they are the company project, right? And so that difference is actually really important. Like, I mean, if you file a bug against Meta or a bug against PyTorch, you have a bunch of really good engineers that are allowed to work on that, and they want their product to be good. And so they might fix it, but also they might not, right? When we talk to people, not everybody in AI trusts Meta and Google. Often they're directly competing with them, right? And so like, no, I'm not going to actually show you my model so that you can debug the problem. They're conflicted in lots of different ways. And so with Modular as a standalone company, it's super important to us that we're neutral. We're like Switzerland, right? We do not build hardware. We do not have a cloud. We are not building an LLM, right? And so what we're doing is we're building AI Infra in a way that is really good so that you all can go invent all this other stuff and you have the right tools to do it, and we're not competing with you, right? And so that is something that, you know, again, there's lots of really good people, all my friends, you know, in all these different places, right? It's not the engineers or the management is doing anything wrong. It's just that what is their core incentive structure? What do the engineers get promoted for doing? And these things that, you know, actually they're more incentive oriented than they are technically oriented [01:10:08]Swyx: end up mattering a lot. [01:10:08]Chris: And this is one of the reasons why at a hardware company, you're not incentivized to build software that runs on lots of different kinds of hardware, obviously, right? Within Google, you're not incentivized to build things that work great for PyTorch. You know, so there's this problem where the rest of the world is building on AI. They use TensorFlow and PyTorch and lots of hardware and lots of clouds and lots of stuff. And so being able to help people and be aligned with their interests is really useful. [01:10:31]Swyx: One thing I wanted to come back on, you said you don't have a cloud, but the way that people would use the modular inference engine is through your cloud. [01:10:39]Chris: You have cloud engineers. [01:10:40]Swyx: We do have cloud engineers. [01:10:41]Chris: Actually, the way our product gets used is you use it on your cloud. And so we give you roughly a Docker container, and so it can run on cloud, on-prem, on laptops. We have folks using all kinds of different things. And so it's very modular that way. So we'll also build into a hosted product, of course, over time, just out of convenience. A lot of people don't want to do the management themselves, but we're really focused on meet people where they are, right? And we believe that our tech gets adopted faster if it's easy to adopt and easy to use and saying, okay, first move all your stuff to our cloud. [01:11:14]Swyx: It's a valuable thing, [01:11:15]Chris: particularly for people who don't want to manage that, but it just slows down adoption. [01:11:18]Swyx: So a bit more company origin story stuff, because I just love company origin story type things. Your co-founder is Tim Davis, who you've worked with for a while. He's also had a couple of other startups under his belt. You get the idea for modular at SciFive, and you talked to the big clouds, and they didn't really want it, or you just arrived at the conclusion that it wouldn't be the best place for it. How did you go about founding the company? Yeah, good question. [01:11:40]Chris: So I've been working on this stuff since 2016, 2017, right? So I've been working on AI and for of different points. So Tesla doing applied. How do we make cars drive themselves? At Google, bringing up a hardware program and trying to get TensorFlow to be architected better, let's say. Then I was dissatisfied for various reasons with what was going on at Google and with not taking PyTorch seriously and things like that. And so I went and joined a hardware startup. When I did that, I really wanted to solve this problem, but the timing that was in 2020, which was right before the pandemic, by the way, it wasn't right, right? Because at that time, there's still a lot of things were unknown. PyTorch was still figuring stuff out, and they had a lot of very ambitious projects. And at the time, I'm like, okay, well, I assume that Meta will go off and solve these problems, right? And so I joined a hardware startup to understand the other side, the business strategy, the commercial side of things, how the company building side of things and all this kind of stuff, learned a ton. Also that I'm a software person, not a hardware person, but Tim was going through his own journey. And so Tim joined Google Brain roughly the same time I did in 2017. We worked together very closely. I was on the data center TPU side. He was on the mobile side with Android and all that kind of stuff. I was engineering, he was product. We were very complimentary that whole time. He stayed at Google through all that time until about 2020 and to 2021 through 2021. And so we kind of got to the points in our journey where we're saying, okay, well, what are we going to do next? And so middle of 2021, we said, okay, well, this AI infra problem is still a thing. This is, in our opinion, was not getting fixed. We looked at this and said, okay, well, what are the problems in the space? A reductive way of asking the question is you say, if AI is so important to the world, this was before chat GPT, but AI was important before chat GPT, by the way. If it's so important to the world, why is all the software so bad? Why is it so hard to deploy a model? I mean, we did huge amounts of work to make it easy to train models, but getting them into production is still very, very challenging. And so what we did is we broke this all down and we said, okay, well, there's really three kinds of software in the world. There's the hardware specific software. So CUDA or the XLA stack or the Apple neural engine stack with Core ML, things like this. And it's not the hardware people's fault, but they have to build this vertical software stack for their hardware because there's nothing to plug into. There's no LLVM for machine learning, right? And as a consequence of doing that, and they're not malicious, but they end up fragmenting the universe because they all have to build different stuff. Okay, so that's one third of the software in AI. Another third is the frameworks. So you've got TensorFlow, you got PyTorch, you got TVM, you got like all this stuff out there. All these things were, you know, they're eight years old. The infrastructure itself was research, right? These things were built in a different era of what ML was, and they got evolved along the way and new hardware and new use cases and all this stuff. And they were never intentionally designed by, you know, from what we know now. Furthermore, often because AI was so important to their host companies, hundreds of people got thrown at it, right? And so I don't know how much money has been spent on TensorFlow or PyTorch, but it's a lot, right? And so you get all these people that are kind of hacking away in the combination of lots of hands and not a lot of clear vision. I mean, it's easier to understand in hindsight than it is to predict what AI will look like in five years, right? It means that it will generate a lot of stuff, which is maybe not the most clean architecture, right? And so we get these systems that have lots of well-known problems. And so PyTorch, for example, it's pretty difficult to deploy. It's pretty well-known. It doesn't really work great with lots of non-NVIDIA hardware, right? It doesn't scale super well for LLMs. These things are pretty well-known, but they're very difficult fundamentally to fix. And the PyTorch engineers are doing really great work. They're working hard on this, but it's really hard to fix given the environment that they're in. And so because you've got the hardware side of things that's fragmenting software, you've got the framework side that is, you know, they're tied to the architecture that they started with and things evolved. What we've got is we've got a lot of people who want to make AI easy. And so MLOps is this category that evolved. And what I think a lot of these folks tried to do is they said, hey, let's make it easy by making the API super simple. So AutoML, one example of this, maybe the most extreme, but lots of other people said, hey, I'm going to add a layer of Python on top of this gigantic mess, and that will make it easy to do AI. But the challenge is you can't solve programmability or performance or hardware capabilities or new kinds of algorithms or like security, like these core problem deployability, these core problems that people are struggling with by adding a layer of Python on top, at least not without giving up the mad joy of like all the craziness of AI research. Right? And so what we decided to do is we said, okay, well, let's go back and first principles this thing, like what is causing all of this madness? Well, it's because there's no thing for people to plug into. Let's go do that hard thing. Let's go build from the bottom up. One of our first blog posts was, you know, it's before we could say what we were doing. It's like the mission statement of what let's actually design and first principles of stuff. Let's build this unifying platform. Let's tackle the hard problem. And so that's what we decided to do. [01:16:47]Alessio: At Decibel, our team is kind of like early believers and technical founders. And we see a lot of founders like yourself. You have a very long career. It's like an amazing engineer. And then all of a sudden you're like in the CEO seat. What are some of the learnings that you've had building a team, mentoring people, especially when I'm sure a lot of your work has been mentoring engineer, and now it's like also having the product head, also having the fundraising head, any stories and learnings? [01:17:13]Chris: So at Modular, my co-founder, Tim and I, we're like two in a box, right? So one of the things that I think is really special is that we have a very strong relationship and we complement each other very well, yin and yang, right? And so having somebody to talk to is really, really important. And it's not something that I've had being engineering leader at Google or engineering leader at Apple or something like this. And so that I think is super special. I'll also say that, you know, I've built many teams, many products and technologies. And so I built all this kind of stuff, but it's always within somebody else's context. And so it's really nice to not have to clean up somebody else's mess, right? [01:17:46]Swyx: Well, it's your mess now. Yeah, exactly. [01:17:48]Chris: And so also you get to, again, you get a first principles of everything. Like how do we think about comp? How do we think about, you know, a lot of the philosophy at Modular was, okay, well, you know, our belief when we started the company was we understood the pain. I'll speak on behalf of Tim. Tim understood the pain with his Google hat on, right? And he worked with a lot of customers outside and things like this, but having a Google hat on is very different than having a startup hat on, right? And so when we started the company, we started and said, okay, well, Chris goes and engineering leader, go start building the thing and build the engineering team and all that kind of stuff. Tim goes and builds the product side and the business side and things like this and goes and interviews 50 or 100 different companies without a Google hat on. What is your pain point? What are you doing? What are your challenges? How can we help? We're thinking about building X. What do you think about that? And really hone the vision. And that's what allowed us to come back together. And so the challenging things about being Modulars, we're trying to build something that is really hard. It's a super hard tech problem. Also pretty abstract. I mean, it's getting less abstract now that it's working and it's all coming together and we can announce things, right? But solving this problem requires hiring these very expensive specialists out of all these big tech companies, right? And so that really formed and shaped a lot of our initial conditions, how we thought about things. And again, when you're first principaling this, you say, okay, well, because of that, I have to raise a lot of money. I have to be able to incentivize people well. I have to be able to pay them. I need to be able to make it comfortable, like make it so that they're not fish out of water. And a lot of that shapes how you do this stuff. And so I've really enjoyed it. I think that it's a lot of fun. It's also great because we can do things where, you know, you come back to, is TensorFlow or PyTorch a product? I would say no, but I'd also say self-reflectively, many of the things I've worked on for like Swift, for example, right? Or even Xcode are products in the sense of they are, there's a product manager and there's a team that works on it and that you ship it to customers, but it is not the core product of the company. Xcode is a loss center, right? Apple doesn't make money on it. It is because it is detached. It's kind of one level indirect from the customer, right? It's very easy for that team or for a support team like that or like the TensorFlow or the PyTorch team equivalently to go work on interesting technical projects that get very divorced from the customer because you don't really know what they're doing. And so for us, we're directly customer facing, right? We see the pain. And in AI, as I think you probably know, right? There's a lot of pain and building and deploying these things is really a mess. And sure, throw a layer of Python on top, you can make a demo simple, right? But a lot of the pain that the leading companies and the leading people that are building these things are facing are not that kind of a problem. It's that they're surrounded by too many things that don't really work, right? And so a lot of our vision on let's go unify all this stuff. Let's have fewer things that work better came directly out of talking to teams that their problem is that they're building a product and their product changes. They're not using one model. Their needs over time evolve. And okay, well, now we have a mobile product. Well, now what does that mean? That's a completely different universe, right? And so what ends up happening with the teams we work with is that they're often quite sophisticated and they've evolved lots of different messy systems for different special cases and it's killing them, right? And so they often want to just be able to run faster, right? Do I need a team of 50 engineers to deploy this model? Why do I need that? [01:21:09]Swyx: I was also curious about your learnings as an engineering leader. So you've just had tons of experience building teams and hiring engineers. Obviously people want to work with you naturally. So you just naturally get a buff. Oh yeah, so it's easy, right? What is your learnings or advice or just on the engineering management side of things? [01:21:26]Chris: Yeah, so I mean, I think there's different things. I consider my job is to help the team win, right? So I do what it takes to win. And you have to be like, starting from wanting to win is actually something that some people take for granted, right? And so you have to define what winning is. And so giving people a clear vision, having a clear purpose, keeping people aligned, super, super important when you've got a whole bunch of really good people that are all wanting to be heroes in their own journey, right? If the vectors add up, you can make a lot of progress really fast. If they're pointing against each other, they cancel out, right? Within, you know, because of who I am and what I like to do, like I will often help build the initial foundation of the thing myself. And so showing the team how to build things is really good for not just like, because I built a lot of this stuff before, like directly contribute, but also saying the culture. So one of the things that is really important to me in an engineering team is how fast can you spin, right? If you're sitting there and you have to wait 24 hours or three weeks for CI to run, well, it just slows everything down, right? And so, well, what does that mean? Well, it means testing strategy. It means like all of these things are just like core software engineering problems end up mattering a lot. And once you get a culture in there, like, you know, low dependencies, like do not just suck in third-party dependencies and hope it'll be great. Because there's lots of these things that kind of come into this. And then what you end up doing is you end up building a culture within the team. Now, when you do that, now you have really good people. You have to identify first when you're hiring, but also as people are evolving, like what are people good at, right? And I really believe that if you have a really powerful engineer, for example, or product manager or whatever, [01:23:01]Swyx: if they're really good, [01:23:01]Chris: you can throw them at any problem and they can make progress, right? But if you have somebody who's really good and really passionate and you line them up with something they really want to be doing, well, then they'll have superpowers, right? And so a lot of it is making sure people are working on the right problems. And so they're able to grow and do things and push and they have agency to own decisions and they're able to do things. And so it's kind of like this ongoing, like evolving dance, particularly in a high growth team, where what you're doing is you're looking for not just what are the lines of code you write, but also what are you contributing, right? And things like this. And so there's a lot of building a team that I'm not the guy that's going to write a management textbook or something like that, right? I mean, you should. I should probably write a compiler textbook first. [01:23:47]Swyx: Yeah, you have many contributions. [01:23:50]Chris: I like building the thing, unfortunately. And so I don't slow down for stuff like that. But a lot of it is, people get very focused on often the product or if they're really, really smart and they're good at business, they focus on the customer and the problems the customer has, right? But you can't solve and build the product without having the team. And so, so much of these things end up being these virtuous loops. And so thinking about all parts of those problems, I think is really an important part of being a leader and being a team. And again, this is one of the reasons I love Tim [01:24:21]Swyx: and love working with him [01:24:21]Chris: because he's really great at ways that I'm less great at and we're both learning from each other. Before we do landing ground, [01:24:27]Alessio: any people that should be joining your team, any role that you have open that you're looking for? [01:24:32]Chris: We are growing quite a bit. We are focused on a whole bunch of different things, including hardware, software boundary. And so if you're a kernel engineer, you care about performance, GPUs and like all the weird things that are out there, right? This is a major focus. We are not hiring researchers, but we really love applied people that like actually get a model to work in production and do things. And that's really great for us. We have a lot of customer engagements and things like that going on that can be very helpful and valuable with that. We're also growing out our go-to-market team and there's many different kinds of roles. You can check out our career page and we have a number of positions posted there. [01:25:06]Swyx: Awesome. [01:25:07]Alessio: So we have our usual three questions before wrapping up. One is on acceleration, one is on exploration, and then I'll take it away. So the acceleration one is, what's something that already happened in AI that you thought would take much longer to be here? [01:25:21]Chris: So the chat GPT explosion, I thought was super interesting, right? And for folks like us that have been paying attention to AI for a long time, chat GPT was super interesting to me because it was a user interface innovation. And chat GPT happened and then GPT-4 happened and the world generally didn't even notice GPT-4. Nerds like us did, right? But they had no idea, they don't care. Chat GPT was the thing that really got people excited and it was really, you know, RLHF, like, I mean, that goes into all this stuff, right? But it was really about the user interface and how they use it. And suddenly it opened people's minds to the power of what AI can do. And so I thought that was super interesting. And from a looking backwards perspective, I thought that brought AI forward in the public consciousness by several years, I think. [01:26:10]Swyx: I always say you want to combine model with modality. Like chat GPT, you know, we had Clippy before and Clippy never took off. But anyway, so the time was right. What do you think is the most interesting unsolved question in AI? Maybe not the one you're tackling. [01:26:24]Chris: There's lots of smart people with lots of different opinions about what AI is, right? And there are certain people that you know, and I know that think that everything just be an end-to-end neural net and software should go away, right? I think that the open question is, what is the balance between trained algorithms and intelligently designed algorithms? I do not believe personally that it is all one or all the other, right? And if you want to build a cat detector, then a CNN is a really good way to do that. If you want to write a bootloader or an operating system, then for loops are a good way to do that, right? But where do things phase out over time and how do we make it so that app developers can think about these things more consistently instead of thinking about them as, you know, category A versus category B, right? And I mean, part of my bet is that AI as a software development approach ends up being, you know, part of the tool set of how people think about building applications. You know, where applications are not just like an iPhone app or something like that, but it's your cloud services, your data pipeline. It's like this whole complicated dance that leads to building a user product, right? And so I think that we as an industry haven't yet figured that out, right? I mean, it's just so early. AI is like in its adolescent years right now. [01:27:35]Alessio: It's funny because like doing this podcast, we're like, oh, remember that? And then you look at the timestamp and it was like three months ago. Exactly. You know, it's kind of you look back and it's like, oh, it's not even one year since JGBT came out, you know? And we went from like no AI safety discourse, for example, to like AI is going to end the world. Then it's like, all we did was I put a chat online, you know, so it kind of makes you wonder. [01:27:58]Chris: And I'll admit, like in 2017, there was a bunch of people focused on safety. And I'm like, why does this matter? Right? And they were just ahead of their time. Now it's pretty clear. [01:28:06]Swyx: Yeah, exactly. [01:28:06]Chris: That's exactly right. [01:28:07]Swyx: They took it seriously when the rest of us were only looking at the math. Yeah. [01:28:11]Chris: Well, and that's one of the things I really love about some of the OG people like Jeff Hinton and some of these folks like Jan Leku because they were into AI before it was cool, right? They were working on this stuff before it was obvious to everyone. And I think that they have seen and can integrate across a much longer timeframe. And that the wisdom that comes out of that, I think enables them to do even today, really amazing things that they get that better perspective for. [01:28:36]Alessio: Awesome. Before we wrap, Chris, any final takeaway message that you want everybody to think about and remember? [01:28:43]Chris: No, I mean, thank you for having me. I mean, this is a lot of fun and I really love being able to talk at a much more technical level about the AI part of what we're doing. And so I'm just so excited about where things are, what's happening, what the world's building, like just everything about what's happening right now is just super exciting to me. Awesome. [01:29:01]Alessio: Thank you so much, Chris. [01:29:02]Swyx: Thank you. [01:29:02] Get full access to Latent Space at www.latent.space/subscribe
Thu, September 14, 2023

The Point of LangChain — with Harrison Chase of LangChain
As alluded to on the pod, LangChain has just launched LangChain Hub: “the go-to place for developers to discover new use cases and polished prompts.” It’s available to everyone with a LangSmith account, no invite code necessary. Check it out!In 2023, LangChain has speedrun the race from 2:00 to 4:00 to 7:00 Silicon Valley Time. From the back to back $10m Benchmark seed and (rumored) $20-25m Sequoia Series A in April, to back to back critiques of “LangChain is Pointless” and “The Problem with LangChain” in July, to teaching with Andrew Ng and keynoting at basically every AI conference this fall (including ours), it has been an extreme rollercoaster for Harrison and his growing team creating one of the most popular (>60k stars at time of writing) building blocks for AI Engineers.LangChain’s OriginsThe first commit to LangChain shows its humble origins as a light wrapper around Python’s formatter.format for prompt templating. But as Harrison tells the story, even his first experience with text-davinci-002 in early 2022 was focused on chatting with data from their internal company Notion and Slack, what is now known as Retrieval Augmented Generation (RAG). As the Generative AI meetup scene came to life post Stable Diffusion, Harrison saw a need for common abstractions for what people were building with text LLMs at the time:* LLM Math, aka Riley Goodside’s “You Can’t Do Math” REPL-in-the-loop (PR #8)* Self-Ask With Search, Ofir Press’ agent pattern (PR #9) (later ReAct, PR #24)* NatBot, Nat Friedman’s browser controlling agent (PR #18)* Adapters for OpenAI, Cohere, and HuggingFaceHubAll this was built and launched in a few days from Oct 16-25, 2022. Turning research ideas/exciting usecases into software quickly and often has been in the LangChain DNA from Day 1 and likely a big driver of LangChain’s success, to date amassing the largest community of AI Engineers and being the default launch framework for every big name from Nvidia to OpenAI:Dancing with GiantsBut AI Engineering is built atop of constantly moving tectonic shifts: * ChatGPT launched in November (“The Day the AGI Was Born”) and the API released in March. Before the ChatGPT API, OpenAI did not have a chat endpoint. In order to build a chatbot with history, you had to make sure to chain all messages and prompt for completion. LangChain made it easy to do that out of the box, which was a huge driver of usage. * Today, OpenAI has gone all-in on the chat API and is deprecating the old completions models, essentially baking in the chat pattern as the default way most engineers should interact with LLMs… and reducing (but not eliminating) the value of ConversationChains.* And there have been more updates since: Plugins released in API form as Functions in June (one of our top pods ever… reducing but not eliminating the value of OutputParsers) and Finetuning in August (arguably reducing some need for Retrieval and Prompt tooling). With each update, OpenAI and other frontier model labs realign the roadmaps of this nascent industry, and Harrison credits the modular design of LangChain in staying relevant. LangChain has not been merely responsive either: LangChain added Agents in November, well before they became the hottest topic of the AI Summer, and now Agents feature as one of LangChain’s top two usecases. LangChain’s problem for podcasters and newcomers alike is its sheer scope - it is the world’s most complete AI framework, but it also has a sprawling surface area that is difficult to fully grasp or document in one sitting. This means it’s time for the trademark Latent Space move (ChatGPT, GPT4, Auto-GPT, and Code Interpreter Advanced Data Analysis GPT4.5): the executive summary!What is LangChain?As Harrison explains, LangChain is an open source framework for building context-aware reasoning applications, available in Python and JS/TS.It launched in Oct 2022 with the central value proposition of “composability”, aka the idea that every AI engineer will want to switch LLMs, and combine LLMs with other things into “chains”, using a flexible interface that can be saved via a schema.Today, LangChain’s principal offerings can be grouped as:* Components: isolated modules/abstractions* Model I/O* Models (for LLM/Chat/Embeddings, from OpenAI, Anthropic, Cohere, etc)* Prompts (Templates, ExampleSelectors, OutputParsers)* Retrieval (revised and reintroduced in March)* Document Loaders (eg from CSV, JSON, Markdown, PDF)* Text Splitters (15+ various strategies for chunking text to fit token limits)* Retrievers (generic interface for turning an unstructed query into a set of documents - for self-querying, contextual compression, ensembling)* Vector Stores (retrievers that search by similarity of embeddings)* Indexers (sync documents from any source into a vector store without duplication)* Memory (for long running chats, whether a simple Buffer, Knowledge Graph, Summary, or Vector Store)* Use-Cases: compositions of Components* Chains: combining a PromptTemplate, LLM Model and optional OutputParser* with Router, Sequential, and Transform Chains for advanced usecases* savable, sharable schemas that can be loaded from LangChainHub* Agents: a chain that has access to a suite of tools, of nondeterministic length because the LLM is used as a reasoning engine to determine which actions to take and in which order. Notable 100LOC explainer here.* Tools (interfaces that an agent can use to interact with the world - preset list here. Includes things like ChatGPT plugins, Google Search, WolframAlpha. Groups of tools are bundled up as toolkits)* AgentExecutor (the agent runtime, basically the while loop, with support for controls, timeouts, memory sharing, etc)* LangChain has also added a Callbacks system for instrumenting each stage of LLM, Chain, and Agent calls (which enables LangSmith, LangChain’s first cloud product), and most recently an Expression Language, a declarative way to compose chains.LangChain the company incorporated in January 2023, announced their seed round in April, and launched LangSmith in July. At time of writing, the company has 93k followers, their Discord has 31k members and their weekly webinars are attended by thousands of people live.The full-featuredness of LangChain means it is often the first starting point for building any mainstream LLM use case, because they are most likely to have working guides for the new developer. Logan (our first guest!) from OpenAI has been a notable fan of both LangChain and LangSmith (they will be running the first LangChain + OpenAI workshop at AI Eng Summit). However, LangChain is not without its critics, with Aravind Srinivas, Jim Fan, Max Woolf, Mckay Wrigley and the general Reddit/HN community describing frustrations with the value of their abstractions, and many are attempting to write their own (the common experience of adding and then removing LangChain is something we covered in our Agents writeup). Harrison compares this with the timeless ORM debate on the value of abstractions.LangSmithLast month, Harrison launched LangSmith, their LLM observability tool and first cloud product. LangSmith makes it easy to monitor all the different primitives that LangChain offers (agents, chains, LLMs) as well as making it easy to share and evaluate them both through heuristics (i.e. manually written ones) and “LLM evaluating LLM” flows. The top HN comment in the “LangChain is Pointless” thread observed that orchestration is the smallest part of the work, and the bulk of it is prompt tuning and data serialization. When asked this directly our pod, Harrison agreed:“I agree that those are big pain points that get exacerbated when you have these complex chains and agents where you can't really see what's going on inside of them. And I think that's partially why we built Langsmith…” (48min mark)You can watch the full launch on the LangChain YouTube:It’s clear that the target audience for LangChain is expanding to folks who are building complex, production applications rather than focusing on the simpler “Q&A your docs” use cases that made it popular in the first place. As the AI Engineer space matures, there will be more and more tools graduating from supporting “hobby” projects to more enterprise-y use cases. In this episode we run through some of the history of LangChain, how it’s growing from an open source project to one of the highest valued AI startups out there, and its future. We hope you enjoy it!Show Notes* LangChain* LangChain’s Berkshire Hathaway Homepage* Abstractions tweet* LangSmith* LangSmith Cookbooks repo* LangChain Retrieval blog* Evaluating CSV Question/Answering blog and YouTube* MultiOn Partner blog* Harvard Sports Analytics Collective* Evaluating RAG Webinar* awesome-langchain:* LLM Math Chain* Self-Ask* LangChain Hub UI* “LangChain is Pointless”* Harrison’s links* sports - estimating player compatibility in the NBA* early interest in prompt injections* GitHub* TwitterTimestamps* [00:00:00] Introduction* [00:00:48] Harrison's background and how sports led him into ML* [00:04:54] The inspiration for creating LangChain - abstracting common patterns seen in other GPT-3 projects* [00:05:51] Overview of LangChain - a framework for building context-aware reasoning applications* [00:10:09] Components of LangChain - modules, chains, agents, etc.* [00:14:39] Underappreciated parts of LangChain - text splitters, retrieval algorithms like self-query* [00:18:46] Hiring at LangChain* [00:20:27] Designing the LangChain architecture - balancing flexibility and structure* [00:24:09] The difference between chains and agents in LangChain* [00:25:08] Prompt engineering and LangChain* [00:26:16] Announcing LangSmith* [00:30:50] Writing custom evaluators in LangSmith* [00:33:19] Reducing hallucinations - fixing retrieval vs generation issues* [00:38:17] The challenges of long context windows* [00:40:01] LangChain's multi-programming language strategy* [00:45:55] Most popular LangChain blog posts - deep dives into specific topics* [00:50:25] Responding to LangChain criticisms* [00:54:11] Harrison's advice to AI engineers* [00:55:43] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space Podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol.ai. [00:00:19]Swyx: Welcome. Today we have Harrison Chase in the studio with us. Welcome Harrison. [00:00:23]Harrison: Thank you guys for having me. I'm excited to be here. [00:00:25]Swyx: It's been a long time coming. We've been asking you for a little bit and we're really glad that you got some time to join us in the studio. Yeah. [00:00:32]Harrison: I've been dodging you guys for a while. [00:00:34]Swyx: About seven months. You pulled me in here. [00:00:37]Alessio: About seven months. But it's all good. I totally understand. [00:00:38]Swyx: We like to introduce people through the official backgrounds and then ask you a little bit about your personal side. So you went to Harvard, class of 2017. You don't list what you did in Harvard. Was it CS? [00:00:48]Harrison: Stats and CS. [00:00:50]Swyx: That's awesome. I love me some good stats. [00:00:52]Harrison: I got into it through stats, through doing sports analytics. And then there was so much overlap between stats and CS that I found myself doing more and more of that. [00:00:59]Swyx: And it's interesting that a lot of the math that you learn in stats actually comes over into machine learning which you applied at Kensho as a machine learning engineer and Robust Intelligence, which seems to be the home of a lot of AI founders.Harrison: It does. Yeah. Swyx: And you started LangChain, I think around November 2022 and incorporated in January. Yeah. [00:01:19]Harrison: I was looking it up for the podcast and the first tweet was on, I think October 24th. So just before the end of November or end of October. [00:01:26]Swyx: Yeah. So that's your LinkedIn. What should people know about you on the personal side that's not obvious on LinkedIn? [00:01:33]Harrison: A lot of how I got into this is all through sports actually. Like I'm a big sports fan, played a lot of soccer growing up and then really big fan of the NBA and NFL. And so freshman year at college showed up and I knew I liked math. I knew I liked sports. One of the clubs that was there was the Sports Analytics Collective. And so I joined that freshman year, I was doing a lot of stuff in like Excel, just like basic stats, but then like wanted to do more advanced stuff. So learn to code, learn kind of like data science and machine learning through that way. Kind of like just kept on going down that path. I think sports is a great entryway to data science and machine learning. There's a lot of like numbers out there. People like really care. Like I remember, I think sophomore, junior year, I was in the Sports Collective and the main thing we had was a blog. And so we wrote a blog. It wasn't me. One of the other people in the club wrote a blog predicting the NFL season. I think they made some kind of like with stats and I think their stats showed that like the Dolphins would end up beating the Patriots and New England got like pissed about it, of course. So people like really care and they'll give you feedback about whether you're like models doing well or poorly. And so you get that. And then you also get like instantaneous kind of like, well, not instantaneous, but really quick feedback. Like if you predict a game, the game happens that night. Like you don't have to wait a year to see what happens. So I think sports is a great kind of like entryway for kind of like data science. [00:02:43]Alessio: There was actually my first article on the Twilio blog with a Python script to like predict pricing of like Daily Fantasy players based on my past week performance. Yeah, I don't know. It's a good getaway drug. [00:02:56]Swyx: And on my end, the way I got into finance was through sports betting. So maybe we all have some ties in there. Was like Moneyball a big inspiration? The movie? [00:03:06]Harrison: Honestly, not really. I don't really like baseball. That's like the big thing. [00:03:10]Swyx: Let's call it a lot of stats. Cool. Well, we can dive right into LangChain, which is what everyone is excited about. But feel free to make all the sports analogies you want. That really drives home a lot of points. What was your GPT aha moment? When did you start working on GPT itself? Maybe not LangChain, just anything to do with the GPT API? [00:03:29]Harrison: I think it probably started around the time we had a company hackathon. I think that was before I launched LangChain. I'm trying to remember the exact sequence of events, but I do remember that at the hackathon I worked with Will, who's now actually at LangChain as well, and then two other members of Robust. And we made basically a bot where you could ask questions of Notion and Slack. And so I think, yeah, RAG, basically. And I think I wanted to try that out because I'd heard that it was getting good. I'm trying to remember if I did anything before that to realize that it was good. So then I would focus on that on the hackathon. I can't remember or not, but that was one of the first times that I built something [00:04:06]Swyx: with GPT-3. There wasn't that much opportunity before because the API access wasn't that widespread. You had to get into some kind of program to get that. [00:04:16]Harrison: DaVinci-002 was not terrible, but they did an upgrade to get it to there, and they didn't really publicize that as much. And so I think I remember playing around with it when the first DaVinci model came out. I was like, this is cool, but it's not amazing. You'd have to do a lot of work to get it to do something. But then I think that February or something, I think of 2022, they upgraded it and it was it got better, but I think they made less of an announcement around it. And so I just, yeah, it kind of slipped under the radar for me, at least. [00:04:45]Alessio: And what was the step into LangChain? So you did the hackathon, and then as you were building the kind of RAG product, you felt like the developer experience wasn't that great? Or what was the inspiration? [00:04:54]Harrison: No, honestly, so around that time, I knew I was going to leave my previous job. I was trying to figure out what I was going to do next. I went to a bunch of meetups and other events. This was like the September, August, September of that year. So after Stable Diffusion, but before ChatGPT. So there was interest in generative AI as a space, but not a lot of people hacking on language models yet. But there were definitely some. And so I would go to these meetups and just chat with people and basically saw some common abstractions in terms of what they were building, and then thought it would be a cool side project to factor out some of those common abstractions. And that became kind of like LangChain. I looked up again before this, because I remember I did a tweet thread on Twitter to announce LangChain. And we can talk about what LangChain is. It's a series of components. And then there's some end-to-end modules. And there was three end-to-end modules that were in the initial release. One was NatBot. So this was the web agent by Nat Friedman. Another was LLM Math Chain. So it would construct- [00:05:51]Swyx: GPT-3 cannot do math. [00:05:53]Harrison: Yeah, exactly. And then the third was Self-Ask. So some type of RAG search, similar to React style agent. So those were some of the patterns in terms of what I was seeing. And those all came from open source or academic examples, because the people who were actually working on this were building startups. And they were doing things like question answering over your databases, question answering over SQL, things like that. But I couldn't use their code as kind of like inspiration to factor things out. [00:06:18]Swyx: I talked to you a little bit, actually, roundabout, right after you announced LangChain. I'm honored. I think I'm one of many. This is your first open source project. [00:06:26]Harrison: No, that's not actually true. I released, because I like sports stats. And so I remember I did release some really small, random Python package for scraping data from basketball reference or something. I'm pretty sure I released that. So first project to get a star on GitHub, let's say that. [00:06:45]Swyx: Did you reference anything? What was the inspirations, like other frameworks that you look to when open sourcing LangChain or announcing it or anything like that? [00:06:53]Harrison: I mean, the only main thing that I looked for... I remember reading a Hacker News post a little bit before about how a readme on the project goes a long way. [00:07:02]Swyx: Readme's help. [00:07:03]Harrison: Yeah. And so I looked at it and was like, put some status checks at the top and have the title and then one or two lines and then just right into installation. And so that's the main thing that I looked at in terms of how to structure it. Because yeah, I hadn't done open source before. I didn't really know how to communicate that aspect of the marketing or getting people to use it. I think I had some trouble finding it, but I finally found it and used that as a lot [00:07:25]Swyx: of the inspiration there. Yeah. It was one of the subjects of my write-up how it was surprising to me that significant open source experience actually didn't seem to matter in the new wave of AI tooling. Most like auto-GPTs, Torrents, that was his first open source project ever. And that became auto-GPT. Yeah. I don't know. To me, it's just interesting how open source experience is kind of fungible or not necessary. Or you can kind of learn it on the job. [00:07:49]Alessio: Overvalued. [00:07:50]Swyx: Overvalued. Okay. You said it, not me. [00:07:53]Alessio: What's your description of LangChain today? I think when I built the LangChain Hub UI in January, there were a few things. And I think you were one of the first people to talk about agents that were already in there before it got hot now. And it's obviously evolved into a much bigger framework today. Run people through what LangChain is today, how they should think about it, and all of that. [00:08:14]Harrison: The way that we describe it or think about it internally is that LangChain is basically... I started off saying LangChain's a framework for building LLM applications, but that's really vague and not really specific. And I think part of the issue is LangChain does do a lot, so it's hard to be somewhat specific. But I think the way that we think about it internally, in terms of prioritization, what to focus on, is basically LangChain's a framework for building context-aware reasoning applications. And so that's a bit of a mouthful, but I think that speaks to a lot of the core parts of what's in LangChain. And so what concretely that means in LangChain, there's really two things. One is a set of components and modules. And these would be the prompt template abstraction, the LLM abstraction, chat model abstraction, vector store abstraction, text splitters, document loaders. And so these are combinations of things that we build and we implement, or we just have integrations with. So we don't have any language models ourselves. We don't have any vector stores ourselves, but we integrate with a lot of them. And then the text splitters, we have our own logic for that. The document loaders, we have our own logic for that. And so those are the individual modules. But then I think another big part of LangChain, and probably the part that got people using it the most, is the end-to-end chains or applications. So we have a lot of chains for getting started with question answering over your documents, chat question answering, question answering over SQL databases, agent stuff that you can plug in off the box. And that basically combines these components in a series of specific ways to do this. So if you think about a question answering app, you need a lot of different components kind of stacked. And there's a bunch of different ways to do question answering apps. So this is a bit of an overgeneralization, but basically, you know, you have some component that looks up an embedding from a vector store, and then you put that into the prompt template with the question and the context, and maybe you have the chat history as well. And then that generates an answer, and then maybe you parse that out, or you do something with the answer there. And so there's just this sequence of things that you basically stack in a particular way. And so we just provide a bunch of those assembled chains off the shelf to make it really easy to get started in a few lines of code. [00:10:09]Alessio: And just to give people context, when you first released LangChain, OpenAI did not have a chat API. It was a completion-only API. So you had to do all the human assistant, like prompting and whatnot. So you abstracted a lot of that away. I think the most interesting thing to me is you're kind of the Switzerland of this developer land. There's a bunch of vector databases that are killing each other out there to get people to embed data in them, and you're like, I love you all. You all are great. How do you think about being an opinionated framework versus leaving a lot of choice to the user? I mean, in terms of spending time into this integration, it's like you only have 10 people on the team. Obviously that takes time. Yeah. What's that process like for you all? [00:10:50]Harrison: I think right off the bat, having different options for language models. I mean, language models is the main one that right off the bat we knew we wanted to support a bunch of different options for. There's a lot to discuss there. People want optionality between different language models. They want to try it out. They want to maybe change to ones that are cheaper as new ones kind of emerge. They don't want to get stuck into one particular one if a better one comes out. There's some challenges there as well. Prompts don't really transfer. And so there's a lot of nuance there. But from the bat, having this optionality between the language model providers was a big important part because I think that was just something we felt really strongly about. We believe there's not just going to be one model that rules them all. There's going to be a bunch of different models that are good for a bunch of different use cases. I did not anticipate the number of vector stores that would emerge. I don't know how many we supported in the initial release. It probably wasn't as big of a focus as language models was. But I think it kind of quickly became so, especially when Postgres and Elastic and Redis started building their vector store implementations. We saw that some people might not want to use a dedicated vector store. Maybe they want to use traditional databases. I think to your point around what we're opinionated about, I think the thing that we believe most strongly is it's super early in the space and super fast moving. And so there's a lot of uncertainty about how things will shake out in terms of what role will vector databases play? How many will there be? And so I think a lot of it has always kind of been this optionality and ability to switch and not getting locked in. [00:12:19]Swyx: There's other pieces of LangChain which maybe don't get as much attention sometimes. And the way that you explained LangChain is somewhat different from the docs. I don't know how to square this. So for example, you have at the top level in your docs, you have, we mentioned ModelIO, we mentioned Retrieval, we mentioned Chains. Then you have a concept called Agents, which I don't know if exactly matches what other people call Agents. And we also talked about Memory. And then finally there's Callbacks. Are there any of the less understood concepts in LangChain that you want to give some air to? [00:12:53]Harrison: I mean, I think buried in ModelIO is some stuff around like few-shot example selectors that I think is really powerful. That's a workhorse. [00:13:01]Swyx: Yeah. I think that's where I start with LangChain. [00:13:04]Harrison: It's one of those things that you probably don't, if you're building an application, you probably don't start with it. You probably start with like a zero-shot prompt. But I think that's a really powerful one that's probably just talked about less because you don't need it right off the bat. And for those of you who don't know, that basically selects from a bunch of examples the ones that are maybe most relevant to the input at hand. So you can do some nice kind of like in-context learning there. I think that's, we've had that for a while. I don't think enough people use that, basically. Output parsers also used to be kind of important, but then function calling. There's this interesting thing where like the space is just like progressing so rapidly that a lot of things that were really important have kind of diminished a bit, to be honest. Output parsers definitely used to be an understated and underappreciated part. And I think if you're working with non-OpenAI models, they still are, but a lot of people are working with OpenAI models. But even within there, there's different things you can do with kind of like the function calling ability. Sometimes you want to have the option of having the text or the application you're building, it could return either. Sometimes you know that it wants to return in a structured format, and so you just want to take that structured format. Other times you're extracting things that are maybe a key in that structured format, and so you want to like pluck that key. And so there's just like some like annoying kind of like parsing of that to do. Agents, memory, and retrieval, we haven't talked at all. Retrieval, there's like five different subcomponents. You could also probably talk about all of those in depth. You've got the document loaders, the text splitters, the embedding models, the vector stores. Embedding models and vector stores, we don't really have, or sorry, we don't build, we integrate with those. Text splitters, I think we have like 15 or so. Like I think there's an under kind of like appreciated amount of those. [00:14:39]Swyx: And then... Well, it's actually, honestly, it's overwhelming. Nobody knows what to choose. [00:14:43]Harrison: Yeah, there is a lot. [00:14:44]Swyx: Yeah. Do you have personal favorites that you want to shout out? [00:14:47]Harrison: The one that we have in the docs is the default is like the recursive text splitter. We added a playground for text splitters the other week because, yeah, we heard a lot that like, you know, and like these affect things like the chunk overlap and the chunks, they affect things in really subtle ways. And so like I think we added a playground where people could just like choose different options. We have like, and a lot of the ideas are really similar. You split on different characters, depending on kind of like the type of text that you have marked down, you might want to split on differently than HTML. And so we added a playground where you can kind of like choose between those. I don't know if those are like underappreciated though, because I think a lot of people talk about text splitting as being a hard part, and it is a really important part of creating these retrieval applications. But I think we have a lot of really cool retrieval algorithms as well. So like self query is maybe one of my favorite things in LangChain, which is basically this idea of when you have a user question, the typical kind of like thing to do is you embed that question and then find the document that's most similar to that question. But oftentimes questions have things that just, you don't really want to look up semantically, they have some other meaning. So like in the example that I use, the example in the docs is like movies about aliens in the year 1980. 1980, I guess there's some semantic meaning for that, but it's a very particular thing that you care about. And so what the self query retriever does is it splits out the metadata filter and most vector stores support like a metadata filter. So it splits out this metadata filter, and then it splits out the semantic bit. And that's actually like kind of tricky to do because there's a lot of different filters that you can have like greater than, less than, equal to, you can have and things if you have multiple filters. So we have like a pretty complicated like prompt that does all that. That might be one of my favorite things in LangChain, period. Like I think that's, yeah, I think that's really cool. [00:16:26]Alessio: How do you think about speed of development versus support of existing things? So we mentioned retrieval, like you got, or, you know, text splitting, you got like different options for all of them. As you get building LangChain, how do you decide which ones are not going to keep supporting, you know, which ones are going to leave behind? I think right now, as you said, the space moves so quickly that like you don't even know who's using what. What's that like for you? [00:16:50]Harrison: Yeah. I mean, we have, you know, we don't really have telemetry on what people are using in terms of what parts of LangChain, the telemetry we have is like, you know, anecdotal stuff when people ask or have issues with things. A lot of it also is like, I think we definitely prioritize kind of like keeping up with the stuff that comes out. I think we added function calling, like the day it came out or the day after it came out, we added chat model support, like the day after it came out or something like that. That's probably, I think I'm really proud of how the team has kind of like kept up with that because this space is like exhausting sometimes. And so that's probably, that's a big focus of ours. The support, I think we've like, to be honest, we've had to get kind of creative with how we do that. Cause we have like, I think, I don't know how many open issues we have, but we have like 3000, somewhere between 2000 and 3000, like open GitHub issues. We've experimented with a lot of startups that are doing kind of like question answering over your docs and stuff like that. And so we've got them on the website and in the discord and there's a really good one, dosu on the GitHub that's like answering issues and stuff like that. And that's actually something we want to start leaning into more heavily as a company as well as kind of like building out an AI dev rel because we're 10 people now, 10, 11 people now. And like two months ago we were like six or something like that. Right. So like, and to have like 2,500 open issues or something like that, and like 300 or 400 PRs as well. Cause like one of the amazing things is that like, and you kind of alluded to this earlier, everyone's building in the space. There's so many different like touch points. LangChain is lucky enough to kind of like be a lot of the glue that connects it. And so we get to work with a lot of awesome companies, but that's also a lot of like work to keep up with as well. And so I don't really have an amazing answer, but I think like the, I think prioritize kind of like new things that, that come out. And then we've gotten creative with some of kind of like the support functions and, and luckily there's, you know, there's a lot of awesome people working on all those support coding, question answering things that we've been able to work with. [00:18:46]Swyx: I think there is your daily rhythm, which I've seen you, you work like a, like a beast man, like mad impressive. And then there's sometimes where you step back and do a little bit of high level, like 50,000 foot stuff. So we mentioned, we mentioned retrieval. You did a refactor in March and there's, there's other abstractions that you've sort of changed your mind on. When do you do that? When do you do like the, the step back from the day to day and go, where are we going and change the direction of the ship? [00:19:11]Harrison: It's a good question so far. It's probably been, you know, we see three or four or five things pop up that are enough to make us think about it. And then kind of like when it reaches that level, you know, we don't have like a monthly meeting where we sit down and do like a monthly plan or something. [00:19:27]Swyx: Maybe we should. I've thought about this. Yeah. I'd love to host that meeting. [00:19:32]Harrison: It's really been a lot of, you know, one of the amazing things is we get to interact with so many different people. So it's been a lot of kind of like just pattern matching on what people are doing and trying to see those patterns before they punch us in the face or something like that. So for retrieval, it was the pattern of seeing like, Hey, yeah, like a lot of people are using vector sort of stuff. But there's also just like other methods and people are offering like hosted solutions and we want our abstractions to work with that as well. So we shouldn't bake in this paradigm of doing like semantic search too heavily, which sounds like basic now, but I think like, you know, to start a lot of it was people needed help doing these things. But then there was like managed things that did them, hybrid retrieval mechanisms, all of that. I think another example of this, I mean, Langsmith, which we can maybe talk about was like very kind of like, I think we worked on that for like three or four months before announcing it kind of like publicly, two months maybe before giving it to kind of like anyone in beta. But this was a lot of debugging these applications as a pain point. We hear that like just understanding what's going on is a pain point. [00:20:27]Alessio: I mean, you two did a webinar on this, which is called Agents vs. Chains. It was fun, baby. [00:20:32]Swyx: Thanks for having me on. [00:20:33]Harrison: No, thanks for coming. [00:20:34]Alessio: That was a good one. And on the website, you list like RAG, which is retrieval of bank debt generation and agents as two of the main goals of LangChain. The difference I think at the Databricks keynote, you said chains are like predetermined steps and agents is models reasoning to figure out what steps to take and what actions to take. How should people think about when to use the two and how do you transition from one to the other with LangChain? Like is it a path that you support or like do people usually re-implement from an agent to a chain or vice versa? [00:21:05]Swyx: Yeah. [00:21:06]Harrison: You know, I know agent is probably an overloaded term at this point, and so there's probably a lot of different definitions out there. But yeah, as you said, kind of like the way that I think about an agent is basically like in a chain, you have a sequence of steps. You do this and then you do this and then you do this and then you do this. And with an agent, there's some aspect of it where the LLM is kind of like deciding what to do and what steps to do in what order. And you know, there's probably some like gray area in the middle, but you know, don't fight me on this. And so if we think about those, like the benefits of the chains are that they're like, you can say do this and you just have like a more rigid kind of like order and the way that things are done. They have more control and they don't go off the rails and basically everything that's bad about agents in terms of being uncontrollable and expensive, you can control more finely. The benefit of agents is that I think they handle like the long tail of things that can happen really well. And so for an example of this, let's maybe think about like interacting with a SQL database. So you can have like a SQL chain and you know, the first kind of like naive approach at a SQL chain would be like, okay, you have the user question. And then you like write the SQL query, you do some rag, you pull in the relevant tables and schemas, you write a SQL query, you execute that against the SQL database. And then you like return that as the answer, or you like summarize that with an LLM and return that to the answer. And that's basically the SQL chain that we have in LangChain. But there's a lot of things that can go wrong in that process. Starting from the beginning, you may like not want to even query the SQL database at all. Maybe they're saying like, hi, or something, or they're misusing the application. Then like what happens if you have some step, like a big part of the application that people with LangChain is like the context aware part. So there's generally some part of bringing in context to the language model. So if you bring in the wrong context to the language model, so it doesn't know which tables to query, what do you do then? If you write a SQL query, it's like syntactically wrong and it can't run. And then if it can run, like what if it returns an unexpected result or something? And so basically what we do with the SQL agent is we give it access to all these different tools. So it has another tool, it can run the SQL query as another, and then it can respond to the user. But then if it kind of like, it can decide which order to do these. And so it gives it flexibility to handle all these edge cases. And there's like, obviously downsides to that as well. And so there's probably like some safeguards you want to put in place around agents in terms of like not letting them run forever, having some observability in there. But I do think there's this benefit of, you know, like, again, to the other part of what LangChain is like the reasoning part, like each of those steps individually involves some aspect of reasoning, for sure. Like you need to reason about what the SQL query is, you need to reason about what to return. But there's then there's also reasoning about the order of operations. And so I think to me, the key is kind of like giving it an appropriate amount to reason about while still keeping it within checks. And so to the point, like, I would probably recommend that most people get started with chains and then when they get to the point where they're hitting these edge cases, then they think about, okay, I'm hitting a bunch of edge cases where the SQL query is just not returning like the relevant things. Maybe I should add in some step there and let it maybe make multiple queries or something like that. Basically, like start with chain, figure out when you're hitting these edge cases, add in the reasoning step to that to handle those edge cases appropriately. That would be kind of like my recommendation, right? [00:24:09]Swyx: If I were to rephrase it, in my words, an agent would be a reasoning node in a chain, right? Like you start with a chain, then you just add a reasoning node, now it's an agent. [00:24:17]Harrison: Yeah, the architecture for your application doesn't have to be just a chain or just an agent. It can be an agent that calls chains, it can be a chain that has an agent in different parts of them. And this is another part as well. Like the chains in LangChain are largely intended as kind of like a way to get started and take you some amount of the way. But for your specific use case, in order to kind of like eke out the most performance, you're probably going to want to do some customization at the very basic level, like probably around the prompt or something like that. And so one of the things that we've focused on recently is like making it easier to customize these bits of existing architectures. But you probably also want to customize your architectures as well. [00:24:52]Swyx: You mentioned a bit of prompt engineering for self-ask and then for this stuff. There's a bunch of, I just talked to a prompt engineering company today, PromptOps or LLMOps. Do you have any advice or thoughts on that field in general? Like are you going to compete with them? Do you have internal tooling that you've built? [00:25:08]Harrison: A lot of what we do is like where we see kind of like a lot of the pain points being like we can talk about LangSmith and that was a big motivation for that. And like, I don't know, would you categorize LangSmith as PromptOps? [00:25:18]Swyx: I don't know. It's whatever you want it to be. Do you want to call it? [00:25:22]Harrison: I don't know either. Like I think like there's... [00:25:24]Swyx: I think about it as like a prompt registry and you store them and you A-B test them and you do that. LangSmith, I feel like doesn't quite go there yet. Yeah. It's obviously the next step. [00:25:34]Harrison: Yeah, we'll probably go. And yeah, we'll do more of that because I think that's definitely part of the application of a chain or agent is you start with a default one, then you improve it over time. And like, I think a lot of the main new thing that we're dealing with here is like language models. And the main new way to control language models is prompts. And so like a lot of the chains and agents are powered by this combination of like prompt language model and then some output parser or something doing something with the output. And so like, yeah, we want to make that core thing as good as possible. And so we'll do stuff all around that for sure. [00:26:05]Swyx: Awesome. We might as well go into LangSmith because we're bringing it up so much. So you announced LangSmith I think last month. What are your visions for it? Is this the future of LangChain and the company? [00:26:16]Harrison: It's definitely part of the future. So LangSmith is basically a control center for kind of like your LLM application. So the main features that it kind of has is like debugging, logging, monitoring, and then like testing and evaluation. And so debugging, logging, monitoring, basically you set three environment variables and it kind of like logs all the runs that are happening in your LangChain chains or agents. And it logs kind of like the inputs and outputs at each step. And so the main use case we see for this is in debugging. And that's probably the main reason that we started down this path of building it is I think like as you have these more complex things, debugging what's actually going on becomes really painful whether you're using LangChain or not. And so like adding this type of observability and debuggability was really important. Yeah. There's a debugging aspect. You can see the inputs, outputs at each step. You can then quickly enter into like a playground experience where you can fiddle around with it. The first version didn't have that playground and then we'd see people copy, go to open AI playground, paste in there. Okay. Well, that's a little annoying. And then there's kind of like the monitoring, logging experience. And we recently added some analytics on like, you know, how many requests are you getting per hour, minute, day? What's the feedback like over time? And then there's like a testing debugging, sorry, testing and evaluation component as well where basically you can create datasets and then test and evaluate these datasets. And I think importantly, all these things are tied to each other and then also into LangChain, the framework. So what I mean by that is like we've tried to make it as easy as possible to go from logs to adding a data point to a dataset. And because we think a really powerful flow is you don't really get started with a dataset. You can accumulate a dataset over time. And so being able to find points that have gotten like a thumbs up or a thumbs down from a user can be really powerful in terms of creating a good dataset. And so that's maybe like a connection between the two. And then the connection in the other way is like all the runs that you have when you test or evaluate something, they're logged in the same way. So you can debug what exactly is going on and you don't just have like a final score. You have like this nice trace and thing where you can jump in. And then we also want to do more things to hook this into a LangChain proper, the framework. So I think like some of like the managing the prompts will tie in here already. Like we talked about example selectors using datasets as a few short examples is a path that we support in a somewhat janky way right now, but we're going to like make better over time. And so there's this connection between everything. Yeah. [00:28:42]Alessio: And you mentioned the dataset in the announcement blog post, you touched on heuristic evaluation versus LLMs evaluating LLMs. I think there's a lot of talk and confusion about this online. How should people prioritize the two, especially when they might start with like not a good set of evals or like any data at all? [00:29:01]Harrison: I think it's really use case specific in the distinction that I draw between heuristic and LLM. LLMs, you're using an LLM to evaluate the output heuristics, you have some common heuristic that you can use. And so some of these can be like really simple. So we were doing some kind of like measuring of an extraction chain where we wanted it to output JSON. Okay. One evaluation can be, can you use JSON.loads to load it? And like, right. And that works perfectly. You don't need an LLM to do that. But then for like a lot of like the question answering, like, is this factually accurate? And you have some ground truth fact that you know it should be answering with. I think, you know, LLMs aren't perfect. And I think there's a lot of discussion around the pitfalls of using LLMs to evaluate themselves. And I'm not saying they're perfect by any means, but I do think they're, we've found them to be kind of like better than blue or any of those metrics. And the way that I also like to use those is also just like guide my eye about where to look. So like, you know, I might not trust the score of like 0.82, like exactly correct, but like I can look to see like which data points are like flagged as passing or failing. And sometimes the evaluators messing up, but it's like good to like, you know, I don't have to look at like a hundred data points. I can focus on like 10 or something like that. [00:30:10]Alessio: And then can you create a heuristic once in Langsmith? Like what's like your connection to that? [00:30:16]Harrison: Yeah. So right now, all the evaluation, we actually do client side. And part of this is basically due to the fact that a lot of the evaluation is really application specific. So we thought about having evaluators, you could just click off and run in a server side or something like that. But we still think it's really early on in evaluation. We still think there's, it's just really application specific. So we prioritized instead, making it easy for people to write custom evaluators and then run them client side and then upload the results so that they can manually inspect them because I think manual inspection is still a pretty big part of evaluation for better or worse. [00:30:50]Swyx: We have this sort of components of observability. We have cost, latency, accuracy, and then planning. Is that listed in there? [00:30:57]Alessio: Well, planning more in the terms of like, if you're an agent, how to pick the right tool and whether or not you are picking the right tool. [00:31:02]Swyx: So when you talk to customers, how would you stack rank those needs? Are they cost sensitive? Are they latency sensitive? I imagine accuracy is pretty high up there. [00:31:13]Harrison: I think accuracy is definitely the top that we're seeing right now. I think a lot of the applications, people are, especially the ones that we're working with, people are still struggling to get them to work at a level where they're reliable [00:31:24]Swyx: enough. [00:31:25]Harrison: So that's definitely the first. Then I think probably cost becomes the next one. I think a few places where we've started to see this be like one of the main things is the AI simulation that came out. [00:31:36]Swyx: Generative agents. Yeah, exactly. [00:31:38]Harrison: Which is really fun to run, but it costs a lot of money. And so one of our team members, Lance, did an awesome job hooking up like a local model to it. You know, it's not as perfect, but I think it helps with that. Another really big place for this, we believe, is in like extraction of structured data from unstructured data. And the reason that I think it's so important there is that usually you do extraction of some type of like pre-processing or indexing process over your documents. I mean, there's a bunch of different use cases, but one use case is for that. And generally that's over a lot of documents. And so that starts to rack up a bill kind of quickly. And I think extraction is also like a simpler task than like reasoning about which tools to call next in an agent. And so I think it's better suited for that. Yeah. [00:32:15]Swyx: On one of the heuristics I wanted to get your thoughts on, hallucination is one of the big problems there. Do you have any recommendations on how people should reduce hallucinations? [00:32:25]Harrison: To reduce hallucinations, we did a webinar on like evaluating RAG this past week. And I think there's this great project called RAGOS that evaluates four different things across two different spectrums. So the two different spectrums are like, is the retrieval part right? Or is the generation, or sorry, like, is it messing up in retrieval or is it messing up in generation? And so I think to fix hallucination, it probably depends on where it's messing up. If it's messing up in generation, then you're getting the right information, but it's still hallucinating. Or you're getting like partially right information and hallucinating some bits, a lot of that's prompt engineering. And so that's what we would recommend kind of like focusing on the prompt engineering part. And then if you're getting it wrong in the, if you're just not retrieving the right stuff, then there's a lot of different things that you can probably do, or you should look at on the retrieval bit. And honestly, that's where it starts to become a bit like application specific as well. Maybe there's some temporal stuff going on. Maybe you're not parsing things correctly. Yeah. [00:33:19]Swyx: Okay. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:33:35]Harrison: Yeah. Yeah. [00:33:37]Swyx: Yeah. [00:33:38]Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:33:56]Swyx: Yeah. Yeah. [00:33:58]Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:34:04]Swyx: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. Yeah. [00:34:17]Harrison: Yeah. Yeah. Yeah. Yeah. Yeah. Yeah, I mean, there's probably a larger discussion around that, but openAI definitely had a huge headstart, right? And that's... Clawds not even publicly available yet, I don't think. [00:34:28]Swyx: The API? Yeah. Oh, well, you can just basically ask any of the business reps and they'll give it to you. [00:34:33]Harrison: You can. But it's still a different signup process. I think there's... I'm bullish that other ones will catch up especially like Anthropic and Google. The local ones are really interesting. I think we're seeing a big... [00:34:46]Swyx: Lama Two? Yeah, we're doing the fine-tuning hackathon tomorrow. Thanks for promoting that. [00:34:50]Harrison: No, thanks for it. I'm really excited about that stuff. I mean, that's something that like we've been, you know, because like, as I said, like the only thing we know is that the space is moving so fast and changing so rapidly. And like, local models are, have always been one of those things that people have been bullish on. And it seems like it's getting closer and closer to kind of like being viable. So I'm excited to see what we can do with some fine-tuning. [00:35:10]Swyx: Yeah. I have to confess, I did not know that you cared. It's not like a judgment on Langchain. I was just like, you know, you write an adapter for it and you're done, right? Like how much further does it go for Langchain? In terms of like, for you, it's one of the, you know, the model IO modules and that's it. But like, you seem very personally, very passionate about it, but I don't know what the Langchain specific angle for this is, for fine-tuning local models, basically. Like you're just passionate about local models and privacy and all that, right? And open source. [00:35:41]Harrison: Well, I think there's a few different things. Like one, like, you know, if we think about what it takes to build a really reliable, like context-aware reasoning application, there's probably a bunch of different nodes that are doing a bunch of different things. And I think it is like a really complex system. And so if you're relying on open AI for every part of that, like, I think that starts to get really expensive. Also like, probably just like not good to have that much reliability on any one thing. And so I do think that like, I'm hoping that for like, you know, specific parts at the end, you can like fine-tune a model and kind of have a more specific thing for a specific task. Also, to be clear, like, I think like, I also, at the same time, I think open AI is by far the easiest way to get started. And if I was building anything, I would absolutely start with open AI. So. [00:36:27]Swyx: It's something I think a lot of people are wrestling with. But like, as a person building apps, why take five vendors when I can take one vendor, right? Like, as long as I trust Azure, I'm just entrusting all my data to Azure and that's it. So I'm still trying to figure out the real case for local models in production. And I don't know, but fine-tuning, I think, is a good one. That's why I guess open AI worked on fine-tuning. [00:36:49]Harrison: I think there's also like, you know, like if there is, if there's just more options available, like prices are going to go down. So I'm happy about that. So like very selfishly, there's that aspect as well. [00:37:01]Alessio: And in the Lancsmith announcement, I saw in the product screenshot, you have like chain, tool and LLM as like the three core atoms. Is that how people should think about observability in this space? Like first you go through the chain and then you start dig down between like the model itself and like the tool it's using? [00:37:19]Harrison: We've added more. We've added like a retriever logging so that you can see like what query is going in and what are the documents you're getting out. Those are like the three that we started with. I definitely think probably the main ones, like basically the LLM. So the reason I think the debugging in Lancsmith and debugging in general is so needed for these LLM apps is that if you're building, like, again, let's think about like what we want people to build in with LangChain. These like context aware reasoning applications. Context aware. There's a lot of stuff in the prompt. There's like the instructions. There's any previous messages. There's any input this time. There's any documents you retrieve. And so there's a lot of like data engineering that goes into like putting it into that prompt. This sounds silly, but just like making sure the data shows up in the right format is like really important. And then for the reasoning part of it, like that's obviously also all in the prompt. And so being able to like, and there's like, you know, the state of the world right now, like if you have the instructions at the beginning or at the end can actually make like a big difference in terms of whether it forgets it or not. And so being able to kind of like. [00:38:17]Swyx: Yeah. And it takes on that one, by the way, this is the U curve in context, right? Yeah. [00:38:21]Harrison: I think it's real. Basically I've found long context windows really good for when I want to extract like a single piece of information about something basically. But if I want to do reasoning over perhaps multiple pieces of information that are somewhere in like the retrieved documents, I found it not to be that great. [00:38:36]Swyx: Yeah. I have said that that piece of research is the best bull case for Lang chain and all the vector companies, because it means you should do chains. It means you should do retrieval instead of long context, right? People are trying to extend long context to like 100K, 1 million tokens, 5 million tokens. It doesn't matter. You're going to forget. You can't trust it. [00:38:54]Harrison: I expect that it will probably get better over time as everything in this field. But I do also think there'll always be a need for kind of like vector stores and retrieval in some fashions. [00:39:03]Alessio: How should people get started with Langsmith Cookbooks? Wanna talk maybe a bit about that? [00:39:08]Swyx: Yeah. [00:39:08]Harrison: Again, like I think the main thing that even I find valuable about Langsmith is just like the debugging aspect of it. And so for that, it's very simple. You can kind of like turn on three environment variables and it just logs everything. And you don't look at it 95% of the time, but that 5% you do when something goes wrong, it's quite handy to have there. And so that's probably the easiest way to get started. And we're still in a closed beta, but we're letting people off the wait list every day. And if you really need access, just DM me and we're happy to give you access there. And then yeah, there's a lot that you can do with Langsmith that we've been talking about. And so Will on our team has been leading the charge on a really great like Langsmith Cookbooks repo that covers everything from collecting feedback, whether it's thumbs up, thumbs down, or like multi-scale or comments as well, to doing evaluation, doing testing. You can also use Langsmith without Langchain. And so we've got some notebooks on that in there. But we have Python and JavaScript SDKs that aren't dependent on Langchain in any way. [00:40:01]Swyx: And so you can use those. [00:40:01]Harrison: And then we'll also be publishing a notebook on how to do that just with the REST APIs themselves. So yeah, definitely check out that repo. That's a great resource that Will's put together. [00:40:10]Swyx: Yeah, awesome. So we'll zoom out a little bit from Langsmith and talk about Langchain, the company. You're also a first-time founder. Yes. And you've just hired your 10th employee, Julia, who I know from my data engineering days. You mentioned Will Nuno, I think, who maintains Langchain.js. I'm very interested in like your multi-language strategy, by the way. Ankush, your co-founder, Lance, who did AutoEval. What are you staffing up for? And maybe who are you hiring? [00:40:34]Harrison: Yeah, so 10 employees, 12 total. We've got three more joining over the next three weeks. We've got Julia, who's awesome leading a lot of the product, go-to-market, customer success stuff. And then we've got Bri, who's also awesome leading a lot of the marketing and ops aspects. And then other than that, all engineers. We've staffed up a lot on kind of like full stack infra DevOps, kind of like as we've started going into the hosted platform. So internally, we're split about 50-50 between the open source and then the platform stuff. And yeah, we're looking to hire particularly on kind of like the things, we're actually looking to hire across most fronts, to be honest. But in particular, we probably need one or two more people on like open source, both Python and JavaScript and happy to dive into the multi-language kind of like strategy there. But again, like strong focus there on engineering, actually, as opposed to maybe like, we're not a research lab, we're not a research shop. [00:41:48]Swyx: And then on the platform side, [00:41:49]Harrison: like we definitely need some more people on the infra and DevOps side. So I'm using this as an opportunity to tell people that we're hiring and that you should reach out if that sounds like you. [00:41:58]Swyx: Something like that, jobs, whatever. I don't actually know if we have an official job. [00:42:02]Harrison: RIP, what happened to your landing page? [00:42:04]Swyx: It used to be so based. The Berkshire Hathaway one? Yeah, so what was the story, the quick story behind that? Yeah, the quick story behind that is we needed a website [00:42:12]Harrison: and I'm terrible at design. [00:42:14]Swyx: And I knew that we couldn't do a good job. [00:42:15]Harrison: So if you can't do a good job, might as well do the worst job possible. Yeah, and like lean into it. And have some fun with it, yeah. [00:42:21]Swyx: Do you admire Warren Buffett? Yeah, I admire Warren Buffett and admire his website. And actually you can still find a link to it [00:42:26]Harrison: from our current website if you look hard enough. So there's a little Easter egg. Before we dive into more of the open source community things, [00:42:33]Alessio: let's dive into the language thing. How do you think about parity between the Python and JavaScript? Obviously, they're very different ecosystems. So when you're working on a LangChain, is it we need to have the same abstraction in both language or are you to the needs? The core stuff, we want to have the same abstractions [00:42:50]Harrison: because we basically want to be able to do serialize prompts, chains, agents, all the core stuff as tightly as possible and then use that between languages. Like even, yeah, like even right now when we log things to LangChain, we have a playground experience where you can run things that runs in JavaScript because it's kind of like in the browser. But a lot of what's logged is like Python. And so we need that core equivalence for a lot of the core things. Then there's like the incredibly long tail of like integrations, more researchy things. So we want to be able to do that. Python's probably ahead on a lot of like the integrations front. There's more researchy things that we're able to include quickly because a lot of people release some of their code in Python and stuff like that. And so we can use that. And there's just more of an ecosystem around the Python project. But the core stuff will have kind of like the same abstractions and be translatable. That didn't go exactly where I was thinking. So like the LangChain of Ruby, the LangChain of C-sharp, [00:43:44]Swyx: you know, there's demand for that. I mean, I think that's a big part of it. But you are giving up some real estate by not doing it. Yeah, it comes down to kind of like, you know, ROI and focus. And I think like we do think [00:43:58]Harrison: there's a strong JavaScript community and we wanted to lean into that. And I think a lot of the people that we brought on early, like Nuno and Jacob have a lot of experience building JavaScript tooling in that community. And so I think that's a big part of it. And then there's also like, you know, building JavaScript tooling in that community. Will we do another language? Never say never, but like... [00:44:21]Swyx: Python JS for now. Yeah. Awesome. [00:44:23]Alessio: You got 83 articles, which I think might be a record for such a young company. What are like the hottest hits, the most popular ones? [00:44:32]Harrison: I think the most popular ones are generally the ones where we do a deep dive on something. So we did something a few weeks ago around evaluating CSV question answering applications, which I think is a really interesting one because most question answering, like everyone does question answering, but it's generally over unstructured data over your documents and you do the whole rag thing. And that doesn't work amazing for structured data. And so this was something that we heard, the origin of this was basically we heard from the community, you guys should improve this. And so we're like, okay, let's improve it. And then we're like, okay, well, in order to see if we improve it, we need to like evaluate it and see how we're doing. And so we kind of like wrote up a lot of our thought process there. And I think, and a lot of people like reached out about that and thought that was interesting and we're going through similar challenges and had, we posted another one a few days after that someone wrote basically as a response, which is awesome because it had a completely different strategy. And it was a really, it was a really, that was a really good piece as well. So that was like a deep dive on something like evaluation bit. I think like we did one on retrieval a while back, which was basically like, hey, we, and this was around when we changed our abstractions, like, hey, we changed our abstractions to this. This is why we did it. This is what we see coming down the pipeline. These are like the different types of retrieval that we see. I think a lot of people read and liked that one. A lot of the blogs that we do are also highlighting cool partnerships or cool applications. But in terms of, if you go by like number of views, I think the ones that get the most views are the more like deep dive ones. [00:45:55]Swyx: Yeah. And I also noticed that you do guest posts as well. [00:45:58]Harrison: Actually, you know, which one, and this is a guest post that got a lot of views, the multi-on one, the multi-on agent one. When we did, we did a blog where we integrated with them and that got a ton of views. [00:46:06]Swyx: What do you think that is? [00:46:07]Harrison: I think it's, I mean, it's one of like the few agents that's actually available and like out in the world. [00:46:15]Swyx: They're still behind a wait list. Still behind a wait list, [00:46:17]Harrison: but they're very active on social media. I don't know if I'm off the wait list. [00:46:21]Swyx: I mean, you're on their blogs. They're on your blog, so I hope they give you access at some point. But that's interesting. A lot of interest in agents. I think they just opened up an API as well. Yeah, exactly. [00:46:32]Harrison: That was the blog that we did. I was, yeah, I was a bit surprised to see that as well, but I think there's generally a lot of interest in agents and it's also really hard to get them to work. And I think multi-on is one of the first that has that. [00:46:45]Swyx: Yeah. So my angle to this is a lot of people want to work with you. Yes. You're bombarded. I'm sure your email is just unmanageable. How should people be good partners with you? Like I work at a company and I'm like, hey, I'd love to do something on the LangChain blog or integrate to LangChain. I know Harrison's a busy guy. Like, what do I do? [00:47:03]Harrison: Like the stuff that gets my attention honestly is like the in-depth, really thought out stuff. Obviously I love this stuff. Like this stuff is awesome. And there's so many different, there's so much to do as well. And like the biggest thing that we have trouble with internally is like figuring out what to do. [00:47:17]Swyx: What's noise and what's signal. [00:47:19]Harrison: Not even that, but just like what to focus on. Like there's so many different directions we could do and we want to go in like so many because there's so many interesting things, but we can't do. So if anyone kind of like takes the time to like go deep in a particular area, I love talking to them and I love reading what they write. And I love sharing what they write on the blog. Like that to me is awesome. So I think like... [00:47:37]Swyx: Do good stuff. Be so good they can't ignore you. It sounds basic, right? [00:47:40]Harrison: So that's why I didn't want to say it. [00:47:42]Swyx: No, it's great. [00:47:42]Harrison: But I think like these deep dots, yeah, there's just so much to do and these don't do shallow stuff, I guess would be. [00:47:48]Swyx: I think that's a good call that people need reminding. [00:47:50]Alessio: What about the other side of open source? So on Acker News, there were a couple blog posts recently, like the problem with LangChain and LangChain is pointless, all these different things. So the TLDR of some of them were, the LangChain API is like kind of verbose and complicated versus like sometimes I can just do this in like 10 lines of code. How do you balance that in terms of allowing for the complex use cases versus making maybe the ergonomics like simpler, but then trading that off later? [00:48:21]Harrison: There's a lot to balance and there's a lot to do. And I think like posts like that are very valuable to hear basically what people are saying. And like, we have a lot of open issues. So it's not like these things hadn't been said before, but I think like that was a good emphasis on what people are saying. And I think there was a lot of things in there. I think part of it's kind of like around and we took all of it very seriously. And yeah, I think there's a lot to dive into there. There's like the documentation piece. And so I think we did a revamp of the documentation to address that. There's also like a comment in this, I think this was around, I think the top comment on the LangChain is pointless one was like basically like orchestration is like 5% of the work. And then like the other 95% is like prompt engineering and like data engineering. And those are the hard bits. I think maybe orchestration is a little bit more than 5%, but I like agree that those are like really big pain points that get exacerbated when you have these complex chains and agents where you can't really see what's going on inside of them. And I think that's partially why we built Langsmith to help out with exactly that. We also needed to do better things like make the prompts more visible and make it allow for more customizability around that. And so we've tried to add some stuff there. In terms of balancing, there's also LangChain is pointless. I don't need a wrapper. I can just call the underlying API. I think if all you're trying to do is call the underlying API, then like, yeah, that's gonna be the cleanest and simplest thing to do. And we try to get as close to that experience as possible, but we're not optimizing for calling the API. We're optimizing for helping people build context-aware reasoning applications as easily as possible. And so there's some level of abstractions that you need to add in order to assist in that. Yeah, that's definitely a balance that's tricky to strike, but I think there's also some aspect of it. Like, I do think one of the big benefits that LangChain provides is a standard interface for language models so that you can switch between them. And this kind of gets into like an ORM debate, like are ORMs generally kind of like useful or not? And so I think in this case they are. I think there's probably a larger kind of like philosophical kind of like question about that [00:50:25]Swyx: that people have strong opinions on. Just the prompts don't transfer like you also mentioned. Yeah, yeah, there's that, yeah. [00:50:32]Harrison: And then between kind of like allowing for, I think one helpful thing that we did in terms of like distinguishing between basically the base interfaces and then more complex stuff is part of the separation around the docs is there's like the components piece, which has the model IO, the retrieval, the agents, the callbacks, things like that. And then there's all the use cases. And so I think like the use cases, because they are like these assembly of all these things in a particular order, they start to get more complex. And it's, you know, we try our best to kind of like make clear how you can configure things. But yeah, there's a lot of different options that you might want to configure. And so I think that split has kind of helped us internally at least. And I think externally as well, because we've heard good comments about the improved documentation. I think that's made it a little bit more clear. And then another thing, one of the things that we also released soon after, and we'd been thinking about a little bit is basically like a LangChain expression language, which allows for actual composability of pieces. So LangChain, I think, has always been very good about interchangeability. Let's ignore the prompting issues, but like you could always plug in like one LLM for another one. You could swap in one vector for another one, but the chains themselves haven't actually been super actually composable. Like we had the sequential chain, but that was a bit like clunky to use. And then we had a router chain, but that was a bit, you know, that was also a bit clunky to use. And so one of the things, and so there's a million different things to do, and we didn't prioritize that. [00:51:53]Swyx: I think after this, [00:51:53]Harrison: we definitely bumped it up and prioritized in priority. And luckily Nuno had been doing a lot of awesome work on it already, so it wasn't too much of a lift. But yeah, now there's this way where a lot of the chains that we've been releasing are written in this LangChain expression language where they're actually truly composable, and you can see what's going on under the hood. And it's basically, it uses kind of like the pipe kind of like terminology to coordinate things and move things around. So yeah, I mean, I think there were a lot of good points in those Hacker News things, and you know, we can't respond to everything, but we try to like look at everything and take everything seriously. [00:52:25]Swyx: You're being very diplomatic. But so first of all, I like the expression language. I think that that is the path towards sort of language agnostic LangChain kind of, or whatever, DSL. But also like, what was just kind of plain wrong or plain offensive, or like, I don't know, people can get very vitriolic sometimes on Hacker News. [00:52:40]Harrison: Yeah, I mean, I think the comments that I appreciated were the ones where they gave specific things. And I think the ones where they said, you know, LangChain sucks. Like, okay. Can't do much of that. [00:52:51]Swyx: Yeah, exactly. Verifacing on my question would be like, you're not the first and you won't be the last to have that kind of very intense scrutiny. What would be your advice to other people, other maintainers of projects for going through something like this? [00:53:03]Harrison: I would probably say, try to drill into like what is actually underlying things [00:53:08]Swyx: as much as possible. [00:53:08]Harrison: And if there is actual substance that's being delivered, whether you agree with it or not, like, I think that's valuable to know. And then for the other stuff, like try to maybe follow up, but maybe try not to let it get under your skin too much. [00:53:22]Swyx: Thanks for tackling that. [00:53:24]Alessio: And I know we're getting to the time and we'll wrap up soon, but since you're going to speak at the AI Engineers Conference, what's your advice to AI engineers, especially when to start with LangChain and when they're just experimenting with a model, [00:53:38]Swyx: when are they, [00:53:38]Alessio: as you mentioned, if you just want to do an API call, don't use LangChain. Yeah. [00:53:43]Harrison: I mean, my advice would just like build as many things as possible. Like, I think it's still really early in the space. No one really knows what they're doing to some extent. Like, it's a bit weird to say, but there's so many things to like discover. So I would just say like, build as many things as possible. Cause I think like the best thing is you stumble upon a really good idea and you build something really awesome. And the worst thing that happens is you just learn a lot about a field and the technology that's going to be incredibly important and rapidly kind of like changing. [00:54:11]Alessio: What would you build if you weren't doing LangChain? [00:54:13]Harrison: I mean, the things that are most interesting to me are kind of like things around like long-term memory and like longer running agents. So I'd probably build, and these are things that we've been wanting to build [00:54:23]Swyx: internally as well. [00:54:23]Harrison: But like, I think a chatbot that like actually remembers things about you as like silly as that sounds, like people like chatbots a lot and they have their delivered limited by their context window. And so I think really diving into like a specific application of memory there. [00:54:38]Swyx: I've been trying to build a chatbot [00:54:39]Harrison: that remembers things about you. That would be one. And then like, I know a lot of people are doing this, but like a personal assistant for like managing like email calendar, basic stuff, which I think is, I think that's like a fantastic application for these like agent like things, because if you think about personal assistants today, you usually interact, I don't have one, but I'm told you interact with them over email. And the nice thing about that, as opposed to like chat, there's not as stringent an expectation on latency as there is on chat. And so you can do a lot of things like reflection and kind of like making sure that you're on the right track and really put more safeguards and thinking about these agents as opposed to relying on like chas and interface, like the bot we have that's on GitHub answering questions on the issues, I think probably gives better answers than the bots that we have that are on chat on the website. And I think that's not because, there's just different constraints that you have in different types of problems. And I think I would be like, I think the personal assistant one's really interesting because you remove the constraint of chat, which I think at this point in time is probably pretty limited in terms of functionality. [00:55:43]Swyx: Yeah. I've been calling this sort of long inference. If you didn't have to care about ANC and you could take like a day, a month, a year to work on something, what could you do? And yeah, that's super interesting. [00:55:56]Harrison: I think that's a really promising place to explore. [00:55:58]Swyx: Yeah. Have you looked at, regarding the long conversation thing, you and I have tried it about this many times. Have you looked into what character and inflection are doing? Because they're probably working on it. [00:56:08]Harrison: I've thought about memory a bunch. Like I think it comes down to like, it comes down to like state, like what's the state you're tracking? Like what's the data structure for that? And I think that could also maybe be a bit like application specific. But if we're talking about a generic chat bot, that's kind of generic. I don't know. Yeah, I don't know how they're thinking about that. My sense is that inflection like thinks about that a bit more than character. Like I think in Inception, sorry, inflection's whole thing is they like, the bot knows you. [00:56:33]Swyx: It's one chat. There's no history. You just talk to it. Yeah. [00:56:37]Harrison: So they've definitely got some state that they're tracking. I'd be really curious to know what that is. Character, I don't think has lent into it too much. I think they let you do some stuff in terms of like uploading background. And I'm not entirely sure how they use that, whether they just like put that in the prompt or do some retrieval over that. But I think they're definitely, they haven't lent into it as much as inflection, I would say. [00:56:57]Swyx: So given like, you are one of the most interested people in this space, would this be like a second product for you? If you ever want to explore that or do you want to just partner with people and you're putting out the call for people to come to you if they have solutions for that? [00:57:10]Harrison: If I wasn't working on LangChain, I would be building an application company, for sure, first of all. Like, I don't think, like I think like there's, which I know is very hypocritical to say. [00:57:20]Swyx: Like you're Mr. DevTools and Infra and Observability. [00:57:24]Harrison: Yeah, I don't know. If you're building an application company that's working on something related to long-term memory or long-term agents, I would love to chat and just geek out [00:57:31]Swyx: about a lot of this stuff. I'll show you Smalltalk at some point. Yes. Cool. Awesome. [00:57:37]Alessio: Yeah, let's do a lightning round. [00:57:38]Swyx: So the first one is on acceleration. What has happened in AI that you thought would take much longer than it actually ended up taking? [00:57:45]Harrison: The function call and ability from OpenAI, like tool usage. [00:57:48]Swyx: Yeah. [00:57:48]Harrison: They did that really fast, I thought. [00:57:50]Swyx: Yeah. But it's just a question of fine-tuning, no? Yeah. It's not even like reliable. [00:57:54]Harrison: It's not terrible. They're a pretty big organization that's serving a lot of traffic. And like, this was a, yeah, it's like, it is like just fine-tuning, but I think like you still have to like collect that data set and fine-tune it and evaluate it and then release it at scale and figure out the right API. [00:58:09]Swyx: No shade on OpenAI. Like they're moving everyone's bar as to how quickly like a 400% organization can go. Do you think it eliminates like approaches like JSONformer and all the other approaches that people, like guardrails, you know, previous guest, eliminates your output validation thing? Yeah. [00:58:26]Harrison: I think JSONformer and stuff like that are still really interesting for like local models, for sure. And there's like 90% of people use OpenAI or something and like my made up numbers. [00:58:37]Swyx: No, it's probably real. [00:58:38]Harrison: And the best way to get structured output is by using the function calling ability. So yeah, absolutely. [00:58:46]Alessio: What do you think is the most interesting unsolved question in AI? [00:58:50]Harrison: I'm really interested like how multimodal is going to work. Like with just what that looks like. [00:58:55]Swyx: Have you had a look at the GPT-4 vision? No, not really. [00:58:59]Harrison: Yeah, not beyond what they- [00:59:01]Swyx: They're doing private betas right now. So I'm very excited. [00:59:04]Harrison: I'm excited about that as well. Yeah, I mean, I think that's, you know, you talk about like, again, this whole space is just changing so fast, but you talk about something that could like really change how, because like, you know, a lot of lang chain is kind of like a data orchestration tool in some sense. And so if you had a whole new type of data in there. [00:59:20]Swyx: So maybe we do this thought exercise, right? Tomorrow, OpenAI releases the GPT-4 vision API. What does lang chain do? [00:59:25]Harrison: Immediately we add support for it in like the wrapper. So however you interact, like honestly, this is another like fun thing. Everyone's API now looks like OpenAI's. [00:59:35]Swyx: Yeah, which is great. [00:59:36]Harrison: Which you have to do, yeah. So like our wrapper looks similar to OpenAI. So I don't think it will be that difficult to include support for it at the basic model level. And so we do that. And now that we've released the expression language bit, like a lot of the core chains, we have examples of rewriting them just in this expression language. So like for retrieval, if we're now talking about like, okay, you can do like retrieval question answering over for multimodal things, we'd probably have to figure out how those are getting stored and what's being done with them. But then from there, that should be, yeah, so probably looking to like, yeah, how are people kind of like storing and consuming this type of information? But then that step should be pretty easy to plug into the kind of like chain. [01:00:17]Swyx: Multimodal stores? Yeah, I don't know. I always wonder what that would actually look like because a lot of multimodality in LLMs is really just an LLM, a text LLM calling a different model. And that's just no different than any API call, essentially unchanged. [01:00:32]Harrison: I think it's probably something that you don't know until you let like a million people play around with it. [01:00:37]Swyx: Then there'll be new LangChain for multimodal. What's one message you want everyone to remember today? [01:00:43]Harrison: I would probably say just like build. I think it's a fantastic time to be building. [01:00:47]Swyx: All right, just build. Yeah. [01:00:49]Alessio: Thank you Harrison for coming on. [01:00:51]Swyx: Thanks so much. [01:00:51]Harrison: Thank you guys for having me. [01:00:52]Swyx: It's a lot of fun. [01:00:53] Get full access to Latent Space at www.latent.space/subscribe
Wed, September 6, 2023

RWKV: Reinventing RNNs for the Transformer Era — with Eugene Cheah of UIlicious
The AI Engineer Summit Expo has been announced, presented by AutoGPT (and future guest Toran Bruce-Richards!) Stay tuned for more updates on the Summit livestream and Latent Space University.This post was on HN for 10 hours.What comes after the Transformer? This is one of the Top 10 Open Challenges in LLM Research that has been the talk of the AI community this month. Jon Frankle (friend of the show!) has an ongoing bet with Sasha Rush on whether Attention is All You Need, and the most significant challenger to emerge this year has been RWKV - Receptance Weighted Key Value models, which revive the RNN for GPT-class LLMs, inspired by a 2021 paper on Attention Free Transformers from Apple (surprise!).What this means practically is that RWKV models tend to scale in all directions (both in training and inference) much better than Transformers-based open source models:While remaining competitive on standard reasoning benchmarks:swyx was recently in Singapore for meetings with AI government and industry folks, and grabbed 2 hours with RWKV committee member Eugene Cheah for a deep dive, the full recording of which is now up on Latent Space TV:Today we release both the 2hr video and an edited 1hr audio version, to cater to the different audiences and provide “ablation opportunities” on RWKV interest level.The Eleuther Mafia?The RWKV project is notable not merely because of the credible challenge to the Transformers dominance. It is also a distributed, international, mostly uncredentialed community reminiscent of early 2020s Eleuther AI:* Primarily Discord, pseudonymous, GPU-poor volunteer community somehow coordinating enough to train >10B, OPT/BLOOM-competitive models* Being driven by the needs of its community, it is extremely polyglot (e.g. English, Chinese, Japanese, Arabic) not because it needs to beat some benchmarks, but because its users want it to be for their own needs.* “Open Source” in both the good and the bad way - properly Apache 2.0 licensed (not “open but restricted”), yet trained on data taken from commercially compromised sources like the Pile (where Shawn Presser’s Books3 dataset has been recently taken down) and Alpaca (taking from Steven Tey’s ShareGPT which is technically against OpenAI TOS)The threadboi class has loved tracking the diffusion of Transformers paper authors out into the industry:But perhaps the underdog version of this is tracking the emerging Eleuther AI mafia:It will be fascinating to see how both Eleuther and Eleuther alums fare as they build out the future of both LLMs and open source AI.Audio Version Timestampsassisted by smol-podcaster. Different timestamps vs the 2hr YouTube* [00:05:35] Eugene's path into AI at UIlicious* [00:07:33] Tokenizer penalty and data efficiency of Transformers* [00:08:02] Using Salesforce CodeGen* [00:10:17] The limitations of Transformers for handling large context sizes* [00:13:17] RWKV compute costs compared to Transformers* [00:16:06] How Eugene found RWKV early* [00:18:52] RWKV's focus on supporting many languages, not just English* [00:21:24] Using the RWKV model for fine-tuning for specific languages* [00:24:45] What is RWKV?* [00:33:46] Overview of the different RWKV models like World, Raven, Novel* [00:41:34] Background of Blink, the creator of RWKV* [00:49:55] The linear vs quadratic scaling of RWKV vs Transformers* [00:53:29] RWKV matching Transformer performance on reasoning tasks* [00:54:31] The community's lack of marketing for RWKV* [00:57:00] The English-language bias in AI models* [01:00:33] Plans to improve RWKV's memory and context handling* [01:03:10] Advice for AI engineers wanting to get more technical knowledgeShow NotesCompanies/Organizations:* RWKV - HF blog, paper, docs, GitHub, Huggingface* Raven 14B (finetuned on Alpaca+ShareGPT+...) Demo* World 7B (supports 100+ world languages) Demo* How RWKV works in 100 LOC, RWKV overview* EleutherAI - Decentralized open source AI research group* Stability AI - Creators of Stable Diffusion * Conjecture - Spun off from EleutherAIPeople:* Eugene Chia - CTO of UIlicious, member of RWKV committee (GitHub, Twitter)* Blink/Bo Peng - Creator of RWKV architecture* Quentin Anthony - our Latent Space pod on Eleuther, coauthor on RWKV * Sharif Shameem - our Latent Space pod on being early to Stable Diffusion* Tri Dao - our Latent Space pod on FlashAttention making Attention subquadratic* Linus Lee - our Latent Space pod in NYC* Jonathan Frankle - our Latent Space pod about Transformers longevity* Chris Re - Genius at Stanford working on state-space models* Andrej Karpathy - Zero to Hero series* Justine Tunney ("Justine.lol") - mmap trickModels/Papers:* Top 10 Open Challenges in LLM Research* Retentive Network: A Successor to Transformer for Large Language Models * GPT-NeoX - Open source replica of GPT-3 by EleutherAI * Salesforce CodeGen and CodeGen 2* Attention Free Transformers paper* The Pile* RedPajama dataset* Monarch Mixer - Revisiting BERT, Without Attention or MLPsMisc NotesRWKV is not without known weaknesses - Transformers do well in reasoning because they are expressive in the forward pass, yet the RWKV docs already note that it is sensitive to prompt formatting and poor at lookback tasks. We also asked pointed questions about RWKV’s challenges in the full podcast. Get full access to Latent Space at www.latent.space/subscribe
Wed, August 30, 2023
Cursor.so: The AI-first Code Editor — with Aman Sanger of Anysphere
Thanks to the almost 30k people who tuned in to the last episode!Your podcast cohosts have been busy shipping:* Alessio open sourced smol-podcaster, which makes the show notes here! * swyx launched GodMode. Maybe someday the Cursor of browsers?* We’re also helping organize a Llama Finetuning Hackameetup this Saturday in anticipation of the CodeLlama release. Lastly, more speakers were announced at AI Engineer Summit! 👀~46% of code typed through VS Code is written by Copilot. How do we get closer to 90+%? Aman Sanger says we need a brand new AI-powered IDE to get there; and we’re excited to be the first podcast ever to tell the Cursor story.If you haven’t heard of Cursor, you may have been living under a rock. Here are just some of the rave reviews going around in the past week alone:* “Cursor is the best product I've used in a while” - Alex MacCaw* “Someone finally put GPT into a code editor in a seamless way. It's so elegant and easy. No more copying and pasting.” - Andrew McCalip* “Coding with AI is getting insane.” - Mckay Wrigley* “This is mind blowing 🤯” - Linus Ekenstam* “Cursor + gpt4-32k = illegal levels of productivity” - Sully Omarr* “EL MEJOR EDITOR DE CÓDIGO con IA” - Carlos SantanaA decade ago, “platform risk” meant building apps on social media platforms was risky as you could get cut off from the social network. Today, the AI version of “platform risk” is building AI products within an existing product (like an AI extension for VS Code, or a Figma plugin). Since Copilot, a generation of VSCode plugins have launched (including Cody, Cosine, and previous guests Codeium and Codium), only to be challenged by Copilot X itself.A core AI Engineering thesis is that new capabilities in AI demands new innovation in AI UX (and that AI UX can actually be a viable moat). Take VS Code for example; when Github was first working on Copilot, there was actually no way to support the “ghost autocomplete” feature we all use today. They eventually convinced the team to build it, and Copilot’s success speaks for itself.If you’re a startup building on top of VSC today, you do not have the same access and influence on the roadmap. Your UX is limited to what they allow you to do, and often that caps your ability to successfully compete against them. Since Cursor owns the whole IDE, they can do things you can’t (yet) do in VSCode:Cursor’s GameplanCursor is competing head to head against VS Code by forking Microsoft’s IDE and building their own AI-powered version. A few of Cursor’s unique features:* Native chat: Chat is a core piece of Cursor. Users can choose between GPT-3.5 and GPT-4 to ask questions and receive answers based on their code.* “Mentioning” files: you can easily add files into your request context by using “@”; this works both for code as well as documentation. If you want to do a change that includes multiple files, you can include them in your question to make sure the change is reflected in all of them.* Custom prompting engine: Cursor built Priompt, their custom prompting engine. As your chats go over the context window size, Priompt figures out which messages to keep in the history, which files to drop from the prompt, etc. * Moving beyond typing: while IDEs are familiar to folks as today’s interfaces, in the future Cursor hopes to have agents you can delegate tasks to. Instead of a back and forth on a new feature or bug fix, you can ask it to do the whole thing for you end to end.After diving deep into Cursor we nerded out on model usage, training, quantization, and evaluation. There’s a ton of great content in this episode, we hope you’ll enjoy it!As always, feedback welcome in the comments, and tag us on socials for future guest suggestions!Show Notes* Cursor* Gary Marcus’ cubes prompt* Priompt* “Humans should focus on bigger problems.”* Codium AI on Latent Space* Rift from Morph* Sourcegraph* E2B* Repl.it* HungryHungryHippos, Hyena, etc (see our FlashAttention episode)* Aman Tweets* Why GPT-3.5 is (mostly) cheaper than Llama 2* Llama’s architectural limitations* “Training will look like researchers/practitioners offloading large-scale training jobs to specialized “training” companies: a state of the world that resembles chip design & fabrication.” - Mosaic prediction* “The size of all code/history on Github public repos is 92TB. The size of Google's monorepo in 2015 was 86TB (of much higher quality code). If Google were willing to deploy code models trained on their own data, they'd have a noticable advantage over everyone else.” - May 2023Timestamps* [00:00:00] Intros* [00:02:31] Developing CAD models vs coding models* [00:05:23] Deciding to build a new IDE optimized for large language models* [00:10:50] Getting early access to GPT-4 and realizing its potential for software development* [00:12:32] Rethinking the UI/UX for coding* [00:18:24] Cursor's features like system prompts and chat* [00:22:24] Tips for prompting GPT-3/4 for code generation and editing* [00:27:24] Cursor's documentation and context features* [00:29:30] The potential of coding agents like Code Interpreter* [00:38:23] Cursor's internal prompting tool Priompt* [00:40:47] The challenges of very long context lengths for models* [00:45:44] The compute costs for prompt tokens vs. completion tokens* [00:49:36] How quantization interacts with model utilization* [00:51:24] Issues with human eval for benchmarking code models* [00:53:12] Thoughts on training models vs. relying on foundation models from big providers* [00:55:34] The origin story of Cursor's parent company AnySphere* [00:56:00] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO at Residence at Decibel Partners, and I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: Hey, and today we're back in the studio again after a little break and we have Aman Sanger in the house. Hey Aman. Hey, thanks for coming. Thanks for having me. So I wanted to introduce our guests and then have you fill in the blanks. So you worked at Gamelon, Bridgewater, McKinsey, Google, and You.com, all on sort of kind of AI related things and some finance related things. You also ran your own consultancy, Abelian AI, and you graduated in CS and math from MIT recently. Worked on a few projects, including Instill, which I think we'll cover a little bit later, and most recently Cursor.so, which we'll cover for the vast majority of the podcast. But just on a personal side, what's one thing that people should know about you that, you know, might not be so obvious on LinkedIn? Oh, interesting. [00:01:01]Aman: In a previous life, I played a lot of squash. [00:01:05]Swyx: You were a top seed? [00:01:06]Aman: Yeah. So in high school, I kind of competed in tournaments and most people probably don't really know what squash is. It's like tennis in many ways. It's like a racket sport, but it's indoors. You play against a wall. I guess now pickleball is all the rage with, with racket sports, but yeah, the story is I used to play tennis and then I moved to a building that had a squash court in it and then I picked it up. I loved it. And I've been playing ever since. So I competed a lot in high school, played a bunch at FIT, have not had the chance to play much here. In San Francisco, there aren't too many courts. [00:01:38]Swyx: We can organize a squash tournament and then you'll crush it, of course. Is there anything about the athlete mentality that you take with you as a founder? [00:01:47]Aman: Yeah, I think it can be at times a bit too much, but I'm very competitive. I really hate losing. Now I think I'll go on runs and if someone tries passing me, I won't let it happen. I'll just kick it into overdrive and maybe I'll turn the corner if I know they're going to beat me, but I can't let someone pass me when I'm running. And I think the same is true with starters, where the competitive nature, I think it in general helps motivate me and makes me, I guess, just work harder. [00:02:17]Swyx: Yeah. Okay. Well, we'll have a bunch of competitive questions later, but we'll go over the timeline. [00:02:22]Alessio: Let's jump into how you got to Cursor. So in August 2022, you launched something called Instill. Can you talk a little bit about that? [00:02:31]Aman: Yeah, and maybe before I go into Instill, I should talk about what I was even doing before that, because Instill was actually a very brief foray from what I was doing with my original co-founder, Michael. So we had both actually gone to the same high school together, gone to MIT together. And then after graduating, we knew we wanted to start something. And in June, what we were working on was also called Cursor, but very different. We basically were very, very fanatical users of Copilot. We loved it. And we had a little bit of experience with computer-aided design or CAD software. A lot of our friends, in fact, were mechanical engineers. And we'd heard a lot about how tedious it was to just design these parts and software like SOLIDWORKS and whatnot. It was pretty obvious to us that if you could train a transformer on the task of predicting the next token, not just for code, but for CAD, then you could get a really useful product that could speed up mechanical engineering. So that's actually what we'd worked on up until Instill, even a little bit after Instill. And yeah, I can go into more detail about that. It was pretty interesting. That's probably how, despite these days doing less stuff with model training than in the past. For that, it was all just kind of rolling our own models from scratch, a lot of training, a lot of inference. [00:03:48]Alessio: I'm always curious to hear about what made you interested in that. Obviously, you've been at the forefront of a lot of this AI work. Why was that the most interesting thing to you? Did you think there were not as many people going after that? Did you think you had a unique insight into it? Because we got a lot of people listening that want to be founders and want to figure out how to make that decision. [00:04:09]Swyx: Yeah. [00:04:10]Aman: First off, I've always been incredibly fascinated by AI. The first time I originally learned how to program, actually, because I'd seen the results from ImageNet and I'd heard deep learning, and that just sounded insanely cool to me. And so my first programming project was building and training a neural network in Java, because that was the only language I knew from my AP Computer Science class. But ever since then, everything I've done has been involving ML, AI. The reason I wanted to, I guess, found a company is, first off, I had been working with Michael on a couple of other things. We'd done an AI consultancy in the past. We worked really well together and really just enjoyed working on stuff on our own. With CAD, we were doing a little bit of ideation, and I think we were quite worried about competition in a lot of other areas. I think that worry has definitely subsided a little bit with what we're working on now, obviously. A lot of competition in the coding space. But it seemed like the kind of thing where not a lot of eyes were on this. It seemed very technically possible, at least at the time. And the market was pretty sizable, if you looked into it. So it was both a really interesting technical problem. And then if you just tried to analyze the space, it seemed like a good idea. [00:05:23]Alessio: How do you decide to move off of it? That's another important answer as a founder. [00:05:28]Aman: I think there are a few key things that we did not take into account when we were working on this. One was if you look at the original Codex paper, our assumption was this is the model that powers Copilot. It was trained on 100 billion tokens, or it was something like 50 billion tokens of Python. And one interesting insight from it was that you actually get no transfer benefits from the pre-trained model on text to code. So that means they took GBD3, and for the smaller models, for the models that weren't trained in all the Python data, there were some benefits where GBD3 transferred really well faster. But then for the final Codex model, it turns out that there were no transfer benefits, meaning you just took a model, you trained it from scratch on those 100 billion tokens of Python code, it would do just as well as the GBD3 12 billion model that was fine-tuned. The issue was that it was only true for GBD3 and 100 billion tokens of Python code. These days, I mean, the jury's still out on this, but it seems pretty clear that the benefits from learning language are quite helpful with code. I guess that kind of goes into the issues with CAD, where one, you're dealing with much less data than code. If you assume, first off, that 50 billion, 100 billion tokens is all you need, then maybe with like 10x less, you could get a pretty useful model. In reality, Copilot today is powered by probably trillions of tokens of code, as well as text. And when you're dealing with, at most, from scraping every single bit of CAD data, you can find 10 billion tokens. It's just not enough to train a useful model. We tried scaling, and no matter what kinds of regularization techniques we used, we just couldn't get it past a few billion parameters without overfitting. That was the big thing. And then the other is that there's no transfer. If you try to test these models today, and even with GBD4, there's a prompt that I like to use, which is good for testing like 3.5 versus 4 if you don't know which one's behind the scenes. But even 4 sometimes struggles with it. And the prompt is you kind of lay out, I think it's like a famous kind of Gary Marcus prompt as well, where you lay out a bunch of kind of cubes on a table, right? And you describe it, and as you increase the complexity, you know, 3.5 drops out, you increase the complexity more, 4 drops off. But it's clear that these models are not that good at spatial reasoning, and that's exactly what's needed for CAD. [00:07:52]Swyx: Oh, yeah, that's right. [00:07:54]Aman: What you want to do is if I were to design this table with CAD in front of you, I would first draw a rectangle, then I would do an extrusion operation, which would basically take the rectangle and then extend it orthogonal to the plane, such that it's like a volume, [00:08:14]Swyx: right? [00:08:15]Aman: And then the model has to realize that, okay, the shape now that exists is this structure here, this table. And then the really difficult thing is for other operations, it'll need to point to the constructed geometry that was built. And basically, the model effectively to work well, it needs to kind of, in its mind, imagine this 3D structure. And the models are not good at that. If you try fine tuning code models on this task, or language models, they're just not going to transfer well at all. [00:08:44]Alessio: Do you think in like two, three years, there will be a good AI-powered CAD software? [00:08:47]Aman: Yeah, my perspective now is that I think the best way here is probably redesigning the entire system. One other big pain point was we tried to build plugins with all the major pieces of CAD software, like SolidWorks, Onshape, and so on and so forth. And if you think it's hard to build a plugin for some of the older IDEs, you've not seen these pieces of software. And so I think even if you got a good model, it might be really hard to actually get distribution and create a good plugin that works. So it feels like with the advancements you have in kind of text to images, and there's some new companies kind of doing stuff with text to 3D, it feels like the reasonable approach is actually just scrap the way that people are doing CAD right now. And I suspect a company or some companies will come around and do this quite well. [00:09:37]Swyx: That's really good insight. And we have more sort of general LLM products thoughts to ask you at the end. We wanted to get into Cursor, since that is your primary product right now. In January 2023, you announced it to the world. Maybe take us into the, I guess, idea maze leading up to Cursor. [00:09:54]Aman: Yeah, I guess it still was one kind of brief, brief pivot period where we tried doing text to images. The reason we decided against it was that I don't think we're the founders for that kind of company. We learned this from CAD, and we strongly believe this now that it is much better to be a user of the product you're building. And we just weren't big users of any of the text to image tools. So it was around December where we managed to actually get early access to GPT-4. And before then, we had played around a little bit with using earlier versions of 3.5 on writing code. And we kind of given up. It just seemed like if you looked at Text DaVinci 2 or Code DaVinci 2, those older 3.5 variants, they just couldn't really do anything meaningful. But then we opened up the playground, started copy pasting code into there. And it was ridiculous. This is before everyone started using human. [00:10:50]Swyx: Did you use the early version? [00:10:52]Aman: Yes. So, okay. [00:10:54]Swyx: So, it was an earlier version. The unhinged raw. [00:10:56]Aman: Oh, it was still, no, it was still, it wasn't, yeah, it was still very safe. But before people started using, human eval was the thing, but before everyone started talking about it and knowing about it, we kind of pasted it in and it got 85%. And we were just like, wow, best open source model at the time got 30%. And Code DaVinci 2 got something like 47%. And yeah, GPT-4 today, it gets about the same score. And so we then started, you know, writing code in there, just copying and pasting random pieces of code from whatever kind of things we were testing and developing. We found that it was not just good at creating net new things, but refactoring code, editing code, helping you debug kind of every single aspect of software development felt so different with these models. And then we kind of, in our heads, just plotted out the future. And this is GPT-4, like what happens when you have 4.5, GPT-5? These models are just going to get better and better and better at programming. And the future is probably not going to be more and more things that you tab enter for autocomplete. I think that's a very useful tool. We use Copilot every day. We find it quite useful, but you can't have a world in which language models are able to produce 90%, 95% of the code, and it still follows that form factor. I think you have to redesign the entire way, the entire UX of writing software. And that was our take with Cursor, where you need to own the full IDE and completely redesign the flow of producing software and just doing software development in general. [00:12:32]Swyx: Those are big statements that we need to dig into a little bit more. I want to backtrace a little bit. So you got early access to GPT-4. That actually means that you were backed by OpenAI, you joined OpenAI Fund before you were Cursor. [00:12:46]Aman: Yeah, basically. Kind of. [00:12:48]Swyx: Oh, okay. Because I'm trying to get the chronology and I assumed you were, they funded you because of Cursor. [00:12:52]Aman: Yeah, so OpenAI is this program Converge. That was the program we participated in. And through that, the main thing was early access to on-release models that we got to play with. Obviously, none of this went to production. None of this could go into production. It was just kind of a sneak peek of GPT-4. And so, yeah, before we actually built out Cursor, we didn't take money from OpenAI, but we were a part of this program. [00:13:14]Swyx: Got it. Yeah. And then you also mentioned one more thing, which was interesting. You still use Copilot, but you also use Cursor. Yes. You also mentioned that Copilot is probably trained on trillions of tokens, which means that's extensive training since the original Codex. That's my guess. [00:13:30]Aman: I mean, if you look at the stack, for example, right? It's what? One to two trillion tokens? Something around that. I'm very skeptical that Copilot is training on less, especially with all the lawsuits you see with whether or not it's quote-unquote fair use. [00:13:43]Swyx: So yeah, my guess is trillions of tokens. [00:13:44]Aman: I don't really know. But yeah, I'm sure if you did the math on how much public code there is in GitHub, it's almost certainly the trillions. [00:13:52]Swyx: One of the reasons I harp on this is one of our pet themes is tracking the dataset to parameter ratio. And Copilot cannot be that big because it returns relatively quickly. So it's going to be in the low billions, right? So how do you do trillions of tokens to the low billions? That's interesting. Yeah. [00:14:12]Aman: I think I have some thoughts on this because there's the whole thing with chinchilla scaling and then people are now saying, oh, chinchilla scaling doesn't matter because of inference. But Copilot could be a mixture of experts. That's one other speculation. I don't know if that's true. I mean, it probably wasn't the case at least a year or two ago. My guess is it's probably a small model that's very over-trained. From what I've heard, there are also lots of tricks you can do with caching where even if the model is quite big, it doesn't take, it effectively takes no time to ingest the entire prompt. Yeah. [00:14:46]Swyx: Semantic caching is what they are calling it, right? I guess if it roughly embeds to the same thing, just return the same thing. [00:14:50]Aman: I think it's partially that, right? Where let's say the suffix or the code before where your cursor is has changed slightly. They might not actually go ahead and use a different... [00:15:02]Swyx: That seems dangerous for code. [00:15:03]Aman: It does seem a little dangerous, but it gives you this like incredibly snappy response. And the other thing is the KV cache, right? Where you can just, I don't think there's any open source framework that does this right now, but what you can do is if you've already computed something over the KV cache, then you can just... [00:15:19]Swyx: This is the attention KV cache for people following. [00:15:21]Aman: So this is the attention KV cache, right? And if you've already computed all the keys and values, you can just store that in memory and then load that back up in the GPU and you don't need to process the prompt again. And I speculate they're doing something like that behind the scenes. [00:15:35]Swyx: That's a lot of memory. That's a lot of story. It is. [00:15:38]Aman: Well, unless they're using something like multi-query attention or... [00:15:41]Swyx: Yeah. We'll talk about that in your Llama 2 piece. And then the final big opinion that you drop in there was you must write your own IDE as opposed to write a VS Code extension, which there's plenty of them out there. SourceGraph is doing one and I've been working closely with Morph, which just put out Rift. So this is obviously a big undertaking. Maybe explain more a little bit about why build your own IDE. Yeah. [00:16:05]Aman: The reason we decided to do this is I think in the future, today, what Cursor can provide and what any of these tools can provide isn't that much different than, I guess, what you get in VS Code. But it was more of a long-term decision where in the long term, you're going to need to design just a very different UX that the extensions don't give you. One story we'd heard is that with Copilot, in order to actually get the multi-line ghost text implemented, it wasn't actually a part of the extension. I think the team at GitHub had to call up VS Code and have them make a change to the source in order for that extension API to be enabled. That's what allows for multi-line ghost text completion. And this is scary. If you look today, there are other things that VS Code in their source code has enabled as APIs that are just closed off to everyone but Copilot. So I think there's this fundamental platform risk where you're competing with the incumbent that owns the platform you're building on. And we thought it would just not really be tenable in that sense. And then the other thing is if you want to do other kind of fancy things. So one example of a feature we're kind of building right now is instead of just... So Copilot is great for completing the next line, completing the next few lines, but what if you wanted to do a kind of sort of edit, where instead of just completing this line, it changes the line above or delete something. There's no way that you can do something like that in VS Code, but we have the UI for this that we've kind of built out in Cursor. We're currently training models in order to get it to work well. But again, this is a feature that we think once we get it to work, will be quite useful. Could be on par with Copilot level in terms of usefulness. And it's just fundamentally impossible unless you own the IDE. There are a lot of other ones like those that we're kind of cooking up. And then there are small things. I do think like in terms of inline edits, which means inside the editor, you can press command K in Cursor and then ask for some kind of modification of the code or ask for a generation of the code. And I do think we have probably the best UX for that because if you look at what someone like Sourcegraph does, I mean, Sourcegraph code is a great product, but they basically have to use the GitHub pull request comment feature in order to do it. And I think like these paper cuts kind of add up over time. [00:18:24]Swyx: They do. And it's very impressive how quickly you can try it out, you know, obviously encourage everyone listening to try out Cursor. And the download is really quick. The binary is super small. And then when you spin it up, it boots up really fast. And it's just a text file that guides you through the tutorial. It's really, it's really great. [00:18:39]Alessio: I was using it today. Actually I will open right now. The first thing I like, you guys have like bring your own keys. So that's like one of the things that I don't see in enough products, like bring your own API key instead of like sign up for an account and do all of that. [00:18:54]Swyx: Well, so like you have to trust them that they won't. [00:18:56]Alessio: Look at this guy. [00:18:59]Swyx: I just wonder if like OpenAI could do one more thing, which is just, you know, do a limit, the spend limit per key. So like that leaves space for like other companies to come in and do that. But I mean, OpenAI could just build it tomorrow. [00:19:10]Alessio: I saw Logan tweeted about whether or not it would be interesting to have per key billing. [00:19:15]Swyx: I mean, I think that would be. They're clearly thinking about it. [00:19:17]Aman: Yeah. They have more important things like GPD 4.5. We can talk about that one. [00:19:20]Swyx: Yes. [00:19:21]Alessio: Let's talk a bit about what you do. So first of all, unlike some of the other tools, you guys have like a system prompt kind of thing, which are like rules for AI. What was like the decision behind that? Did you see people being frustrated with always having to repeat the same thing in the prompt? [00:19:38]Aman: Yeah. The problem was for encoding some small rules that the model will tend to get wrong. So for example, we use Solid instead of react. [00:19:46]Aman: Solid is just another reactive UI framework. It's a decent bit faster. And my co-founders know a lot more about the details in this than I do. But like the other really nice benefit is that with the VS code fork that we're using, you can kind of inject solid into multiple routes. While react is meant to be kind of like it takes over the very root of the entire DOM. Solid instead, you can inject it inside of like multiple HTML components. It's much more performant that way. And so yeah, we use solid because of that. And then the issue is every time you create a TSX file, write a component, GPD 4 by default will assume it's react, right? And so it'll get the code wrong. And so just encoding rules like that are pretty helpful on the side of that problem. For some of our users who are less familiar with English too, it's helpful to kind of add a prompt to say describe this in whatever language they're most comfortable with. [00:20:45]Swyx: And so for those who don't know, you primarily, the main model for most people is GPT 3.5 and pro users can use GPT 4. You're prompting GPT 3.5 with these system prompts first. Any other tips apart from your company specific ones, apart from the English as a second language ones, how do you prompt GPT 3 or 4 for code? [00:21:05]Aman: So this is interesting because I think in general, these models are good at just producing net new code or rewriting code from scratch. The thing that they're not great at is producing edits or modifications. So producing a diff is incredibly painful. And I'm sure you guys may have encountered this if doing stuff with agents, but they just get line numbers wrong pretty often. And when you're producing a diff, you know, it's fewer tokens of compute. And there's, there's some theories that like, you know, the more tokens of compute you kind of use up, the more the model is kind of expending on thinking, thinking, yeah, chain of thought. That's one thing we've kind of struggled with. And so that takes probably chaining to get it to work well, where one kind of technique we do is we have GPT 4 kind of propose a draft PR and then we have 3.5 go and kind of heal a draft diff and then we have 3.5 go and go and heal those changes. So you'll have to do things like this in order to get it work around those limitations with edits. In terms of general code writing, I think with 4, it's just, it's been super, super straightforward. 4 is fantastic. 3.5 would strongly recommend using the Azure model because there you get access to completions, meaning you can put kind of words in GPT 3.5's mouth and let it finish it. Kind of like what you can do with Claude. And that's really helpful. [00:22:24]Swyx: I always assumed that was going away as a API because OpenAI is like clearly not interested in maintaining that. I mean, they're straight up deprecating it now. Yeah. [00:22:33]Aman: It's a little frustrating because I think it's really useful for code, right? Because when you can do stuff in the middle of the line, it's impossible to do that with the chat format. But with the completion format, it becomes trivial. [00:22:46]Swyx: So one thing I learned from working with Jesse on GPT 4 OpenAI, he always asked GPT to comment your code before writing the code. And that's the chain of thought for code, right? So when I ask you for code, give me a fully commented code with only a brief explanation on how it works, bias towards the most efficient solution and offer an alternative implementation if it fits. If it's unclear what environment or library versions I'm working with that might significantly change your answer, please ask me to clarify. That's my custom instructions right now for code. And I'm just like, hey, we should come together as a community and just share these custom instructions or system prompts. Yeah. [00:23:18]Aman: When you get it to be more verbose, I do worry a bit in terms of UX because more tokens means it takes a lot longer to get to the answer. And then it's also just, I don't want to read a massive answer. I just often want the answer immediately, or I just want kind of a short block of code to answer that. That is a trade off you kind of will have to deal with. And the same thing with diffs, right? Where the diffs are going to be so much faster if you get them to work, but it's just going to result in lower quality edits. [00:23:47]Alessio: One nice thing you do in the chat is actually remove some of the code you don't touch. So I was using it to make some changes to the code base and in each function, it would say like add a comment with existing code and then tell you just the stuff to change and the stuff to add to it, which kind of frustrates me with gbt4 sometimes. It just re-gives you the whole function definition instead of just that. I noticed that in the chat, you can now apply change and put it into the code if you don't start the conversation from the file itself. Why is that so hard? Like so many products have it. Is it actually hard or is it just like a UX decision to have you? [00:24:24]Aman: So there are two ways of doing that, right? So when you say apply change, do you mean you select a region in the code, press the button and then it makes it just like, makes it in? [00:24:33]Alessio: Right here, it told me to like add these three lines of Python and I'm like, I don't want to copy paste them. You know, I did it, but it would be good to just do. [00:24:40]Aman: So if it just makes the change for you. Yeah, this is something we're going to be adding this week. So yeah, this is definitely like something a lot of users have asked for and it should be reasonably straightforward to do. I think the issues we want to use for sparingly because of how expensive it is and 3.5 actually kind of struggles with this. [00:24:59]Swyx: Interesting. [00:25:00]Alessio: And then I noticed, so you can chat either with or without context. So with context, you pass it parts of your code base without, you don't. Every time it loads the license file. So is there anything that you're working on to make sure that like you don't have like license infringement and stuff like that, or is it just like the model for some reason thinks the license file is really important? [00:25:22]Aman: Yeah, right now it probably uses vanilla embeddings. We're working on a couple of interesting techniques for much better retrieval. One of them is basically fine tuning a model to kind of memorize a code base. So there was a paper that came out a little while ago from Google, which is called documents or it's called transformers as a differentiable search index. The idea here is you train a transformer on a code base or you train it on a corpus of documents in order to basically directly answer questions about which document is relevant given the question. So the mapping would be some query, some question, and in this case, a question about a piece of code. And then the model would directly output the not just file, but let's say the actual function or the class that solves it. It wouldn't output all the code for it, but it only just output like the symbol that corresponds to it. And we've seen some initially promising results with this direction. If you look at the original paper and then there are some follow on work, it actually does a lot better than very old school retrieval techniques like BM25 and even embedding based techniques. And so this is an approach we're experimenting with and we think it could prove quite helpful. The other direction is just improving embeddings. If you looked at the recent paper by, I think it was Alibaba. So there was a recent model. If you do the math, it costs them $1,000, less than $1,000 to train this thing. And it beats OpenAI on non-code related tasks, sadly non-code related. OpenAI still kind of holds the crown for code related embeddings. But we think there's some promise in potentially training our own embeddings and then fine tuning it on particular code bases so it performs better there. So these are both directions. We're kind of independently exploring to improve the performance of retrieval. But in the short term, we do have the ability to use kind of re-rankers and more kind of advanced tuning. So if you look in the chat, I think there may be a button you can click which lets you enable re-rankers, which should improve the performance a decent bit. [00:27:24]Swyx: Awesome. [00:27:25]Alessio: Anything else in the product that we're missing? We have inline generation and inline question asking to the model. You have the chat interface on the right. Yeah. [00:27:36]Aman: So one thing that our users have found quite helpful is being able to add files or add documentation. So if you want to add Next.js docs, the most recent docs, you just do add Next.js in the chat or in command K and you'll be able to then basically get that information in your context. We have a lot of features that will be coming up quite soon. One that we're quite excited about is basically code interpreter style mode of using the chat. And so I don't mean that, I guess, in the traditional sense of code interpreter. But code interpreter is probably the one example of, as far as I know, the one example of an agent that works really well, that has some sort of kind of product market fit. And I think the reason it works super well is because when you try to get agents to do some massive task, I don't know, many people who like reviewing PRs or reviewing large diffs, it's much more fun to kind of be in flow. And I think the way that the code interpreter is able to deal with this is it breaks it down to these kind of small units that are very auditable and understandable. When you ask the model to produce a graph, you just see the graph and then you can kind of tell more or less it's wrong. And then you can go and see the code and the code's very understandable. So I think it's pretty important to kind of have the agent do these very small, discrete units and then show the output in a way that's very easy for the user to understand and then go in and fix. And so we're building a kind of flow like that in the chat that should be coming out in the next two weeks, which we're very excited by, because we've done a bunch of experimental stuff with agents. And the big thing has always been this problem where it just produces a bunch of code and it's just so hard to tell whether or not it's correct or not. It's less efficient because it'll end up having some bugs. And then it would have been better if the user just went and wrote all of it themselves. [00:29:30]Swyx: There's one approach with a former guest of ours, Itamar, on Codium, whose essentially approach is you need to develop the spec, the tests, and the source code in harmony kind of together. Well, the spec is the prompt, and then the spec could generate a test or a spec could generate code. And the only way to validate the code is to run it with tests, is kind of his analysis of what the agent space, what the code agent space may look like. [00:29:54]Aman: I think tests are pretty promising a direction. If you have a really, really rigorous set of tests where you can completely confirm whether or not the agent has done the right thing, I think that solves it. But I think it's only one part of the overall puzzle here. I do think you're going to want the model to... Like the issue is, it's really kind of painful to go and write this massive, massive prompt describing everything. I want to be able to kind of do it in flow and just see a change, then go step by step from there. I think that's just a more fun way of doing it. I think the more fun and more easy to use kind of product will win, assuming the capabilities are about equal. So that's kind of our bet here. Yeah, that's great. [00:30:34]Swyx: Have you thought about like, so you said you can add docs, which is really cool. And I've thought about this before, but I always get hung up on versioning. You just choose to not care about it and just embed the most current docs? Yes, we embed the most current docs. [00:30:46]Aman: You can add whatever docs you want, if you just have a URL. You can paste the URL for the docs in. [00:30:53]Swyx: You give a crawler, yeah. [00:30:54]Aman: We crawl it in the background and embed it. And so you can have a custom, basically a custom version or whatever version you use. It's stored locally for you. What kind of crawl diff? [00:31:05]Swyx: Like if you've just written... Yeah, that means you've written a search engine, kind of. [00:31:10]Aman: It's very, very basic. Docs are very, very easy to crawl relative to other things because it's like, they're all like this kind of sort of markdown-like format. [00:31:19]Swyx: Yeah. [00:31:20]Aman: Definitely have not written a crawler for the entire net. [00:31:23]Swyx: The other thing on Code Interpreter, we've also done an episode on that. I'm very excited about it. I think it's GPT 4.5, you know, because it's GPT 4 that has been fine-tuned on more code. Yeah. Plus it has inference time capabilities that you cannot do in the traditional LLM setting. Anyway, the most important thing about GPT 4 is that it has the sandbox. So the main question for you is, are you going to run the sandbox in your environment or do you want to run it on our local machine since you have access to that too? Yeah, I think we want to be very careful with this. [00:31:52]Aman: You don't want to do sudo rm-rm star or something. Our plan is to run it on the local machine, but always kind of prompting the user whether or not they want it. I think if we want to do things where the agent takes many... So for the Code Interpreter style thing, the great thing is because you're breaking it down to these units, you can kind of batch together a bunch of commands at each step, just kind of ask the user because they're always kind of watching. For agents that are running completely in the background, I think there you probably will need to have some kind of contained environment where it's safe for agents to execute arbitrary code. One pretty bad attack is if one team wanted to, let's say, prompt inject the model, they could just kind of in a piece of code, just like have a comment that said something like, When you're doing this kind of edit, you should do rm-rf or do something really, really dangerous. And then the issue is if an agent is kind of running in the background, and then it does that, and it grabs that piece of information, and then it gets actually successfully prompt injected, it'll just execute that thing. The same actually may be true with documentation, where someone malicious, if they had access to some piece of documentation that other people use, could try to prompt inject agents that are then going and running code and running terminal commands. [00:33:06]Alessio: Today, people just hijack npm packages. [00:33:09]Swyx: Yeah, there'll be more of that, I'm sure, shenanigans, as they call it. But yeah, I think probably the safest way is to have sandboxes in the cloud. And yeah, I've been calling this the sort of the agent cloud phenomenon. I think Fly, IO, Modal, and E2B are in that space already. And then I think Repl.it is exploring it. It'd be interesting for you guys to get in that game. I have trouble articulating what's different about an agent cloud versus a typical serverless sandbox thing that you can spin up. Basically, I think for people to, if agent cloud is a real category, we have to identify what kinds of feedback do we want to give the AI that's different to a human? That's the extent of my thoughts on what this would take. [00:33:52]Aman: I think the key thing that not enough people are probably doing is giving the AI access to a lot more tools. So the classic example I like to bring up is, if you look at the old kind of alpha code model, which went and got 50% on some programming contest, a competition, 50th percentile of pretty good programmers, right? This was a base model that basically got, I think, something around 28% on human eval. And they use this interesting inference strategy of having the model generate a bunch of test cases, and then running the test cases, seeing which one passed. They use some other, there's some other details there where they do clustering and whatever. But the key thing is kind of letting the model generate tests, run the tests on all the outputs that it's generated. And that brings a 28% code forces model to 50th percentile. Gbd4, you just add a very basic prompt, please complete this Python function, and it gets 85%, 87% on human eval. Now who knows how tainted that benchmark is? But assuming it's reasonable, like what score do you think gbd4, the same kind of inference strategy as alpha code would get on that benchmark? It would do really well. And then gbd4 is at this level where they can actually not just run the test and like binary yes or no, use that answer, but it would see the results of the test and be able to modify the code or the test base in those. And so I think just like, that's just one tool. The other tools you could have access to would be language servers. So this is a great thing with VS Code, where VS Code kind of invented the language server or the language server protocol. And so as a result, when working with a VS Code fork, we kind of have access to every single part of the language server protocol, which means we can go to definition, get all the symbols in your entire workspace, kind of everything you do in a modern IDE. And what we've been working on is kind of giving these models access to those tools. And that like dramatically improves performance, right? Because the way that humans usually will search for something is they'll kind of click around, go to definition, read some code, do all that. But you use the tools in the IDE to search for things more efficiently. And if you're just trying to have a model, just do a brute force kind of semantic search and get the answer from that. I think it's not going to work nearly as well as kind of an agent that's able to use those tools. [00:36:10]Swyx: Awesome. [00:36:11]Alessio: And you guys are growing the team right now? [00:36:14]Aman: Yes, we are. So we are currently five people based in SF and we're looking to hire engineers and designers. We think there's a lot of interesting work that we're doing that's left to be done. So some of it involves model training, kind of training some open source models for things like embeddings or areas where it perhaps is too expensive or not or too slow to use open AI. And then lots of interesting things with pushing these models to kind of the boundaries. So getting GPT-4 to work really well in this kind of agent loop in a way that's really in flow and intuitive for users to use. So yeah, I think lots of exciting work. [00:36:53]Swyx: Cool. And then maybe to sketch out a little bit more about the company and then we'll zoom out to just general LLM observations. You're also working on a prompt tooling thing called Priompt? Yeah. [00:37:04]Aman: So this is just an internal tool that we use. It's called Priompt. And we built this because we didn't really find a good way of solving for the problem of when you have a variable number of kind of inputs that you want to stuff into the prompt and you have like a fixed length prompt, right? You can only use 4096 tokens. How do you encode for rules and how to properly kind of order the inputs that go into it? And Priompt or priority prompting are intermediary solution for this, where you can kind of encode very custom rules into how you build up the prompt based on how, I guess, overflowing it is, right? So let's say I have a bunch of previous chat messages and then I also have the code from the current file. So maybe what you want to do is you want some rules where if everything can fit in, you put it all in. But then you start by like first removing like all the old chat messages. Then once it gets to a certain length, you don't want to remove any more chat messages and you want to start removing parts of the file. And then you want to remove parts of the file in this particular truncation strategy, which tends to work quite well. So this kind of thing where like as you kind of slide the window and how many tokens you're allotted, you can see like the prompt is like very, very differently constructed. So it's like optimal kind of at all sizings. And we found that quite helpful internally. [00:38:23]Swyx: And you chose the JSX approach. I'm not going to ask you too much about like design choice. I mean, it's popular with React. Fixies also put out AI JSX. Do you find that like helpful? Do you think that like some kind of DSL might emerge for prompting? [00:38:36]Aman: Yeah, I think it's still pretty early. And it's not clear what the best way to do. I think for very lightweight, easy prompting, like you should just use strings. When you're doing kind of prompt engineering, and really like rigorous prompt construction where you can have a bunch of different possible inputs in the prompt. We think JSX makes a lot of sense. It's because it's kind of like website development where you'll have different kind of screen sizes, different kinds of devices that can look at it. And in a similar way, you've different kinds of prompts, right? You've different prompt context lengths. And you basically want across all different context lengths to get a very, very good prompt for the model. And so yeah, that's why I think like JSX kind of makes sense. It's not clear if it is like the best way of doing it. I think the jury's still out on that. [00:39:27]Swyx: One way to deal with the context length model issue is to train your own model that has a very long context length, like magic.dev, which announced a 5 million context length window. I don't know how credible that is. I haven't tried it. But your thoughts? [00:39:42]Aman: Yeah, I think the issue with context length, long context length right now is that costs scale linearly, right? Costs technically scale quadratically in terms of attention. But the interesting thing is that for really, really large models in terms of flops or actual floating point operations that the models are doing, attention tends to be a pretty negligible part compared to the actual, I guess, feed forward part of the neural network. And so up to like 8K, it tends to look pretty linear. I guess when you're going to like higher and higher context lengths, it starts to get more and more tricky. And then there's some other optimizations or some other difficulties with memory bandwidth that we can get into. It just feels like the key issue is even if it is linear, it's still so expensive, right? Paying for 32,000 tokens at whatever the pricing is right now feels like exorbitantly high. My perspective is that there probably will be at some point in the future, or there might be at some point in the future, like a better approach for really, really long context. Something that looks more kind of recurrent. [00:40:47]Swyx: It feels more elegant. [00:40:48]Aman: I don't know if it'll happen because I think there are like interesting ways of hacking together or chaining together these language models, even with short prompts. But I'm not super bullish on kind of scaling up attention the way that we're doing right now in like 100, 200K context windows. [00:41:02]Swyx: Like Cloud is doing. Yeah. Are you monitoring like RWBKV, which is one of the recurrent approaches? [00:41:07]Aman: I've been meaning to read that paper. I have not been monitoring that. I looked into a few of the papers from state space, like the state space models. Those are pretty interesting. Can you give an intuition? [00:41:19]Swyx: Because you seem to be explaining it really well. Why are they different? Why is that interesting? Yeah. [00:41:25]Aman: I think the interesting thing with, at least with the original state space model, is that you get kind of two benefits. One for training, you get the paralyzability of a transformer and you can kind of run it, I believe in about N log N for some N length sequence. And then for inference, it's also like the way that it's formulated is also somewhat recurrent. So you can kind of store everything in this fixed state. And then because of that, you get, I believe, an O of one kind of cost towards inference. It could be slightly higher, but yeah, it's much less than the O of N cost per token for the transformer. And so that makes it really tractable to then do for very, very long sequences. There's some follow on work with Hungry Hungry Hippos and Hyena. And again, I think the key piece is that for like very, very long sequence lengths, it ends up being N log N rather than N squared. I did say that the cost of like, I guess even linear attention is pretty high, but that's because the 32K model is priced a decent bit higher than the original. It is surprising that Claude, or I'm actually not familiar with Claude's pricing. Is it higher for the 100K one than for the normal? [00:42:31]Swyx: No, I believe it's the same. [00:42:33]Aman: That is actually quite surprising. I'm not sure if they're doing attention under the hood because even with like a lot of tricks with 100K or even 200K, I would assume that cost will eventually start to build up. So they might be doing something fancy there. [00:42:46]Swyx: Well, my guess was alibi, which is a trick, which is replacing proper attention with kind of like a exponentially declining forgetting curve is what I'm thinking. Someone has to put 100K to the test. I haven't done it. [00:43:00]Aman: Yeah, they have this graph that looks promising for 200K, but I feel like anecdotally from everything that I've heard, it just seems like it forgets things like they don't actually pay attention to things. [00:43:11]Alessio: I just open-sourced a small podcast there yesterday, which is what we use. [00:43:14]Swyx: We use it to summarize this podcast. [00:43:16]Alessio: Yeah, I'm looking at my logs, prompt length of all my recent ones is 55,400 tokens, and it works. [00:43:25]Swyx: How much per call? [00:43:26]Alessio: Free, because it's not commercial. I'm like, hopefully nobody from Entropic is listening. But yeah, it works. But I think that's kind of like the sweet spot. And then the completion length is like 1,800, you know, so it's not like it stays within the 60K band. But anyway, yeah, curious to see. And I think another thing from your Twitter model parades that I really like is actually differentiating between the type of workload. I feel like people talk about these models as like anything you do is like the same thing, but you posted about GPT 3.5 being cheaper than LLAMA 2 for completion-heavy workloads. What does that mean? [00:44:07]Aman: Yeah, so there are different terms, I guess, based on like whatever community you're in. So I think in the research community, they probably call it pre-filling is handling prompt tokens. And then I believe maybe decoding is what they call generating completion tokens. We'll just use prompt tokens and completion tokens. But for prompt tokens, the work, it's entirely compute bound. And the reason why is the same reason why transformers are so good at being kind of being trained in parallel. And it's that you can parallelize the entire sequence or you can parallelize an input, not just along the batch dimension, but the sequence dimension. So that means let's look at the first layer of the transformer. Imagine like that entire layer could fit in memory. I just read that to memory. And then I basically apply the matrix multiplication of the entire sequence on this layer. If you're doing token generation, instead, you have to read the layer, then taking the first input, and then you have to read the next layer and then do that same input. You have to do it all the way to the end of the model. And then you generate the next token and that next token passes through all the layers again. So before what you were doing is you have all your input tokens in parallel, they're going through the first layer. So you read the first layer, then in parallel, they're going through the second layer. You read the second layer, so on and so forth to the end. But when you're doing it for one token at a time, you read the first layer, second layer, third layer, fourth, blah, blah, blah. Then you do it all over again for the next token. And so as a result, for your sequence length N, you end up using N times more memory bandwidth than compute. [00:45:44]Swyx: And time as well, like wall clock time. Yeah. [00:45:47]Aman: I mean, so with wall clock time, it's weird because transformers are far more efficient than... [00:45:53]Swyx: I comment on that because in the RWKV interview that I did, same thing. They have a visual actually of this. So the thing you were trying to describe with words, they actually have a visual and animation But it's helpful because once you see it, you're like, oh, okay, that's why it's like a different graph. Yeah, exactly. Yeah. [00:46:10]Aman: So when you're dealing with the prompt, it's completely compute bound. And because GPUs can handle some crazy number of floating point operations per second, it's like almost instant. That's why time to first token feels super instant. And then when you're generating one token at a time, it now becomes completely memory bound where for each token, you're bound by how fast you can read all the weights into memory. So that's like around like 200x slower in general. [00:46:34]Swyx: Yeah. So your specific recommendations, which I pulled out from the post, people should read it. It's really good. I feel like the title undersells it a little bit. Yeah. You should not serve Llama 2 for completion heavy workloads. Llama is best for prompt dominated tasks like classification. And I feel like I can run with that. That makes a lot of sense. [00:46:51]Aman: And re-ranking is one thing we find useful for it internally. [00:46:54]Swyx: Do you use Llama 2 right now? [00:46:55]Aman: We don't have it in production, but we've experimented with it for a few things. [00:46:59]Swyx: You also had an interesting observation because I think we had talked a lot about quantization in the podcast just for running locally or more efficient running. You said quantization and imperfect utilization cancel each other out. Yes. That's a cool observation. Yeah. [00:47:12]Aman: So this is like a little bit hand wavy, but the core thing is, yeah, we expect that when you don't have like complete utilization, right, you're never going to like saturate all your GPUs. There's going to be some idle time. Like from things that we've experimented with in the past, it ends up being, you know, 50% is a reasonable amount as a more liberal estimate of how much you can get. So the interesting thing about quantization is that there's a bunch of these kind of new quantization libraries that have cropped up and they're all very good at reducing costs for low batch inference when you're memory bound. But the key thing is when you increase the batch size, they actually end up resulting in no real speed ups over FP16. The reason why is because they only quantize the model weights, right? So that operation of kind of reading the model weights when they're now, you know, 4x smaller instead of FP16, they're, you know, 4 bits or something. [00:48:04]Swyx: It's still the same number of weights. [00:48:06]Aman: The operation of reading weights is like it ends up being 3, 4x faster. But the issue is when you increase your batch size enough and for large batch inference, the key thing is it now moves back from being memory to being compute bound again. And when you're compute bound, quantization of model weights basically does nothing. And so it ends up being effectively the same cost. And then the other interesting thing is it's even worse for small models because for, or at least the small LLAMA models, because I believe the smaller ones relative to model size have a much bigger KV cache. I'm not sure if the smaller ones use multi or group query attention. They might not. [00:48:42]Swyx: They do not. Only the large ones use. Okay, exactly. [00:48:45]Aman: Yeah. So then because they use normal multi-head attention, the thing is when your batch size increases enough, then the memory bottleneck is not your small quantized model weights. No, it's actually the KV cache. And so quantizing the model weights effectively will do nothing then. So the key insight there is like all these new techniques are fantastic when you're just kind of playing with these models, running them low batch sizes. But when you really try to increase the batch size and serve it in production, they're probably going to be lower or more expensive than FP16 because there are these optimizations with things like text generation inference, which uses VLM or like page attention, which are much, much faster. And so the best that I think you could probably do right now with open source is like full 8-bit quantization, which means not just quantizing the weights, but also like the actual activations and the KV cache so that none of those things end up being bottlenecks. [00:49:36]Swyx: That's a great breakdown. The post goes into much more detail with a lot of math, actually, which I love. And you also spec out some rules of thumb, which I think people can use to figure out their limitations and pricing and all that good stuff. Yeah. [00:49:49]Aman: One big caveat I'd say is that the other massive benefit of LLAMA too is that you can fine tune it. [00:49:54]Swyx: Yeah. Right. Well, you'll be able to fine tune OpenAI soon enough. We'll see. So we'll just get your general takes on LLM topics, just kind of quick fire, and then we'll go to lightning round. So human eval, that is the predominant way to benchmark code models because OpenAI benchmarks code models that way. There's some issues with it. [00:50:13]Aman: Yeah. With open source models and even probably with some closed source models, it's unclear how much of it has actually leaked into the train set, right? So there's a recent model, New Hope, which it looked like they had some leakage, which is why it had really, really good performance. But I think there was an interesting approach taken by Palm too, where I think this is actually possible for someone to do right now. I've been meaning to do it at some point, but there's this paper called Babel code and they have a library which I think literally translates human eval into all other languages. And I think that would be a really good test because the other issues, a lot of the models that perform really well on human eval are pure Python, right? And that doesn't really give you a sense of if it's a good coding model overall. So yeah, I think at some point it would be really helpful if just someone did the work and ran the Babel code engine and translated human eval into all these other languages and then was able to run it. I think that would probably be a better benchmark, but still. I think if the original human eval problems leaked, I suspect it would also be helpful for solving the problems translated into other languages. But the issue is it's just so easy to run and anything else is probably going to be quite painful. [00:51:24]Swyx: Right? Well, it'd be better if there was a sandbox to run it. So agent cloud, hashtag. Hot take on training. Yeah. [00:51:32]Alessio: Another one from your endless Twitter quality. Training will look like researchers offloading large scale training jobs to specialized training companies. A state of the word that resembles chip design and fabrication. Yeah. [00:51:44]Swyx: How do you think about that? [00:51:45]Alessio: And obviously Mosaic was on the podcast just got acquired. [00:51:47]Swyx: So you tweeted that in May in 2022 and then one year later Mosaic gets acquired. Like I think that's a pretty fresh hint. Yeah. [00:51:54]Aman: I was probably wrong about it in a lot of ways too, because I assumed the future would kind of look like a lot of startups would have their own models. And this is me kind of in the CAD frame of mind where I thought, okay, if you look at GPT-3 at that point, it was just like GPT-3, maybe a little bit 3.5. It wasn't like that good a generalist model. And I thought prompting is not the way to do things. It's just completely fine tuning or training your own models. And it was also a similar time that we kind of saw a lot of the open source earlier efforts in training models, which proved like not that great. I think Bloom and OPT were two models that came around about that time. And if you looked at the OPT logs, they manually tuned their learning rates several times. I think they switched the optimizer from Adam to something really weird where they switched the optimizer in the middle. And don't quote me on this because I could be wrong, but I remember it was like some really, really sketchy stuff down in the middle. And I just thought, wow, if it's this hard, it seems like there's a company to be built around it. The key difference is that there are just massive foundation model companies. And I think most AI product companies are not going to be mostly training their models or mostly using like custom models. It's more so going to look like them kind of using these APIs out of the box. And then maybe using, you know, the fine tuning endpoints there. [00:53:12]Alessio: Oh, I mean, it's the same. [00:53:14]Swyx: So you changed your mind a little bit. [00:53:15]Aman: I did change my mind a little bit. I assumed like with the CAD thing, I thought, okay, you're gonna need a foundation model for CAD. You're going to need a foundation model. [00:53:22]Swyx: No, that's old school thinking. [00:53:23]Aman: Yeah. And now it's just like you have the one generalist model. The one God model. And the one God model transfers fantastically well with everything. Okay, quickly move along. [00:53:31]Swyx: You had another one, which I loved. The size of all code history on GitHub public repos is 92 terabytes. The size of Google's monorepo is 86 terabytes of much higher quality code. If Google were willing to deploy code models trained on your own data, they would have a noticeable advantage over everyone else. Yeah. [00:53:46]Aman: Again, this is one thing that I think is probably a little wrong. Because this is based on the big science paper. And the big science paper, like basically said they scraped all of GitHub and they got 92 terabytes. And I think if you look closely, which I did kind of after some people kind of pointed out some mistakes, I think GitHub is like a lot, a lot bigger than that. The big science paper said they get cloned. And so I was assuming, okay, get clone means you get the full working tree, right? But if you look a little deeper, I think GitHub is like a lot bigger than people think. My expectation is that GitHub probably has something like five to 10 trillion tokens of code, usable code. And so that's a lot more than what they ended up getting. But yeah, Google still has like a pretty meaningful fraction. [00:54:33]Swyx: And they just put out IDX, which is somewhat of a competitor. Yeah, yeah. [00:54:37]Aman: I think it's more like, it looks more like a replit kind of competitor where it's like an in-browser thing. But yeah, I think a lot of people can be viewed as competitors. [00:54:46]Swyx: But you're very competitive as we established, you know. And then final question, why is the company called AnySphere? And you have this whole manifesto on your landing page on why humans should focus on bigger problems. [00:54:55]Aman: It's an interesting story where Michael and I were in this program Converge, and two of our friends, Arvid and Swale, who we knew like reasonably well at MIT. And we knew them because they're like some of the best engineers at MIT. And so they were independently kind of working on their own company. It was called AnySphere. And we both independently from after playing with GPT-4 realized, oh, wow, like the IDE is the thing to build. After a few months of independently working on it, we realized, okay, like, why are we doing this separately? We should just kind of join forces. And that's kind of what we did. And so right now, the overall company is called AnySphere. But yeah, the product and the core thing is Cursor. It's lovely. [00:55:34]Swyx: I recommend people actually check out AnySphere.co and read the manifesto because I think it's a broader message to builders out there. Yeah. [00:55:42]Alessio: Yeah. Let's jump into lightning round. Okay. We got three questions for you. The first one is, what is something that already happened in AI that you thought would take much longer? [00:55:52]Aman: I think code. Specifically, I think just being generalist at code, where before you had these specialized models, right, where codex was supposed to be kind of specialized for code. And then there's a general language model, but it's kind of unification of capabilities towards like this one model that's not just really good at text, but it's also fantastic at code. I was not expecting like the generalist model, I guess, to come super, super soon and be this good at code. [00:56:19]Swyx: That's why you pivoted or you started your whole company. What do you think is the most interesting unsolved question in AI? [00:56:26]Aman: I really think it's this kind of long-term memory piece where I think it's possible to get to maybe AGI superhuman level systems that still kind of hack around memory using like something that kind of resembles transformers. But it feels like the more elegant thing is how do you get models that really like continuously learn? Some kind of recurrent based system would be able to do this where there's like a state. But right now, like models can only really learn in context super efficiently. Fine-tuning is incredibly inefficient. It requires tons of data points to actually learn new things. So yeah, I'm really interested to see how we solve this lifelong learning efficiency problem. [00:57:06]Swyx: Yeah. I'm interested in using knowledge graphs to do that because I think that's kind of like a forgotten piece of the puzzle. And if you could have models update their own knowledge graphs and query their own knowledge graphs, that might be it. I think Llama Index is basically working itself into what that is. Oh, interesting. [00:57:22]Aman: Yeah. And then there's the techniques where the models directly kind of learn to like inside the weights or inside the architecture, you learn how to be able to read from databases and retrieval based like the retro based techniques. Like those seemed interesting, but it's surprising like you haven't really seen anything from that in a while after that initial paper. [00:57:42]Alessio: And just to wrap the episode up, what's one message you want everyone to remember and think about as they keep building and exploring in AI? [00:57:49]Swyx: Yeah. [00:57:50]Aman: I mean, GPT-4 is now a few months old. At some point we're going to get much, much better models and I think it'll be pretty soon. And so what does the world look like then? And specifically for coding, like what does the world look like when you have another step that's just as large as it was from GPT-3 to GPT-4? I think it's just so incredibly different. I think it just completely changes how people write software. [00:58:14]Swyx: In what direction though? So I've said my piece on like 4.5 being more inference time. I don't actually know if that's true. That's just my theory. [00:58:22]Aman: I think the direction that we'll probably see is, I mean, the language models will just get better at doing intense reasoning, right? So they'll be able to tackle harder problems. They'll probably pick up in more nuances and how like software engineering is done. They'll probably have longer context windows. And so I expect, yeah, more agentic type things will end up being more prominent in the future. I don't know how far you can take the agent stuff with a four level model, but I think with like a 4.5 or a 5, I think agent models will work for almost any kind of coding task. At least almost any kind of reasonably well-scoped coding tasks. [00:59:00]Swyx: Agents are the future. Well, thanks so much for coming in. Thanks Aman. Of course. [00:59:04]Alessio: Thanks for having me. [00:59:04] Get full access to Latent Space at www.latent.space/subscribe
Tue, August 22, 2023
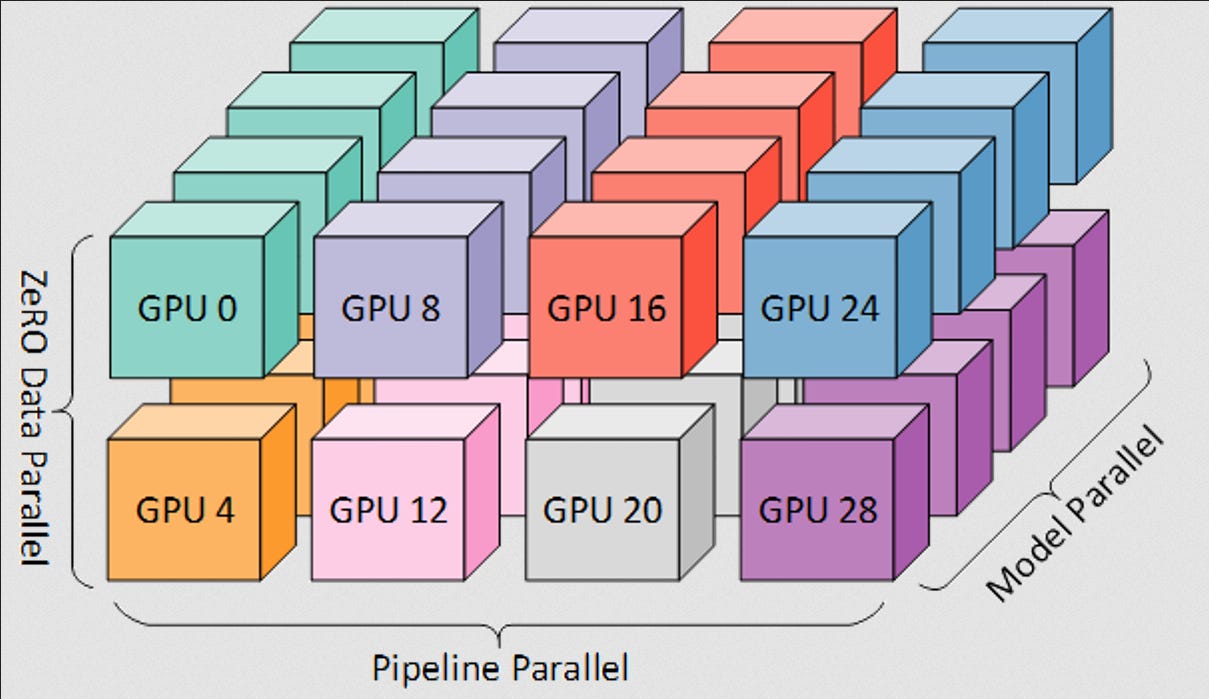
The Mathematics of Training LLMs — with Quentin Anthony of Eleuther AI
Invites are going out for AI Engineer Summit! In the meantime, we have just announced our first Actually Open AI event with Brev.dev and Langchain, Aug 26 in our SF HQ (we’ll record talks for those remote). See you soon (and join the Discord)!Special thanks to @nearcyan for helping us arrange this with the Eleuther team.This post was on the HN frontpage for 15 hours.As startups and even VCs hoard GPUs to attract talent, the one thing more valuable than GPUs is knowing how to use them (aka, make GPUs go brrrr).There is an incredible amount of tacit knowledge in the NLP community around training, and until Eleuther.ai came along you pretty much had to work at Google or Meta to gain that knowledge. This makes it hard for non-insiders to even do simple estimations around costing out projects - it is well known how to trade $ for GPU hours, but trading “$ for size of model” or “$ for quality of model” is less known and more valuable and full of opaque “it depends”. This is why rules of thumb for training are incredibly useful, because they cut through the noise and give you the simple 20% of knowledge that determines 80% of the outcome derived from hard earned experience.Today’s guest, Quentin Anthony from EleutherAI, is one of the top researchers in high-performance deep learning. He’s one of the co-authors of Transformers Math 101, which was one of the clearest articulations of training rules of thumb. We can think of no better way to dive into training math than to have Quentin run us through a masterclass on model weights, optimizer states, gradients, activations, and how they all impact memory requirements.The core equation you will need to know is the following:Where C is the compute requirements to train a model, P is the number of parameters, and D is the size of the training dataset in tokens. This is also equal to τ, the throughput of your machine measured in FLOPs (Actual FLOPs/GPU * # of GPUs), multiplied by T, the amount of time spent training the model.Taking Chinchilla scaling at face value, you can simplify this equation to be `C = 120(P^2)`.These laws are only true when 1000 GPUs for 1 hour costs the same as 1 GPU for 1000 hours, so it’s not always that easy to make these assumptions especially when it comes to communication overhead. There’s a lot more math to dive into here between training and inference, which you can listen to in the episode or read in the articles. The other interesting concept we covered is distributed training and strategies such as ZeRO and 3D parallelism. As these models have scaled, it’s become impossible to fit everything in a single GPU for training and inference. We leave these advanced concepts to the end, but there’s a lot of innovation happening around sharding of params, gradients, and optimizer states that you must know is happening in modern LLM training. If you have questions, you can join the Eleuther AI Discord or follow Quentin on Twitter. Show Notes* Transformers Math 101 Article* Eleuther.ai* GPT-NeoX 20B* BLOOM* Turing NLG* Mosaic* Oak Ridge & Frontier Supercomputer* Summit Supercomputer * Lawrence Livermore Lab* RWKV* Flash Attention * Stas BekmanTimestamps* [00:00:00] Quentin's background and work at Eleuther.ai* [00:03:14] Motivation behind writing the Transformers Math 101 article* [00:05:58] Key equation for calculating compute requirements (tau x T = 6 x P x D)* [00:10:00] Difference between theoretical and actual FLOPs* [00:12:42] Applying the equation to estimate compute for GPT-3 training* [00:14:08] Expecting 115+ teraflops/sec per A100 GPU as a baseline* [00:15:10] Tradeoffs between Nvidia and AMD GPUs for training* [00:18:50] Model precision (FP32, FP16, BF16 etc.) and impact on memory* [00:22:00] Benefits of model quantization even with unlimited memory* [00:23:44] KV cache memory overhead during inference* [00:26:08] How optimizer memory usage is calculated* [00:32:03] Components of total training memory (model, optimizer, gradients, activations)* [00:33:47] Activation recomputation to reduce memory overhead* [00:38:25] Sharded optimizers like ZeRO to distribute across GPUs* [00:40:23] Communication operations like scatter and gather in ZeRO* [00:41:33] Advanced 3D parallelism techniques (data, tensor, pipeline)* [00:43:55] Combining 3D parallelism and sharded optimizers* [00:45:43] Challenges with heterogeneous clusters for distribution* [00:47:58] Lightning RoundTranscriptionAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: Hey, today we have a very special guest, Quentin Anthony from Eleuther.ai. The context for this episode is that we've been looking to cover Transformers math for a long time. And then one day in April, there's this blog post that comes out that literally is called Transformers Math 101 from Eleuther. And this is one of the most authoritative posts that I've ever seen. And I think basically on this podcast, we're trying to give people an intuition around what are the rules of thumb that are important in thinking about AI and reasoning by AI. And I don't think there's anyone more credible than the people at Eleuther or the people training actual large language models, especially on limited resources. So welcome, Quentin. [00:00:59]Quentin: Thank you. A little bit about myself is that I'm a PhD student at Ohio State University, starting my fifth year now, almost done. I started with Eleuther during the GPT-NeoX20B model. So they were getting started training that, they were having some problems scaling it. As we'll talk about, I'm sure today a lot, is that communication costs and synchronization and how do you scale up a model to hundreds of GPUs and make sure that things progress quickly is really difficult. That was really similar to my PhD work. So I jumped in and helped them on the 20B, getting that running smoothly. And then ever since then, just as new systems challenges arise, and as they move to high performance computing systems and distributed systems, I just sort of kept finding myself falling into projects and helping out there. So I've been at Eleuther for a little bit now, head engineer there now, and then finishing up my PhD and then, well, who knows where I'll go next. [00:01:48]Alessio: Awesome. What was the inspiration behind writing the article? Was it taking some of those learnings? Obviously Eleuther is one of the most open research places out there. Is it just part of the DNA there or any fun stories there? [00:02:00]Quentin: For the motivation for writing, you very frequently see in like the DL training space, like these Twitter posts by like, for example, like Stas Bekman at Hugging Face, you'll see like a Twitter post that's like, oh, we just found this magic number and everything is like 20% faster. He’s super excited, but doesn't really understand what's going on. And the same thing for us, we very frequently find that a lot of people understand the theory or maybe the fundamentals of why like AI training or inference works, but no one knows like the nitty gritty details of like, how do you get inference to actually run correctly on your machine split across two GPUs or something like that. So we sort of had all of these notes that we had accumulated and we're sort of sharing among engineers within Eleuther and we thought, well, this would really help a lot of other people. It's not really maybe appropriate for like a paper, but for something like a blog post or technical report, this would actually maybe squeeze a lot of performance out of people's hardware they're already running on. So I guess there are a lot of projects in Eleuther that we're sort of trying to share notes with people in a way that typical institutions don't. They sort of live within that institution and then you go to a different institution and they do something very similar, but without the lessons of the previous. And it's because everyone's trying to do their own special sauce with their own stack. Whereas Eleuther, we don't really have that constraint and we can just share everything to everybody. [00:03:14]Swyx: Yeah, this is a level of openness that basically very few people actually embrace. One, it's an extra effort to write things down, of course, but two, it is secret sauce and so that not many people do it. And therefore, oftentimes the only way to learn this stuff is to actually work in one of the large model labs. And so you guys are doing a lot. The only other instance where I can think of where people actually open sourced their process was Facebook's OPT. What else is similar, like sort of trade knowledge, but not formal research knowledge? [00:03:45]Quentin: I would say Bloom. So the Hugging Face Bloom project in big science and all of that, that was very open. I'd say it's the same caliber, if not more detailed than OPT. Other than that, I think there was like a doc from Microsoft on like their Turing NLG. Their paper is pretty relaxed in that it did talk about some of those challenges. Other than like OPT and Bloom and us, I can't think of any. It's a new thing. [00:04:10]Swyx: It matters that you are going for the sort of good enough rules of thumb, because I think a lot of people try to go for precision and being overly precise actually is not helpful. Right. Yes. [00:04:20]Quentin: You'll see some like statements in the blog posts that are just like, we think this is about 1.2 in our experience. And, you know, we don't go any further into detail and it would take maybe an extra month for us to chase down every single little piece of memory. But instead, like getting good enough is still helpful to people. [00:04:36]Alessio: Let's jump into it. The first part of the article, and we'll put this in the show notes so people will be following along with the post. So we don't need to read every single equation and every footnote for it. [00:04:46]Swyx: Okay. [00:04:46]Alessio: But the core equation here is that not the cost of compute, but the compute required to turn a transformer model is roughly equal to tau times T, where like T is the, where tau is the hardware setup throughput that you have. So number of GPUs times the actual flops per GPU. And then T is the time spent. I think people can visualize that pretty easily. It's basically like how many GPUs do you have and how much do you let them run for? And the things that come to it that people have read before in the Chinchilla paper in a way, and the OpenAI scaling law is that you can then equal this to 6PD, where P is the number of parameters in the model and D is the size of the, of the dataset in tokens. So talk a little bit about how people should think about the two. I think a lot of times the focus is on tokens parameter ratio in the training dataset and people don't think as much about the actual flops per GPU, which you're going to mention later in the blog post too, in terms of how much you can get out. So how should people think about this when they're building a model and where should they go to this equation as they're starting to think about training their own transformer-based [00:05:58]Swyx: model? [00:05:58]Quentin: You touched a little bit on the fact that people usually start with the dataset. So you have some dataset that you want to train a model on. And then from there, from the 6PD, you should see, okay, I should have about six tokens per parameter. So that determines my model size thereabouts for Chinchilla Optimal. So since then we've seen that need more something like 20 or more than that to get a good quality model. But the next question that should be on your mind in terms of a systems perspective is how long is it going to take for this model to train and what kind of budget should I expect? So let's say I want some cloud instance for some amount of time and each of them will have some price attached to it. So that's where the throughput comes in. So now that you have this model, this number of parameters, you should map that to a transformer architecture and you should benchmark what throughput you get on your software stack for that type of model. So now you have your flops per second on a single GPU. And then given whatever parallelism scheme, which I'm sure we'll get into, like data parallelism or tensor parallelism or whatever else, how is that flops number going to scale to whatever number of GPUs? And then from there, you're going to get a time. And if you have a time, you have a cost. Those are like the business answers that you'll be able to get using this formula. That's why we sort of split it into the T and the throughput terms so that you can solve for one of them, which is usually get throughput, need time, and from time you get cost. In a nutshell, that's the answer. [00:07:19]Alessio: One thing that I noticed, you mentioned some of these laws are only true when a thousand GPUs for one hour cost the same as one GPU for a thousand hours, given that we have a shortage of the biggest GPUs out there. Any thoughts there on how people should prioritize this? [00:07:36]Quentin: Yeah, so I would say you should find what the minimum number of GPUs is to just fit your model first. The memory bottleneck is your biggest problem if you have a sizable model. If it's a small model, nobody cares. But most models that people care about will need to be split across multiple GPUs. So find the minimum number of GPUs to just fit your one instance of your model and then calculate how long that's going to take. If it's a reasonable amount of time, then you're done. If it takes too long, then you need to start worrying about having multiple instances of that model. I always feel like you should go with the minimum number of GPUs because the more number of GPUs that you have, the more likely it is for things to break. So I would say just find out what time is reasonable for you and then fit the number of GPUs to that and no more. Because people get greedy and they say, if I have twice the GPUs, I can get this done in half the time. And then you end up taking three times the time because everything is breaking every day. And that's when I am up at midnight trying to fix your model that's broken. [00:08:34]Swyx: We had a previous guest which has invested a lot in their framework for training these things. Would there not be an equivalent open source framework you guys would have made that would help with scaling up GPUs linearly like that? Or is this an oversimplification? [00:08:50]Quentin: Okay, yeah. So maybe I should step back. Both Mosaic and us have our own sort of software stack recipe that scales well, theoretically. But I'll get to that in a minute. Mosaic is all based off optimizer sharding. So it's based off ZeRO. So you basically perfectly split your model optimizer and your parameters and your gradients across all of the different GPUs. So your aggregate memory is number of parameters divided by number of GPUs. Same thing for optimizer and so on. Whereas we at Eleuther use a Megatron deep speed based library. And for that, it's a bit more complex. So the efficiency can be a little higher, but it's more prone to failure at the same [00:09:30]Swyx: time. [00:09:30]Quentin: So you kind of have to tune it. In both cases, getting back to like the practical case, you should be able to get linear speed up by adding more GPUs. The problem is that there are hardware failures. You tend to have problems with like maybe loss will overflow if you have too many GPUs or maybe one GPU will hang. You might have software issues. You might have synchronization issues. And that's why I'm saying practically that you should take the minimum number of GPUs that you have because those are the easier cases to debug. That make sense? [00:10:00]Swyx: Yeah. [00:10:00]Quentin: Any more detail on any specific point? [00:10:02]Swyx: Not particularly, just because we haven't actually had to debug those things. But I imagine basically there's a lot of return towards encoding these knowledge into software and not repeating it again. So it makes a ton of sense. I think Alessio had more questions before we move too far into high level, more questions on just the equation itself. I think we want to spend time on essentially, this is the central equation of figuring out compute requirements. Yeah. [00:10:25]Alessio: Another thing in it is that the computer is like the forward pass and like the backwards pass and forward is 2PD, backward is 4PD. Why it's to the ratio between the two? Can you explain that? Why is it two and four? [00:10:39]Quentin: Yeah. [00:10:40]Alessio: Why is it twice the amount? [00:10:42]Quentin: Oh, okay. Intuitively for forward pass, you're just moving, you're propagating forward the inputs through the layer. And then in the backward pass, you're doing something a little more complex than that. You're doing back propagation. And I don't think I can explain it intuitively enough to go into more detail on the exact [00:10:58]Swyx: numbers. Yeah. [00:10:58]Quentin: That's okay. [00:10:59]Swyx: I feel like you want to get out a whiteboard and start drawing like, you know. [00:11:02]Quentin: That's what I would normally do. [00:11:03]Swyx: Tangents and gradients. It's actually surprisingly low to do the back propagation. Honestly, that's one of the fundamental things I love about the math of deep learning so far that as I've explored it, which is, it's surprisingly efficient as compared to other, I guess, numerical methods you might be exposed to and, you know, college calculus. Yeah. [00:11:22]Alessio: And I think the other thing is that things sound simple, you know, when people go on Twitter and say, Oh, 20 is like the optimal ratio. And it's like, then it's like, well, why is that the number? And the answer is usually much, much harder, like what we're seeing right now. So I think it's a, it's a good reminder that the numbers are simple, like all the best and most popular, like math equations are like, so elegant. Obviously the proof behind that is, it's not that easy. That's always a good reminder. [00:11:52]Swyx: I want to put this equation to the test a little bit. We can do this from either GPT-3's perspective or GPT-NeoX, whatever you're more comfortable with. You have this distinction of actual flops versus theoretical flops. And a lot of times when people report the flops it took to train a model, like we just saw one in Lama 2 where the estimate is something that the amount of flops and that's, that's what we go with. So GPT-3 took a 3.14 times 10 to the power 23 flops. That is the theoretical flops. I want to get to a point where I can sort of work out if a number passes the smell test. And I wonder how to do that because I should be able to plug in this equation, right? I know that GPT-3 was trained on 300 billion tokens. I know the parameter size of 175. Is it, is it just like a 6 times 175 times 300? Like I haven't done the math, but what are the nuances here that you might want to call out? [00:12:42]Quentin: Theoretical flops is usually given from, you have a given set of hardware and this is what you expect your hardware to get. The problem is that in practice, full utilization, that's the key word, right? Because in practice, there are a lot of cases where like you're spending time waiting on data movement from like the GPU to CPU. Or for example, you might be waiting to synchronize across the different GPUs. So there's a lot of idle time basically that you're going to be spending during training. [00:13:05]Swyx: Smell tests. [00:13:06]Quentin: I don't know if I have a smell test myself, to be honest, like maybe I'll look at like what sort of flops, what you would expect on like an A100. There's sort of just an expected flops for a given GPU that everyone sort of knows what you should expect. So like for an A100, that number is somewhere between 100 and 180. T flops is what you would expect to see on an A100. For a V100, like an older GPU, it's something more like 40 to 30. So people sort of know, given the kernels that we're running for a deep learning, what sort of flops you expect. And then you sort of compare that to the theory, to the theoretical flops that people are reporting and see if that matches your expectations. [00:13:47]Swyx: Yeah. [00:13:47]Alessio: And in the article you mentioned for the A100, like if you're seeing below 115 teraflops a second, there's something wrong with your model or hardware. How did you get to 115? Is it just, you know, production observability and like you've seen over months and months and months that like that's the baseline or how do you come up with the numbers like that? Yeah. [00:14:08]Quentin: For a number like that, we basically, we compared a lot of different frameworks. So like I mentioned before, Mosaic has their own framework and we have our own framework. They all have their own flop counters too, right? And we saw across a bunch of different hardware configurations that if you tune things correctly, you should be getting above 115 in pretty much all cases. So like there are some cases where things are tuned poorly or your system is a little weird, but we've never been able to get a new system and not been able to get above [00:14:35]Swyx: 115. [00:14:35]Quentin: If something is below 115, you have something really wrong in your software. But that's really all it is, is just comparing across software stacks and hardware systems. [00:14:44]Alessio: What about different GPUs? We had George Hotz on the podcast and he talked about AMD cards and how in theory their flops should be much better than some Nvidia cards, but the reality is like the CUDA runtime makes up for it. How should people think about improving that? You know, like do you see, okay, the A100 is like 115 teraflops. I'd rather just stick with this than try and figure out all the kinks of like a better AMD card or any thoughts there? [00:15:10]Swyx: Right. [00:15:10]Quentin: Well, that's sort of touching on developer time, right? And which ends up being more expensive because at the end of the day, the AMD and Rockham software stack has a long way to go. I would say most things run there, not particularly efficiently, but you're going to have weird bugs that no one has encountered before. One of the big pluses of going with the Nvidia and PyTorch stack is that there are thousands of GitHub issues with everyone facing the same problem as you and resolving them quickly and in an open source way is probably the biggest benefit of going with the Nvidia software stack right now. AMD has about the same hardware, software, not so much. And they haven't quite got the momentum in the open source realm, for example, to get close. Like something, for example, like Flash Attention, it's spread to more Nvidia GPU types than it has like to AMD at all. And waiting on those latest and greatest features to reach AMD is something that's prohibitive to a lot of people, but it's getting there. I'm running a lot of experiments on AMD right now because it's sort of reached the government lab supercomputers now. And so a lot of experiments are going there and it will catch up, I'd say within a few [00:16:14]Swyx: years. [00:16:14]Quentin: Awesome. [00:16:15]Swyx: Maybe just talk about what's available from the government labs and I heard the original, the origin of Eluther started with a grant for TPUs. Is that right? [00:16:24]Quentin: Yes, that was a little before me, but there was a lot of just like getting a grabbing a Google Cloud or TPU pod or something like that is a lot of the original TPU work on Mesh TensorFlow, which is like now like an ancient distributed deep learning library. [00:16:36]Quentin: Eluther got a grant, an insight grant with Oak Ridge last year, and we got quite a bit of Summit Compute. So Summit is a V100 based supercomputer. It's got some weirdness to it. So there's six V100 GPUs per node. And we did a lot of experiments there. It's a challenging system to scale to because your interconnect across nodes is kind of slow in comparison to within a node, which I think we'll get to later. But now Oak Ridge has moved to AMD. So the next grant that we're trying to work towards is on Frontier, which has four AMD GPUs per node and again has a slower interconnect across nodes. So we get all of those new challenges again to try and overlap things. But that's just like you have Oak Ridge, you have Lawrence Livermore. There's a lot of government supercomputers that you can apply for compute towards like open researchers too. It's sort of a new thing. I think we're one of the first like us and like Lion, for example, is another organization that's getting compute from government providers and such. They're all moving to AMD as well. And we look forward to exploring that with them. [00:17:42]Swyx: Yeah. [00:17:43]Alessio: The computing is definitely, it used to be easy to find the GPU. Now, not as much. So you got to find them anywhere. [00:17:49]Swyx: Yes. [00:17:49]Alessio: Let's talk about memory requirements a little bit. So you touched on this a little bit before and just before this, we had a trade out on the pockets from FlashAttention and memory speed was one of our main focuses, but this time we're being bound by actually memory size, like the VRAM itself, when it comes to model weights and parameters and optimizer states and all that fun stuff. Let's go through this and Sean, we can, we can take turns. There's a lot to cover here, but maybe we can start from model weights. So one topic we covered a lot in the past is precision and quantization. That's one of the obviously main driver of memory. You mentioned most of, in the article, most transformers are mixed precision, like FP16 plus FP32 or BF16 FP32, and they can be cast down. And you mentioned up to like INT8 without a lot of performance hit. So let's start there and maybe run people through some of the maths and like the byte per parameter ratio and different precision. [00:18:50]Swyx: Sure. [00:18:51]Quentin: So when I started deep learning, it was all FP32. You have 32 bits, four bytes per parameter. Things were pretty simple. You didn't have to do any loss scaling at all. But the problem was that you didn't get a whole lot of flops once NVIDIA moved to V100s and introduced Tensor cores. So Tensor cores do all of their computation at FP16 precision. So you're kind of throwing all of those away if you're doing things in FP32. So once the hardware moved to V100, the software moved to like mixed precision and APEX and AMP and such. And one counterintuitive part of mixed precision is that you actually require more memory when you're trained because you need an FP16 copy of the weights and an FP32 copy of the weights. The FP16 copy is where you're doing like your actual computation on the Tensor cores. So you get maybe it's not uncommon to get double the throughput that you would see before in FP32. And then you at each step update that FP32 copy with the FP16 update. So both need to be stored in memory. The problem with that is that FP16 is very precise but doesn't have a whole lot of range, [00:19:55]Swyx: dynamic range. [00:19:55]Quentin: So you have a really big mantissa if you're thinking in terms of like floating point representations, not a whole lot of exponent. So BF16 puts more of the bits from the mantissa back to the exponent. So you have a much higher range and a lower precision. And that gets rid of all of this instability problem and loss scaling and such that anyone familiar with debugging knows how unstable it can be, especially for large scale training. And BF16 does away with a lot of that, but it's only supported on A100s. So you see the back and forth between hardware and software. So every time NVIDIA introduces some new Tensor cores or BF16 support or something like that, the software adapts to support it and then training adapts. And then now you mentioned like Ind8 and such. Now we're seeing that you have some model that's been trained in FP16, FP32, whatever else. And then now you want to, with minimal loss and accuracy, quantize that model into a smaller representation like Ind8 and now like Ind4 and things like that and see what you can get away with. And then since deep learning is such like a stochastic problem that a lot of those last bits of precision don't really matter is what we're finding. And I expect that to continue. [00:21:06]Alessio: And so just to put some numbers to it, when you have a FP32, you need four bytes per parameter at inference time to load it in memory. If you have a eight bits model quantized down, you need one byte per parameter. So for example, in an H100, which is 80 gigabyte of memory, you could fit a 70 billion parameters in eight, you cannot fit a FP32 because you will need like 280 gigabytes of memory. So how much does that play into it? Like you mentioned it was all FP32 when you first started. Is it just like a development complexity thing, like going down to FP16 and then Ind8? Or if they could get a GPU with like a terabyte of VRAM, will people just load this memory as like FP32 weights or would they still want to quantize them to make them more efficient? Right. [00:22:00]Quentin: I would say even if you had infinite VRAM, you would still want a quantized model, just a bigger model that's quantized is what I would say. And that's because like I was mentioning there at the end, how like deep learning is very stochastic and a lot, you could have all the precision in the world, but ultimately it's meaningless when you still depend so much like on what the input is. And you depend so much on little variations and maybe a few more samples of training data would matter more. A lot of that precision in a nutshell doesn't really matter in deep learning. All that matters is the big picture. What is that neuron actually saying? And not the tiny details of what it might be thinking. Oh, I also wanted to mention that even if you have an A100, the actual model size is quite a bit smaller that you could load than what you mentioned. That's because of the KV cache. So the KV cache intuitively during inference, it only matters during inference and think intuitively if you're writing a paragraph, you want to remember every single previous word that you've written before you write the next word. So like what is autoregressive language modeling? It's filling in the next word, the next token. So if I say like the dog went to the, and I need to write the next word, I would say park or something. Before I write the next word, my memory is wiped and I have to read the whole thing again. That is life without a KV cache. And a KV cache says, remember everything that I've generated before, as well as all the context before what I've generated. But the memory overhead for a KV cache commonly is either comparable or larger than the model in some cases, if you have a really long context. And I think the exact equation is something like, oh, it's like two times the number of layers, times the number of heads, times the dimension of each head. And then there's two of those. You have one for K, one for V. But that was just a quick aside. Yeah. [00:23:44]Alessio: I know this is Transformers math, but do you think one of the interesting things about RNNs too, it's like moving away from this, like KV cache, the scales with the sequence length and having like a fixed sequence pass. I know those are some of the things that people are working on. [00:24:00]Swyx: Yeah. [00:24:00]Quentin: So there's a paper that I was involved with called RWKV that I would recommend people read. It is answering this exact question. So how do you get Transformers quality without this quadratic attention overhead that Transformers requires? So it is interesting. I don't know if I can really dive too deep into the technical details there. I'd recommend people read the paper. But yeah. [00:24:23]Swyx: Yeah. [00:24:23]Alessio: It's interesting to see if attention is all you need, or maybe attention is all we need, but we need better ways to make it infer in a good way. [00:24:33]Swyx: We've actually done an unreleased episode with one of the RWKV core members and they call it soft attention or light attention. I forget what they call it, but yeah, just ways to approximate it such that it's linear and not quadratic. That's great. Yeah. [00:24:47]Quentin: I didn't know that you were involved. [00:24:48]Swyx: That's great. How did you get involved? Is it just because like everyone just hangs out in Discord and talks about the future of Transformers? Oh yeah. [00:24:55]Quentin: I mean, the RWKV people specifically are in Eleuther all the time. Like they're very close collaboration with us. And my contribution was we have all of these experiments done by all of these people on RNNs and how they relate to Transformers and how do we turn that into a paper and disseminate that digestibly so that people don't have to read through like a Discord log from a year ago to understand what's going on. [00:25:16]Swyx: Oh my God. [00:25:16]Quentin: Just read this paper. So that took some work, but I wasn't a core contributor. So that's why I don't want to go into like the technical details. But yeah, that's how I did. [00:25:24]Swyx: We'll try to get that RWKV episode out. It seems like there's increasing mentions of it and they are doing pretty important work as far as scaling these models are concerned. Okay. So we discussed inference type quantization and memory requirements. And then you also had a section on training with a lot of stuff I think mentioned. I think we probably want to spend the most of our time on optimizer states and the Atom optimizer. Yeah. What are your takes on it and what should people keep in mind when they deal with these optimizers? Okay. [00:25:57]Quentin: I would say the Atom optimizer is good at what it does. It's sort of a broad question. So let me think. You have the copy of the weights and then you have your momentum and your variance that [00:26:08]Swyx: you store. [00:26:08]Quentin: And like, okay, maybe an intuitive explanation for momentum is that like, let's say you have a canyon and you're trying to get to the bottom. And if you're just doing basic SGD, then every step is going to be an equal size. Whereas if you're using something like Atom with the momentum term, then your steps should be progressively larger because you can see, oh, the general trend is we're heading downwards very quickly. But stepping back from that, since you have all of these extra terms in Atom, you require a lot more memory to store it. Like three times as much memory as SGD. And if you have all of this memory being spent on your optimizer states, then how do you distribute it across GPUs? Because you'll find that what ends up being your bottleneck more than just raw compute, raw flops on a given GPU is your parallelism. And that falls back onto how much model you can fit on a single GPU before you need to split it up across a bunch of GPUs. And then you end up spending time, more time with them talking to each other than actually making progress. So that's why all of this time in the blog post is spent on how do you distribute your model? What are all those different distributed strategies look like? Which ones are more efficient? And given that a lot of your memory is being spent optimizers, how do you distribute that optimizer specifically? Because a lot of people, when they talk about parallelism, they talk about model parallelism, the parameters themselves. In actuality, when you're training, a good portion of your memory is actually spent on optimizer states. So what specific part of that would you like to go into? Would you like to go into like zero or sharded optimizers? [00:27:36]Swyx: I think the sharded optimizer stuff is really interesting, but I think we're kind of leaving that towards the end, right? Because that's the maybe more advanced distributed sections. Here, I think we're just going for rough intuition for people who've maybe are familiar with the ideas of these optimizers, but haven't actually had to implement them yet. They read your code, but they don't really understand the intuition behind the code. I see. [00:28:00]Alessio: And Quentin, when you say in the blog post, it says, Adam is magic. How much of it is like actual magic, even to like people like you that are pretty close to the metal, so to speak? Are some of these things just come as gospel? It's like, I know this works, like I'm not touching it. I'm just leveraging it. How much of it are you actually thinking about improving on in your day-to-day work? I see. [00:28:22]Quentin: So I'm a systems guy. I'm an engineer. And a lot of these things come to me as magic. Adam comes to me as magic. I see it from the gods. I say, this is how a deep learning model is trained. And this is how the next step is calculated. And then I say, okay, how do I make that fast? I would say I do look at ways to improve upon it using things like second order optimizers. So there's a lot of research on there because they're hard to distribute. But the core contribution for me always comes down to someone else has done like some deep learning optimization and I need to make it run fast. So I can't really speak to the motivation of why Adam came about other than like simple, intuitive things like I mentioned with like the momentum. But what matters to me is that Adam takes more memory than SGD, specifically three times. And all of that memory needs to go somewhere and it needs to be split efficiently. [00:29:14]Swyx: Yeah. [00:29:14]Alessio: So when you add them all up, you got 12 bytes per parameter with vanilla Adam. [00:29:20]Swyx: Yeah. [00:29:20]Alessio: And then you still get the model parameters and memory too. So as you mentioned, you need to keep a copy of both for like a FB32, FB16 mixed, a copy of both quantization levels. So there's precision levels. So it's six bytes per parameter. Right. [00:29:36]Quentin: Taking a step back again, is that like, okay, most people think of your model getting big. So you need to split with model parallelism purely, something like tensor parallelism. But we can see that the model only takes like two bytes per parameter if we're doing FB16. Whereas the optimizer itself requires four bytes per parameter for the model states, four bytes for momentum, four bytes for variance. So what matters more is how do you split your optimizer efficiently and how do you store it efficiently? And something like bits and bytes, where the optimizer, you got like eight bit Adam, where those optimizer states is only one byte per parameter instead of four or something like that. That is going to give you a much better return on your model training and on your memory overhead required than if you were to, for example, quantize your pure like FB16 model weights down to int8 or something. So for training specifically, your optimizer memory matters a lot. The most in most cases. [00:30:31]Swyx: Well, yeah. [00:30:31]Alessio: And before we dive into zero, just to wrap up the items that you're going to shard later. So you have the parameters, you have the optimizer states, and then you have the gradients. Just maybe touch a little bit on that. And then we can talk about how to efficiently load them in GPUs. [00:30:48]Quentin: So the parameters are the FP32 copies of the parameters. We include them in the optimizer discussion. Some people don't, but just for clarity, it's 12 bytes per param for the optimizer states and four of them are for that FP32 copy of the weights. Four of them are for the momentum. I already went into why it's important to store momentum, but that's also per parameter. You need to store where that parameter is going and where it's been going in the past. You also need to know, okay, we know where it's going, but there's going to be bumps on this canyon that we're going down. So we need to store its variance. How often are those bumps? Should we be focusing more on the momentum? Or is this parameter just kind of jumping around everywhere? Those are all important answers that we need the optimizer to store, and it's per parameter. So that's where all three of those terms come from. And we also include some competing bits and bytes, for example, an SGD to show that depending on your optimizer, you may store all or none of these and in different representations. [00:31:50]Alessio: I'm looking at the total training memory. You essentially have model memory, optimizer memory, gradient memory, and activation memory. I think that's one of the last discussed things. So maybe just give people a little bit of a view. [00:32:03]Swyx: Yeah, this is completely new to me. [00:32:05]Alessio: Active, you know, recomputation, checkpointing, and all of that. [00:32:08]Swyx: Right. [00:32:09]Quentin: So, okay. So to summarize before activation checkpointing, which will be complicated, you have your model params, like I mentioned before, they used to be FP32. Now they're probably BF16, maybe FP16 if it's an older GPU. Then you have your optimizer. That's where a lot of the memory is going. And it's your high precision, usually FP32, copy of the weights. So that's four bytes per param. And then you have, optionally, a couple more terms like we just discussed, like momentum or variance or whatever else, depending on what your optimizer is. Then you have your gradients. So your gradients is what is the gradient update that we get after running the forward pass on the model. And that's going to be whatever your low precision copy of the weights is. So like two bytes per param, if you're using FP16 or BF16. And all of those are sort of set in stone. And that overhead is not going to go away for the duration of training. Your gradients might get cleared after you back propagate them, but your optimizer states and your model states aren't going away. That memory overhead will be there. Activation recomputation and activation memory is dynamic. So some people will come and have this problem where the model loads fine for training. But then when you actually run your first iteration, or you run some future iteration or something like that, you run out of memory, seemingly at random. And it's because of these activations that you're computing on the fly. Good summary, or do you want to get into activation recomputation now, or do you want me to touch on anything else? [00:33:35]Alessio: Yeah, I was going to say, when is the recomputation happening? How does it decide between recomputing versus storing? And talk a bit more about that, maybe. [00:33:47]Quentin: Yeah, okay. So there's a lot of different ways to do this, but I would say there are a few main ones. First is a very simple scheme. You recompute everything. Every single activation that you calculate is just going to be either used or thrown away until the end. So in that case, you care very much about memory. You care very little about compute. Maybe this would be a case where you have to distribute across a lot of different GPUs, for example. And your communication speed is really low. Then that might be a good case for you to just recompute everything. It happens rarely, but it happens. Next up would be something like selective recomputation. So in selective recomputation, which Megatron has a good paper on, and I believe the figure that we have in our blog post is from, in that case, you sort of do a weighted decision for each activation. So for really big activation tensors, you decide, is this going to be more expensive to save in terms of memory or to recompute in terms of compute? So that's sort of the smart scheme that Megatron implements. And there's a lot of different heuristics they use. It's probably not worth mentioning off this super long equation on a pod, but you should go and read that paper if you're interested on selective recomputation. And then a really stupid scheme that most people go with, including NeoX, would be something like, instead of doing all of these heuristics, you just say, if my tensor is bigger than X, I throw it away. And you set X to some static number, and that's it. And that is good enough for a lot of cases. [00:35:18]Swyx: Why is it good enough? [00:35:20]Quentin: You don't want to store more than, you know, X-sized tensor. And some fall above that, some fall below it. And you're not trying to squeeze. You care more about getting something close enough to what the actual heuristic should be without actually computing the heuristic because you don't want to spend the time writing that heuristic code. [00:35:37]Swyx: Cool. I think that does take us on a grand tour of the memory math. Is there any sort of high-level takeaway before we go into the distributed stuff? Zero and all that. Perhaps more detail than most people have ever encountered. And so I'll repeat the equation that Alessio mentioned again, which is total training memory now has all these components that you've mapped out for the first time as far as we're concerned. Model memory, optimizer memory, activation memory, gradient memory. We covered quite a few algorithms as to the choices you can make there. Anything else that you want to mention about just memory math? I don't think so. [00:36:11]Quentin: I think that about covers it. I will say that it's a very different scheme for training and inference. It's common for people to say, oh, BF16 is the best. Done. Whereas a more correct take is that during training, precision matters a bit more. So BF16 will be around longer for training than it will for inference, in which case your model is sort of already baked. And it definitely doesn't need some of those last bits of precision so you can get away much easier with going to int8 for inference rather than training. So everything that you learn for training has to be relearned for inference and vice versa. [00:36:44]Swyx: There's a third category. You're talking about training versus inference. This third category is emerging with regards to fine-tuning and perhaps parameter-efficient methods of fine-tuning. The naive way to implement fine-tuning is just to do more training. But I don't know if you've developed any intuitions over fine-tuning that's worth inserting here. Any intuitions? If you were to write fine-tuning math, what would go in there? That might be an interesting diff to training math. [00:37:10]Quentin: I think there's a lot of questions that are unanswered for fine-tuning. For example, we know scaling laws for training. And some people have done scaling laws for fine-tuning. But how does a model that's already been trained on one domain transfer to another in terms of fine-tuning size? How many tokens per parameter should you have for your fine-tuning dataset? Maybe I'm ignorant, but I feel like a lot of those sort of practical questions on how a model can transfer and how a model can learn or grok some new ability that wasn't in its original training dataset is something that I would definitely put inside a fine-tuning blog post. [00:37:45]Swyx: Something related to perplexity and, I guess, diversity of the tokens that you get. [00:37:49]Quentin: Yeah, sort of dataset transfer is something that I would be curious in. Learning rate transfer is another one. So your model has some decayed learning rate over the course of training. How does that change for fine-tuning? Things like that. [00:38:00]Swyx: All right, cool. Thanks for indulging that stuff. Sure. Yeah. [00:38:03]Alessio: I think after all of this, you can quickly do the math and see that training needs to be distributed to actually work because we just don't have hardware that can easily run this. So let's talk a bit about that. So zero is one of the first things that you mentioned here, which is focused on sharded optimizers. Maybe run people through that and how to think about it. [00:38:25]Swyx: Sure. [00:38:25]Quentin: So zero is centered around two communication operations. And the first is scatter. And people should be looking at the zero figure that I think we have. [00:38:35]Swyx: Yeah. [00:38:36]Quentin: So there's a figure in the paper with parameters, gradients, and optimizer states that people should be looking at when I'm talking about this. Every GPU is going to get its own equal portion of the slice. And if we're doing... There are different stages of zero, but let's just start off with assuming that it's an equal slice of the optimizer states, gradients, and parameters. That would be zero three, stage three in that case. And we do that with a scatter. And the scatter takes, say, one over end GPUs, plus this offset of that slice goes to that GPU. Now all of the GPUs have an equal slice that's in its rank order. And then during each training step, that GPU is going to wait for all of the other slices to communicate so that we now have a whole pie on that GPU, that single GPU. Once we have that whole pie, we do the forward pass on it. And then we distribute that forward pass to all of the others using a gather. So it's a scatter, reduced scatter specifically, and then a gather back to all the others. And you do that each step. So the point of it is that you're sharding these states across GPUs. And with the different stages, you'll see in that figure that the optimizer state is taking the most proportion, which is because of what I mentioned before. We're including the FP32 copy and we're doing atom. So we need those four bytes per param for momentum and for variance. And then zero stage one, which is the most common one, is just optimizer. Zero stage two is optimizer plus gradients. And zero stage three is optimizer gradients and model parameters. But it all comes back to this splitting up and then gathering together back and forth over and over. So you get a lot of communication overhead from zero. But the plus part of that is that you can overlap a lot of that movement with computation. [00:40:23]Alessio: How do you get the optimal number of GPUs to do this on? Is there a way to shard too much as well and put too much overhead? [00:40:31]Quentin: It depends more on what your interconnect is. Taking a step back, there is synchronization that's required, a lot of it, across all of these GPUs. And those tend to be cumulative. So if you go to too many GPUs on an interconnect that's too slow, then you're going to end up spending more time synchronizing. And that magic number where you spend more time synchronizing is going to be different depending on what your fabric is and what your GPU memory is specifically. Just how small of a slice is each GPU getting? I can't, for example, for Summit, that number comes out to be about 20 billion parameters. Now you have 20 billion parameters, and then your magic number of GPUs for that is going to be something like 100 to 200 scale. Beyond that, you're just going to end up spending more time communicating. And the actual flops dipping below some predetermined number by you is going to be whatever your sweet spot ends up being. [00:41:24]Alessio: And then, so this one was like hard for me to go through, so I'm excited to have you run through it, which is a 3D parallelism. [00:41:33]Swyx: It's fancy, it's cutting edge. [00:41:35]Alessio: Yeah, let's talk a bit more about that and some of the work. [00:41:38]Quentin: Okay, 3D parallelism. So what is each dimension? First is the really basic one. That's data parallelism. And data parallelism is you have a copy of the model. Let's say for simplicity, one copy fits on one GPU perfectly. Data parallelism is that now you have two GPUs, so you have one copy on GPU one, one copy on GPU two. Both of them do the forward and backward pass and then synchronize and average the gradients. And then that's a step. Data parallelism for 3D parallelism is actually zero. So it's, you're sharding the optimizer states across all of your different GPUs. Next up is tensor parallelism. Tensor parallelism is you split your model. Like say, if you have two GPUs, you split your model down the middle and each GPU on its tensor specifically is going to do its forward or backward operation on its tensor. And then only when necessary, it'll synchronize that tensor operation with the other GPU. It's a bit more complex than something like pipeline parallelism, which is the third dimension. In pipeline parallelism, let's say you have four layers in your model. And you have four GPUs. You put one layer on each GPU and then GPU one does the forward pass and then sends the output of its activations to GPU two. It does the forward pass, sends activations to three, and you're just moving down a line. That is a naive scheme in that all of the other GPUs are doing nothing while a single GPU is doing its forward or backward pass. So the reason it's called pipeline parallelism is because you're splitting your mini batch into micro batches. So GPU one will do the forward pass on micro batch one and then send to GPU two. And then while GPU two is running on that first micro batch, GPU one is working on the next micro batch. And so you're sort of pipelining the movement and computation of each micro batch. The problem with that is that you need a really big batch size in order to split it up into both mini batches and micro batches. So combining all three of those together, you get a 3D mesh of where each parameter and optimizer state and so on maps to each GPU. And that's 3D parallelism. So let's start diving into details on what have that made sense, what should I jump into more on? [00:43:55]Alessio: I think the main question is, do you need all of the GPUs to be the same to do this? Or can you have mismatching GPUs as well? [00:44:03]Quentin: Okay, two things matter. If there's a difference in VRAM for the two different kinds of GPUs, then you're going to be bottlenecked by whichever GPU has the lower amount of VRAM because it's going to run out of memory. And then you can't like whatever's left on the larger GPUs is going to be empty. As far as I'm aware, there's no like GPU single GPU aware memory overhead scheme that would account for that. The second problem is that let's say all of your GPUs have the same amount of VRAM, but half of them are really slow. And the problem with that is that those synchronizations that I mentioned earlier are going to kill you. So you're going to move as quickly as your slowest GPU in that case. So in both cases, you end up regressing to your slowest or smallest GPU. So you might as well have the same GPUs for all of them. Otherwise, you're wasting the nicer ones. And that also goes to your CPUs and your interconnect. So going back to the 20 billion parameter model that Eleuther was training, that was on a cluster that was sort of Frankenstein made during COVID when there was all of that shortage of network switches and such like that. So every node had a different network switch. And so you ended up moving at the speed of the slowest switch and getting everything tuned properly so that it's not worse than the slowest switch was challenging and is like a real world problem that sometimes comes up. [00:45:28]Alessio: Is this work widely accepted? Like I hadn't learned about this before studying for this episode. Is this something that people are still trying and researching? Or is everybody just aware of this and running this in production? [00:45:43]Quentin: What is this specifically? [00:45:44]Alessio: Like the sharded optimizers plus the 3D parallelism, bringing the two things together and having this kind of mesh strategy. [00:45:51]Quentin: I would say that a lot of major GPT-based models use this scheme. A lot of them now are sort of going with just a pure zero scheme. So just a pure sharded. You just shard everything. And then since that's so easy, everyone gets an equal slice. There's no such thing as a pipeline stage. There's no such thing as what tensor should go on which GPU. Instead, we shard everything equally and treat everything equally. It's a much easier problem to debug, to checkpoint, to run training on than it is with this 3D parallel scheme. I say 3D parallel gives you the most control and also the most ways to go wrong. And depending on whether you have more engineers or whether you have more GPUs, that should decide which of these you go with. [00:46:35]Swyx: It's also not too hard, right? You've basically outlined the five or six different numbers that you need to keep in your head. And it doesn't feel impossible that if you need to achieve that level of control, you've given everybody the main levers to do it with. And that's wonderful. Definitely. [00:46:51]Quentin: The problem that comes up is like, say, like, okay, GPT-4 came out. Now we have VLLMs. [00:46:57]Swyx: Whoa, what are VLLMs? Oh, okay. Virtual LLMs, like the Metro of Expert things? No, like visual. [00:47:03]Quentin: So now you have like multimodal models and such. How do you distribute that? Do you distribute it in a pipeline stage? And do you just shard it? Do you split the tensor and make a tensor parallel? It's sort of hard to change your model and add new features and such when you have this 3D parallel scheme. That's when I say hard. I mean, it's hard to sort of adapt and modify it to new features. [00:47:26]Alessio: I know we're at the hour mark, and I think we put our listeners through a very intense class today. So this was great, Quentin. And we're going to definitely link the article so that people can read it and follow along. Any other research that you're working on in this space that you want to shout out? I know one of our usual, I mean, wrong question is, what's the most interesting unsolved question in AI? So curious to hear if you think it's still on the training inference, math optimization, or are there more areas that people should pay attention to? [00:47:58]Quentin: I think in my area of research, there are two things that I think people should really care about. And the first is multimodal parallelism and RLHF. You were seeing more and more reinforcement learning and coming into the training loop. And so how do you split that some model or some GPUs are working on inference and some GPUs are working on training? And like I mentioned before, you have to relearn everything and they have very unique challenges. How do you split up a KV cache during training, for example? Those are challenges that are not well studied, I don't think. And then multimodal, you have like maybe a vision transformer and a text transformer. How do you split those up? Do you split them up equally? Do you put them on separate GPUs or do you just shard everything? And just maybe one GPU will have some vision, some text parameters. And then the second case I would say is that communication is very often a bottleneck. So we talk about 3D parallelism, but a lot of those like, for example, tensor parallelism, you can't go across nodes with. You'll just get killed in communication. So what I'm getting to is how should you compress your communication before it happens? So on the fly compression, you have some buffer that needs to be communicated. You compress it with a GPU kernel, then you send it across the network and then you decompress it, something like that. Making people spend less money on communication fabrics and more on GPUs as intended is sort of a thing that people need to explore. I think those are my two. [00:49:26]Alessio: Sean, you went over the other half of the lightning round before we wrap it up. [00:49:30]Swyx: That's a good brain dump. Cool. Yeah, I have so many more questions on the multimodal stuff, but that should be for another time. Acceleration, what has already happened in AI that you thought would take much longer? [00:49:42]Quentin: I would say flash attention. Guys, just talk to Tree. And flash attention is just sort of a really great set of kernels that I thought would take a while to get to us. [00:49:51]Alessio: Well, Quentin, thank you very much, man. This was super informative and I think hopefully helps demystify a little bit the blog post. I think people open it and it's like a lot of math on it. And I think you walking them through it was super helpful. So thank you so much for coming on. [00:50:07]Swyx: Of course. [00:50:08]Quentin: And I'm happy to answer any questions that people have offline if they have them. I do read my email. [00:50:13]Swyx: Email and Discord. Of course, yeah. [00:50:15]Quentin: Discord I'm even faster on. [00:50:16]Alessio: Thank you, everyone. [00:50:18]Swyx: Thanks, Quentin. [00:50:19] Get full access to Latent Space at www.latent.space/subscribe
Wed, August 16, 2023
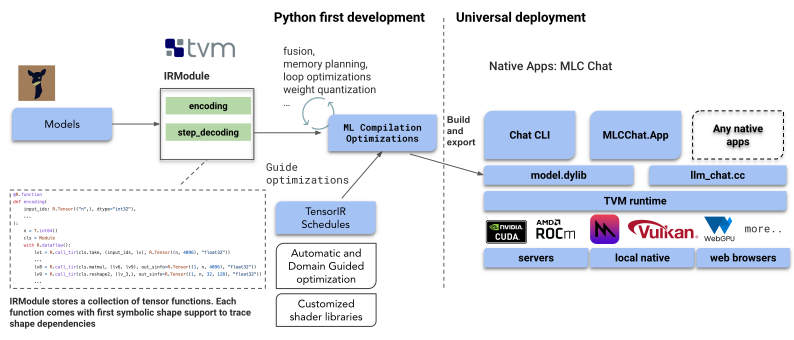
LLMs Everywhere: Running 70B models in browsers and iPhones using MLC — with Tianqi Chen of CMU / OctoML
We have just announced our first set of speakers at AI Engineer Summit! Sign up for the livestream or email sponsors@ai.engineer if you’d like to support.We are facing a massive GPU crunch. As both startups and VC’s hoard Nvidia GPUs like countries count nuclear stockpiles, tweets about GPU shortages have become increasingly common. But what if we could run LLMs with AMD cards, or without a GPU at all? There’s just one weird trick: compilation. And there’s one person uniquely qualified to do it.We had the pleasure to sit down with Tianqi Chen, who’s an Assistant Professor at CMU, where he both teaches the MLC course and runs the MLC group. You might also know him as the creator of XGBoost, Apache TVM, and MXNet, as well as the co-founder of OctoML. The MLC (short for Machine Learning Compilation) group has released a lot of interesting projects:* MLC Chat: an iPhone app that lets you run models like RedPajama-3B and Vicuna-7B on-device. It gets up to 30 tok/s!* Web LLM: Run models like LLaMA-70B in your browser (!!) to offer local inference in your product.* MLC LLM: a framework that allows any language models to be deployed natively on different hardware and software stacks.The MLC group has just announced new support for AMD cards; we previously talked about the shortcomings of ROCm, but using MLC you can get performance very close to the NVIDIA’s counterparts. This is great news for founders and builders, as AMD cards are more readily available. Here are their latest results on AMD’s 7900s vs some of top NVIDIA consumer cards.If you just can’t get a GPU at all, MLC LLM also supports ARM and x86 CPU architectures as targets by leveraging LLVM. While speed performance isn’t comparable, it allows for non-time-sensitive inference to be run on commodity hardware.We also enjoyed getting a peek into TQ’s process, which involves a lot of sketching:With all the other work going on in this space with projects like ggml and Ollama, we’re excited to see GPUs becoming less and less of an issue to get models in the hands of more people, and innovative software solutions to hardware problems!Show Notes* TQ’s Projects:* XGBoost* Apache TVM* MXNet* MLC* OctoML* CMU Catalyst* ONNX* GGML* Mojo* WebLLM* RWKV* HiPPO* Tri Dao’s Episode* George Hotz EpisodePeople:* Carlos Guestrin* Albert GuTimestamps* [00:00:00] Intros* [00:03:41] The creation of XGBoost and its surprising popularity* [00:06:01] Comparing tree-based models vs deep learning* [00:10:33] Overview of TVM and how it works with ONNX* [00:17:18] MLC deep dive* [00:28:10] Using int4 quantization for inference of language models* [00:30:32] Comparison of MLC to other model optimization projects* [00:35:02] Running large language models in the browser with WebLLM* [00:37:47] Integrating browser models into applications* [00:41:15] OctoAI and self-optimizing compute* [00:45:45] Lightning RoundTranscriptAlessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO in Residence at Decibel Partners, and I'm joined by my co-host Swyx, writer and editor of Latent Space. [00:00:20]Swyx: Okay, and we are here with Tianqi Chen, or TQ as people call him, who is assistant professor in ML computer science at CMU, Carnegie Mellon University, also helping to run Catalyst Group, also chief technologist of OctoML. You wear many hats. Are those, you know, your primary identities these days? Of course, of course. [00:00:42]Tianqi: I'm also, you know, very enthusiastic open source. So I'm also a VP and PRC member of the Apache TVM project and so on. But yeah, these are the things I've been up to so far. [00:00:53]Swyx: Yeah. So you did Apache TVM, XGBoost, and MXNet, and we can cover any of those in any amount of detail. But maybe what's one thing about you that people might not learn from your official bio or LinkedIn, you know, on the personal side? [00:01:08]Tianqi: Let me say, yeah, so normally when I do, I really love coding, even though like I'm trying to run all those things. So one thing that I keep a habit on is I try to do sketchbooks. I have a book, like real sketchbooks to draw down the design diagrams and the sketchbooks I keep sketching over the years, and now I have like three or four of them. And it's kind of a usually a fun experience of thinking the design through and also seeing how open source project evolves and also looking back at the sketches that we had in the past to say, you know, all these ideas really turn into code nowadays. [00:01:43]Alessio: How many sketchbooks did you get through to build all this stuff? I mean, if one person alone built one of those projects, he'll be a very accomplished engineer. Like you built like three of these. What's that process like for you? Like it's the sketchbook, like the start, and then you think about the code or like. [00:01:59]Swyx: Yeah. [00:02:00]Tianqi: So, so usually I start sketching on high level architectures and also in a project that works for over years, we also start to think about, you know, new directions, like of course generative AI language model comes in, how it's going to evolve. So normally I would say it takes like one book a year, roughly at that rate. It's usually fun to, I find it's much easier to sketch things out and then gives a more like a high level architectural guide for some of the future items. Yeah. [00:02:28]Swyx: Have you ever published this sketchbooks? Cause I think people would be very interested on, at least on a historical basis. Like this is the time where XGBoost was born, you know? Yeah, not really. [00:02:37]Tianqi: I started sketching like after XGBoost. So that's a kind of missing piece, but a lot of design details in TVM are actually part of the books that I try to keep a record of. [00:02:48]Swyx: Yeah, we'll try to publish them and publish something in the journals. Maybe you can grab a little snapshot for visual aid. Sounds good. [00:02:57]Alessio: Yeah. And yeah, talking about XGBoost, so a lot of people in the audience might know it's a gradient boosting library, probably the most popular out there. And it became super popular because many people started using them in like a machine learning competitions. And I think there's like a whole Wikipedia page of like all state-of-the-art models. They use XGBoost and like, it's a really long list. When you were working on it, so we just had Tri Dao, who's the creator of FlashAttention on the podcast. And I asked him this question, it's like, when you were building FlashAttention, did you know that like almost any transform race model will use it? And so I asked the same question to you when you were coming up with XGBoost, like, could you predict it would be so popular or like, what was the creation process? And when you published it, what did you expect? We have no idea. [00:03:41]Tianqi: Like, actually, the original reason that we built that library is that at that time, deep learning just came out. Like that was the time where AlexNet just came out. And one of the ambitious mission that myself and my advisor, Carlos Guestrin, then is we want to think about, you know, try to test the hypothesis. Can we find alternatives to deep learning models? Because then, you know, there are other alternatives like, you know, support vector machines, linear models, and of course, tree-based models. And our question was, if you build those models and feed them with big enough data, because usually like one of the key characteristics of deep learning is that it's taking a lot [00:04:22]Swyx: of data, right? [00:04:23]Tianqi: So we will be able to get the same amount of performance. That's a hypothesis we're setting out to test. Of course, if you look at now, right, that's a wrong hypothesis, but as a byproduct, what we find out is that, you know, most of the gradient boosting library out there is not efficient enough for us to test that hypothesis. So I happen to have quite a bit of experience in the past of building gradient boosting trees and their variants. So Effective Action Boost was kind of like a byproduct of that hypothesis testing. At that time, I'm also competing a bit in data science challenges, like I worked on KDDCup and then Kaggle kind of become bigger, right? So I kind of think maybe it's becoming useful to others. One of my friends convinced me to try to do a Python binding of it. That tends to be like a very good decision, right, to be effective. Usually when I build it, we feel like maybe a command line interface is okay. And now we have a Python binding, we have R bindings. And then it realized, you know, it started getting interesting. People started contributing different perspectives, like visualization and so on. So we started to push a bit more on to building distributive support to make sure it works on any platform and so on. And even at that time point, when I talked to Carlos, my advisor, later, he said he never anticipated that we'll get to that level of success. And actually, why I pushed for gradient boosting trees, interestingly, at that time, he also disagreed. He thinks that maybe we should go for kernel machines then. And it turns out, you know, actually, we are both wrong in some sense, and Deep Neural Network was the king in the hill. But at least the gradient boosting direction got into something fruitful. [00:06:01]Swyx: Interesting. [00:06:02]Alessio: I'm always curious when it comes to these improvements, like, what's the design process in terms of like coming up with it? And how much of it is a collaborative with like other people that you're working with versus like trying to be, you know, obviously, in academia, it's like very paper-driven kind of research driven. [00:06:19]Tianqi: I would say the extra boost improvement at that time point was more on like, you know, I'm trying to figure out, right. But it's combining lessons. Before that, I did work on some of the other libraries on matrix factorization. That was like my first open source experience. Nobody knew about it, because you'll find, likely, if you go and try to search for the package SVD feature, you'll find some SVN repo somewhere. But it's actually being used for some of the recommender system packages. So I'm trying to apply some of the previous lessons there and trying to combine them. The later projects like MXNet and then TVM is much, much more collaborative in a sense that... But, of course, extra boost has become bigger, right? So when we started that project myself, and then we have, it's really amazing to see people come in. Michael, who was a lawyer, and now he works on the AI space as well, on contributing visualizations. Now we have people from our community contributing different things. So extra boost even today, right, it's a community of committers driving the project. So it's definitely something collaborative and moving forward on getting some of the things continuously improved for our community. [00:07:37]Alessio: Let's talk a bit about TVM too, because we got a lot of things to run through in this episode. [00:07:42]Swyx: I would say that at some point, I'd love to talk about this comparison between extra boost or tree-based type AI or machine learning compared to deep learning, because I think there is a lot of interest around, I guess, merging the two disciplines, right? And we can talk more about that. I don't know where to insert that, by the way, so we can come back to it later. Yeah. [00:08:04]Tianqi: Actually, what I said, when we test the hypothesis, the hypothesis is kind of, I would say it's partially wrong, because the hypothesis we want to test now is, can you run tree-based models on image classification tasks, where deep learning is certainly a no-brainer right [00:08:17]Swyx: now today, right? [00:08:18]Tianqi: But if you try to run it on tabular data, still, you'll find that most people opt for tree-based models. And there's a reason for that, in the sense that when you are looking at tree-based models, the decision boundaries are naturally rules that you're looking at, right? And they also have nice properties, like being able to be agnostic to scale of input and be able to automatically compose features together. And I know there are attempts on building neural network models that work for tabular data, and I also sometimes follow them. I do feel like it's good to have a bit of diversity in the modeling space. Actually, when we're building TVM, we build cost models for the programs, and actually we are using XGBoost for that as well. I still think tree-based models are going to be quite relevant, because first of all, it's really to get it to work out of the box. And also, you will be able to get a bit of interoperability and control monotonicity [00:09:18]Swyx: and so on. [00:09:19]Tianqi: So yes, it's still going to be relevant. I also sometimes keep coming back to think about, are there possible improvements that we can build on top of these models? And definitely, I feel like it's a space that can have some potential in the future. [00:09:34]Swyx: Are there any current projects that you would call out as promising in terms of merging the two directions? [00:09:41]Tianqi: I think there are projects that try to bring a transformer-type model for tabular data. I don't remember specifics of them, but I think even nowadays, if you look at what people are using, tree-based models are still one of their toolkits. So I think maybe eventually it's not even a replacement, it will be just an ensemble of models that you can call. Perfect. [00:10:07]Alessio: Next up, about three years after XGBoost, you built this thing called TVM, which is now a very popular compiler framework for models. Let's talk about, so this came out about at the same time as ONNX. So I think it would be great if you could maybe give a little bit of an overview of how the two things work together. Because it's kind of like the model, then goes to ONNX, then goes to the TVM. But I think a lot of people don't understand the nuances. I can get a bit of a backstory on that. [00:10:33]Tianqi: So actually, that's kind of an ancient history. Before XGBoost, I worked on deep learning for two years or three years. I got a master's before I started my PhD. And during my master's, my thesis focused on applying convolutional restricted Boltzmann machine for ImageNet classification. That is the thing I'm working on. And that was before AlexNet moment. So effectively, I had to handcraft NVIDIA CUDA kernels on, I think, a GTX 2070 card. I have a 22070 card. It took me about six months to get one model working. And eventually, that model is not so good, and we should have picked a better model. But that was like an ancient history that really got me into this deep learning field. And of course, eventually, we find it didn't work out. So in my master's, I ended up working on recommender system, which got me a paper, and I applied and got a PhD. But I always want to come back to work on the deep learning field. So after XGBoost, I think I started to work with some folks on this particular MXNet. At that time, it was like the frameworks of CAFE, Ciano, PyTorch haven't yet come out. And we're really working hard to optimize for performance on GPUs. At that time, I found it's really hard, even for NVIDIA GPU. It took me six months. And then it's amazing to see on different hardwares how hard it is to go and optimize code for the platforms that are interesting. So that gets me thinking, can we build something more generic and automatic? So that I don't need an entire team of so many people to go and build those frameworks. So that's the motivation of starting working on TVM. There is really too little about machine learning engineering needed to support deep learning models on the platforms that we're interested in. I think it started a bit earlier than ONNX, but once it got announced, I think it's in a similar time period at that time. So overall, how it works is that TVM, you will be able to take a subset of machine learning programs that are represented in what we call a computational graph. Nowadays, we can also represent a loop-level program ingest from your machine learning models. Usually, you have model formats ONNX, or in PyTorch, they have FX Tracer that allows you to trace the FX graph. And then it goes through TVM. We also realized that, well, yes, it needs to be more customizable, so it will be able to perform some of the compilation optimizations like fusion operator together, doing smart memory planning, and more importantly, generate low-level code. So that works for NVIDIA and also is portable to other GPU backends, even non-GPU backends [00:13:36]Swyx: out there. [00:13:37]Tianqi: So that's a project that actually has been my primary focus over the past few years. And it's great to see how it started from where I think we are the very early initiator of machine learning compilation. I remember there was a visit one day, one of the students asked me, are you still working on deep learning frameworks? I tell them that I'm working on ML compilation. And they said, okay, compilation, that sounds very ancient. It sounds like a very old field. And why are you working on this? And now it's starting to get more traction, like if you say Torch Compile and other things. I'm really glad to see this field starting to pick up. And also we have to continue innovating here. [00:14:17]Alessio: I think the other thing that I noticed is, it's kind of like a big jump in terms of area of focus to go from XGBoost to TVM, it's kind of like a different part of the stack. Why did you decide to do that? And I think the other thing about compiling to different GPUs and eventually CPUs too, did you already see some of the strain that models could have just being focused on one runtime, only being on CUDA and that, and how much of that went into it? [00:14:50]Tianqi: I think it's less about trying to get impact, more about wanting to have fun. I like to hack code, I had great fun hacking CUDA code. Of course, being able to generate CUDA code is cool, right? But now, after being able to generate CUDA code, okay, by the way, you can do it on other platforms, isn't that amazing? So it's more of that attitude to get me started on this. And also, I think when we look at different researchers, myself is more like a problem solver type. So I like to look at a problem and say, okay, what kind of tools we need to solve that problem? So regardless, it could be building better models. For example, while we build extra boots, we build certain regularizations into it so that it's more robust. It also means building system optimizations, writing low-level code, maybe trying to write assembly and build compilers and so on. So as long as they solve the problem, definitely go and try to do them together. And I also see it's a common trend right now. Like if you want to be able to solve machine learning problems, it's no longer at Aggressor layer, right? You kind of need to solve it from both Aggressor data and systems angle. And this entire field of machine learning system, I think it's kind of emerging. And there's now a conference around it. And it's really good to see a lot more people are starting to look into this. [00:16:10]Swyx: Yeah. Are you talking about ICML or something else? [00:16:13]Tianqi: So machine learning and systems, right? So not only machine learning, but machine learning and system. So there's a conference called MLsys. It's definitely a smaller community than ICML, but I think it's also an emerging and growing community where people are talking about what are the implications of building systems for machine learning, right? And how do you go and optimize things around that and co-design models and systems together? [00:16:37]Swyx: Yeah. And you were area chair for ICML and NeurIPS as well. So you've just had a lot of conference and community organization experience. Is that also an important part of your work? Well, it's kind of expected for academic. [00:16:48]Tianqi: If I hold an academic job, I need to do services for the community. Okay, great. [00:16:53]Swyx: Your most recent venture in MLsys is going to the phone with MLCLLM. You announced this in April. I have it on my phone. It's great. I'm running Lama 2, Vicuña. I don't know what other models that you offer. But maybe just kind of describe your journey into MLC. And I don't know how this coincides with your work at CMU. Is that some kind of outgrowth? [00:17:18]Tianqi: I think it's more like a focused effort that we want in the area of machine learning compilation. So it's kind of related to what we built in TVM. So when we built TVM was five years ago, right? And a lot of things happened. We built the end-to-end machine learning compiler that works, the first one that works. But then we captured a lot of lessons there. So then we are building a second iteration called TVM Unity. That allows us to be able to allow ML engineers to be able to quickly capture the new model and how we demand building optimizations for them. And MLCLLM is kind of like an MLC. It's more like a vertical driven organization that we go and build tutorials and go and build projects like LLM to solutions. So that to really show like, okay, you can take machine learning compilation technology and apply it and bring something fun forward. Yeah. So yes, it runs on phones, which is really cool. But the goal here is not only making it run on phones, right? The goal is making it deploy universally. So we do run on Apple M2 Macs, the 17 billion models. Actually, on a single batch inference, more recently on CUDA, we get, I think, the most best performance you can get out there already on the 4-bit inference. Actually, as I alluded earlier before the podcast, we just had a result on AMD. And on a single batch, actually, we can get the latest AMD GPU. This is a consumer card. It can get to about 80% of the 4019, so NVIDIA's best consumer card out there. So it's not yet on par, but thinking about how diversity and what you can enable and the previous things you can get on that card, it's really amazing that what you can do with this kind of technology. [00:19:10]Swyx: So one thing I'm a little bit confused by is that most of these models are in PyTorch, but you're running this inside a TVM. I don't know. Was there any fundamental change that you needed to do, or was this basically the fundamental design of TVM? [00:19:25]Tianqi: So the idea is that, of course, it comes back to program representation, right? So effectively, TVM has this program representation called TVM script that contains more like computational graph and operational representation. So yes, initially, we do need to take a bit of effort of bringing those models onto the program representation that TVM supports. Usually, there are a mix of ways, depending on the kind of model you're looking at. For example, for vision models and stable diffusion models, usually we can just do tracing that takes PyTorch model onto TVM. That part is still being robustified so that we can bring more models in. On language model tasks, actually what we do is we directly build some of the model constructors and try to directly map from Hugging Face models. The goal is if you have a Hugging Face configuration, we will be able to bring that in and apply optimization on them. So one fun thing about model compilation is that your optimization doesn't happen only as a soft language, right? For example, if you're writing PyTorch code, you just go and try to use a better fused operator at a source code level. Torch compile might help you do a bit of things in there. In most of the model compilations, it not only happens at the beginning stage, but we also apply generic transformations in between, also through a Python API. So you can tweak some of that. So that part of optimization helps a lot of uplifting in getting both performance and also portability on the environment. And another thing that we do have is what we call universal deployment. So if you get the ML program into this TVM script format, where there are functions that takes in tensor and output tensor, we will be able to have a way to compile it. So they will be able to load the function in any of the language runtime that TVM supports. So if you could load it in JavaScript, and that's a JavaScript function that you can take in tensors and output tensors. If you're loading Python, of course, and C++ and Java. So the goal there is really bring the ML model to the language that people care about and be able to run it on a platform they like. [00:21:37]Swyx: It strikes me that I've talked to a lot of compiler people, but you don't have a traditional compiler background. You're inventing your own discipline called machine learning compilation, or MLC. Do you think that this will be a bigger field going forward? [00:21:52]Tianqi: First of all, I do work with people working on compilation as well. So we're also taking inspirations from a lot of early innovations in the field. Like for example, TVM initially, we take a lot of inspirations from Halide, which is just an image processing compiler. And of course, since then, we have evolved quite a bit to focus on the machine learning related compilations. If you look at some of our conference publications, you'll find that machine learning compilation is already kind of a subfield. So if you look at papers in both machine learning venues, the MLC conferences, of course, and also system venues, every year there will be papers around machine learning compilation. And in the compiler conference called CGO, there's a C4ML workshop that also kind of trying to focus on this area. So definitely it's already starting to gain traction and becoming a field. I wouldn't claim that I invented this field, but definitely I helped to work with a lot of folks there. And I try to bring a perspective, of course, trying to learn a lot from the compiler optimizations as well as trying to bring in knowledges in machine learning and systems together. [00:23:07]Alessio: So we had George Hotz on the podcast a few episodes ago, and he had a lot to say about AMD and their software. So when you think about TVM, are you still restricted in a way by the performance of the underlying kernel, so to speak? So if your target is like a CUDA runtime, you still get better performance, no matter like TVM kind of helps you get there, but then that level you don't take care of, right? [00:23:34]Swyx: There are two parts in here, right? [00:23:35]Tianqi: So first of all, there is the lower level runtime, like CUDA runtime. And then actually for NVIDIA, a lot of the mood came from their libraries, like Cutlass, CUDN, right? Those library optimizations. And also for specialized workloads, actually you can specialize them. Because a lot of cases you'll find that if you go and do benchmarks, it's very interesting. Like two years ago, if you try to benchmark ResNet, for example, usually the NVIDIA library [00:24:04]Swyx: gives you the best performance. [00:24:06]Tianqi: It's really hard to beat them. But as soon as you start to change the model to something, maybe a bit of a variation of ResNet, not for the traditional ImageNet detections, but for latent detection and so on, there will be some room for optimization because people sometimes overfit to benchmarks. These are people who go and optimize things, right? So people overfit the benchmarks. So that's the largest barrier, like being able to get a low level kernel libraries, right? In that sense, the goal of TVM is actually we try to have a generic layer to both, of course, leverage libraries when available, but also be able to automatically generate [00:24:45]Swyx: libraries when possible. [00:24:46]Tianqi: So in that sense, we are not restricted by the libraries that they have to offer. That's why we will be able to run Apple M2 or WebGPU where there's no library available because we are kind of like automatically generating libraries. That makes it easier to support less well-supported hardware, right? For example, WebGPU is one example. From a runtime perspective, AMD, I think before their Vulkan driver was not very well supported. Recently, they are getting good. But even before that, we'll be able to support AMD through this GPU graphics backend called Vulkan, which is not as performant, but it gives you a decent portability across those [00:25:29]Swyx: hardware. [00:25:29]Alessio: And I know we got other MLC stuff to talk about, like WebLLM, but I want to wrap up on the optimization that you're doing. So there's kind of four core things, right? Kernel fusion, which we talked a bit about in the flash attention episode and the tiny grab one memory planning and loop optimization. I think those are like pretty, you know, self-explanatory. I think the one that people have the most questions, can you can you quickly explain [00:25:53]Swyx: those? [00:25:54]Tianqi: So there are kind of a different things, right? Kernel fusion means that, you know, if you have an operator like Convolutions or in the case of a transformer like MOP, you have other operators that follow that, right? You don't want to launch two GPU kernels. You want to be able to put them together in a smart way, right? And as a memory planning, it's more about, you know, hey, if you run like Python code, every time when you generate a new array, you are effectively allocating a new piece of memory, right? Of course, PyTorch and other frameworks try to optimize for you. So there is a smart memory allocator behind the scene. But actually, in a lot of cases, it's much better to statically allocate and plan everything ahead of time. And that's where like a compiler can come in. We need to, first of all, actually for language model, it's much harder because dynamic shape. So you need to be able to what we call symbolic shape tracing. So we have like a symbolic variable that tells you like the shape of the first tensor is n by 12. And the shape of the third tensor is also n by 12. Or maybe it's n times 2 by 12. Although you don't know what n is, right? But you will be able to know that relation and be able to use that to reason about like fusion and other decisions. So besides this, I think loop transformation is quite important. And it's actually non-traditional. Originally, if you simply write a code and you want to get a performance, it's very hard. For example, you know, if you write a matrix multiplier, the simplest thing you can do is you do for i, j, k, c, i, j, plus, equal, you know, a, i, k, times b, i, k. But that code is 100 times slower than the best available code that you can get. So we do a lot of transformation, like being able to take the original code, trying to put things into shared memory, and making use of tensor calls, making use of memory copies, and all this. Actually, all these things, we also realize that, you know, we cannot do all of them. So we also make the ML compilation framework as a Python package, so that people will be able to continuously improve that part of engineering in a more transparent way. So we find that's very useful, actually, for us to be able to get good performance very quickly on some of the new models. Like when Lamato came out, we'll be able to go and look at the whole, here's the bottleneck, and we can go and optimize those. [00:28:10]Alessio: And then the fourth one being weight quantization. So everybody wants to know about that. And just to give people an idea of the memory saving, if you're doing FB32, it's like four bytes per parameter. Int8 is like one byte per parameter. So you can really shrink down the memory footprint. What are some of the trade-offs there? How do you figure out what the right target is? And what are the precision trade-offs, too? [00:28:37]Tianqi: Right now, a lot of people also mostly use int4 now for language models. So that really shrinks things down a lot. And more recently, actually, we started to think that, at least in MOC, we don't want to have a strong opinion on what kind of quantization we want to bring, because there are so many researchers in the field. So what we can do is we can allow developers to customize the quantization they want, but we still bring the optimum code for them. So we are working on this item called bring your own quantization. In fact, hopefully MOC will be able to support more quantization formats. And definitely, I think there's an open field that's being explored. Can you bring more sparsities? Can you quantize activations as much as possible, and so on? And it's going to be something that's going to be relevant for quite a while. [00:29:27]Swyx: You mentioned something I wanted to double back on, which is most people use int4 for language models. This is actually not obvious to me. Are you talking about the GGML type people, or even the researchers who are training the models also using int4? [00:29:40]Tianqi: Sorry, so I'm mainly talking about inference, not training, right? So when you're doing training, of course, int4 is harder, right? Maybe you could do some form of mixed type precision for inference. I think int4 is kind of like, in a lot of cases, you will be able to get away with int4. And actually, that does bring a lot of savings in terms of the memory overhead, and so on. [00:30:09]Alessio: Yeah, that's great. Let's talk a bit about maybe the GGML, then there's Mojo. How should people think about MLC? How do all these things play together? I think GGML is focused on model level re-implementation and improvements. Mojo is a language, super sad. You're more at the compiler level. Do you all work together? Do people choose between them? [00:30:32]Tianqi: So I think in this case, I think it's great to say the ecosystem becomes so rich with so many different ways. So in our case, GGML is more like you're implementing something from scratch in C, right? So that gives you the ability to go and customize each of a particular hardware backend. But then you will need to write from CUDA kernels, and you write optimally from AMD, and so on. So the kind of engineering effort is a bit more broadened in that sense. Mojo, I have not looked at specific details yet. I think it's good to start to say, it's a language, right? I believe there will also be machine learning compilation technologies behind it. So it's good to say, interesting place in there. In the case of MLC, our case is that we do not want to have an opinion on how, where, which language people want to develop, deploy, and so on. And we also realize that actually there are two phases. We want to be able to develop and optimize your model. By optimization, I mean, really bring in the best CUDA kernels and do some of the machine learning engineering in there. And then there's a phase where you want to deploy it as a part of the app. So if you look at the space, you'll find that GGML is more like, I'm going to develop and optimize in the C language, right? And then most of the low-level languages they have. And Mojo is that you want to develop and optimize in Mojo, right? And you deploy in Mojo. In fact, that's the philosophy they want to push for. In the ML case, we find that actually if you want to develop models, the machine learning community likes Python. Python is a language that you should focus on. So in the case of MLC, we really want to be able to enable, not only be able to just define your model in Python, that's very common, right? But also do ML optimization, like engineering optimization, CUDA kernel optimization, memory planning, all those things in Python that makes you customizable and so on. But when you do deployment, we realize that people want a bit of a universal flavor. If you are a web developer, you want JavaScript, right? If you're maybe an embedded system person, maybe you would prefer C++ or C or Rust. And people sometimes do like Python in a lot of cases. So in the case of MLC, we really want to have this vision of, you optimize, build a generic optimization in Python, then you deploy that universally onto the environments that people like. [00:32:54]Swyx: That's a great perspective and comparison, I guess. One thing I wanted to make sure that we cover is that I think you are one of these emerging set of academics that also very much focus on your artifacts of delivery. Of course. Something we talked about for three years, that he was very focused on his GitHub. And obviously you treated XGBoost like a product, you know? And then now you're publishing an iPhone app. Okay. Yeah. Yeah. What is his thinking about academics getting involved in shipping products? [00:33:24]Tianqi: I think there are different ways of making impact, right? Definitely, you know, there are academics that are writing papers and building insights for people so that people can build product on top of them. In my case, I think the particular field I'm working on, machine learning systems, I feel like really we need to be able to get it to the hand of people so that really we see the problem, right? And we show that we can solve a problem. And it's a different way of making impact. And there are academics that are doing similar things. Like, you know, if you look at some of the people from Berkeley, right? A few years, they will come up with big open source projects. Certainly, I think it's just a healthy ecosystem to have different ways of making impacts. And I feel like really be able to do open source and work with open source community is really rewarding because we have a real problem to work on when we build our research. Actually, those research bring together and people will be able to make use of them. And we also start to see interesting research challenges that we wouldn't otherwise say, right, if you're just trying to do a prototype and so on. So I feel like it's something that is one interesting way of making impact, making contributions. [00:34:40]Swyx: Yeah, you definitely have a lot of impact there. And having experience publishing Mac stuff before, the Apple App Store is no joke. It is the hardest compilation, human compilation effort. So one thing that we definitely wanted to cover is running in the browser. You have a 70 billion parameter model running in the browser. That's right. Can you just talk about how? Yeah, of course. [00:35:02]Tianqi: So I think that there are a few elements that need to come in, right? First of all, you know, we do need a MacBook, the latest one, like M2 Max, because you need the memory to be big enough to cover that. So for a 70 million model, it takes you about, I think, 50 gigahertz of RAM. So the M2 Max, the upper version, will be able to run it, right? And it also leverages machine learning compilation. Again, what we are doing is the same, whether it's running on iPhone, on server cloud GPUs, on AMDs, or on MacBook, we all go through that same MOC pipeline. Of course, in certain cases, maybe we'll do a bit of customization iteration for either ones. And then it runs on the browser runtime, this package of WebLM. So that will effectively... So what we do is we will take that original model and compile to what we call WebGPU. And then the WebLM will be to pick it up. And the WebGPU is this latest GPU technology that major browsers are shipping right now. So you can get it in Chrome for them already. It allows you to be able to access your native GPUs from a browser. And then effectively, that language model is just invoking the WebGPU kernels through there. So actually, when the LATMAR2 came out, initially, we asked the question about, can you run 17 billion on a MacBook? That was the question we're asking. So first, we actually... Jin Lu, who is the engineer pushing this, he got 17 billion on a MacBook. We had a CLI version. So in MLC, you will be able to... That runs through a metal accelerator. So effectively, you use the metal programming language to get the GPU acceleration. So we find, okay, it works for the MacBook. Then we asked, we had a WebGPU backend. Why not try it there? So we just tried it out. And it's really amazing to see everything up and running. And actually, it runs smoothly in that case. So I do think there are some kind of interesting use cases already in this, because everybody has a browser. You don't need to install anything. I think it doesn't make sense yet to really run a 17 billion model on a browser, because you kind of need to be able to download the weight and so on. But I think we're getting there. Effectively, the most powerful models you will be able to run on a consumer device. It's kind of really amazing. And also, in a lot of cases, there might be use cases. For example, if I'm going to build a chatbot that I talk to it and answer questions, maybe some of the components, like the voice to text, could run on the client side. And so there are a lot of possibilities of being able to have something hybrid that contains the edge component or something that runs on a server. [00:37:47]Alessio: Do these browser models have a way for applications to hook into them? So if I'm using, say, you can use OpenAI or you can use the local model. Of course. [00:37:56]Tianqi: Right now, actually, we are building... So there's an NPM package called WebILM, right? So that you will be able to, if you want to embed it onto your web app, you will be able to directly depend on WebILM and you will be able to use it. We are also having a REST API that's OpenAI compatible. So that REST API, I think, right now, it's actually running on native backend. So that if a CUDA server is faster to run on native backend. But also we have a WebGPU version of it that you can go and run. So yeah, we do want to be able to have easier integrations with existing applications. And OpenAI API is certainly one way to do that. Yeah, this is great. [00:38:37]Swyx: I actually did not know there's an NPM package that makes it very, very easy to try out and use. I want to actually... One thing I'm unclear about is the chronology. Because as far as I know, Chrome shipped WebGPU the same time that you shipped WebILM. Okay, yeah. So did you have some kind of secret chat with Chrome? [00:38:57]Tianqi: The good news is that Chrome is doing a very good job of trying to have early release. So although the official shipment of the Chrome WebGPU is the same time as WebILM, actually, you will be able to try out WebGPU technology in Chrome. There is an unstable version called Canary. I think as early as two years ago, there was a WebGPU version. Of course, it's getting better. So we had a TVM-based WebGPU backhand two years ago. Of course, at that time, there were no language models. It was running on less interesting, well, still quite interesting models. And then this year, we really started to see it getting matured and performance keeping up. So we have a more serious push of bringing the language model compatible runtime onto the WebGPU. [00:39:45]Swyx: I think you agree that the hardest part is the model download. Has there been conversations about a one-time model download and sharing between all the apps that might use this API? That is a great point. [00:39:58]Tianqi: I think it's already supported in some sense. When we download the model, WebILM will cache it onto a special Chrome cache. So if a different web app uses the same WebILM JavaScript package, you don't need to redownload the model again. So there is already something there. But of course, you have to download the model once at least to be able to use it. [00:40:19]Swyx: Okay. One more thing just in general before we're about to zoom out to OctoAI. Just the last question is, you're not the only project working on, I guess, local models. That's right. Alternative models. There's gpt4all, there's olama that just recently came out, and there's a bunch of these. What would be your advice to them on what's a valuable problem to work on? And what is just thin wrappers around ggml? Like, what are the interesting problems in this space, basically? [00:40:45]Tianqi: I think making API better is certainly something useful, right? In general, one thing that we do try to push very hard on is this idea of easier universal deployment. So we are also looking forward to actually have more integration with MOC. That's why we're trying to build API like WebILM and other things. So we're also looking forward to collaborate with all those ecosystems and working support to bring in models more universally and be able to also keep up the best performance when possible in a more push-button way. [00:41:15]Alessio: So as we mentioned in the beginning, you're also the co-founder of Octomel. Recently, Octomel released OctoAI, which is a compute service, basically focuses on optimizing model runtimes and acceleration and compilation. What has been the evolution there? So Octo started as kind of like a traditional MLOps tool, where people were building their own models and you help them on that side. And then it seems like now most of the market is shifting to starting from pre-trained generative models. Yeah, what has been that experience for you and what you've seen the market evolve? And how did you decide to release OctoAI? [00:41:52]Tianqi: One thing that we found out is that on one hand, it's really easy to go and get something up and running, right? So if you start to consider there's so many possible availabilities and scalability issues and even integration issues since becoming kind of interesting and complicated. So we really want to make sure to help people to get that part easy, right? And now a lot of things, if we look at the customers we talk to and the market, certainly generative AI is something that is very interesting. So that is something that we really hope to help elevate. And also building on top of technology we build to enable things like portability across hardwares. And you will be able to not worry about the specific details, right? Just focus on getting the model out. We'll try to work on infrastructure and other things that helps on the other end. [00:42:45]Alessio: And when it comes to getting optimization on the runtime, I see when we run an early adopters community and most enterprises issue is how to actually run these models. Do you see that as one of the big bottlenecks now? I think a few years ago it was like, well, we don't have a lot of machine learning talent. We cannot develop our own models. Versus now it's like, there's these great models you can use, but I don't know how to run them efficiently. [00:43:12]Tianqi: That depends on how you define by running, right? On one hand, it's easy to download your MLC, like you download it, you run on a laptop, but then there's also different decisions, right? What if you are trying to serve a larger user request? What if that request changes? What if the availability of hardware changes? Right now it's really hard to get the latest hardware on media, unfortunately, because everybody's trying to work on the things using the hardware that's out there. So I think when the definition of run changes, there are a lot more questions around things. And also in a lot of cases, it's not only about running models, it's also about being able to solve problems around them. How do you manage your model locations and how do you make sure that you get your model close to your execution environment more efficiently? So definitely a lot of engineering challenges out there. That we hope to elevate, yeah. And also, if you think about our future, definitely I feel like right now the technology, given the technology and the kind of hardware availability we have today, we will need to make use of all the possible hardware available out there. That will include a mechanism for cutting down costs, bringing something to the edge and cloud in a more natural way. So I feel like still this is a very early stage of where we are, but it's already good to see a lot of interesting progress. [00:44:35]Alessio: Yeah, that's awesome. I would love, I don't know how much we're going to go in depth into it, but what does it take to actually abstract all of this from the end user? You know, like they don't need to know what GPUs you run, what cloud you're running them on. You take all of that away. What was that like as an engineering challenge? [00:44:51]Tianqi: So I think that there are engineering challenges on. In fact, first of all, you will need to be able to support all the kind of hardware backhand you have, right? On one hand, if you look at the media library, you'll find very surprisingly, not too surprisingly, most of the latest libraries works well on the latest GPU. But there are other GPUs out there in the cloud as well. So certainly being able to have know-hows and being able to do model optimization is one thing, right? Also infrastructures on being able to scale things up, locate models. And in a lot of cases, we do find that on typical models, it also requires kind of vertical iterations. So it's not about, you know, build a silver bullet and that silver bullet is going to solve all the problems. It's more about, you know, we're building a product, we'll work with the users and we find out there are interesting opportunities in a certain point. And when our engineer will go and solve that, and it will automatically reflect it in a service. [00:45:45]Swyx: Awesome. [00:45:46]Alessio: We can jump into the lightning round until, I don't know, Sean, if you have more questions or TQ, if you have more stuff you wanted to talk about that we didn't get a chance to [00:45:54]Swyx: touch on. [00:45:54]Alessio: Yeah, we have talked a lot. [00:45:55]Swyx: So, yeah. We always would like to ask, you know, do you have a commentary on other parts of AI and ML that is interesting to you? [00:46:03]Tianqi: So right now, I think one thing that we are really pushing hard for is this question about how far can we bring open source, right? I'm kind of like a hacker and I really like to put things together. So I think it's unclear in the future of what the future of AI looks like. On one hand, it could be possible that, you know, you just have a few big players, you just try to talk to those bigger language models and that can do everything, right? On the other hand, one of the things that Wailing Academic is really excited and pushing for, that's one reason why I'm pushing for MLC, is that can we build something where you have different models? You have personal models that know the best movie you like, but you also have bigger models that maybe know more, and you get those models to interact with each other, right? And be able to have a wide ecosystem of AI agents that helps each person while still being able to do things like personalization. Some of them can run locally, some of them, of course, running on a cloud, and how do they interact with each other? So I think that is a very exciting time where the future is yet undecided, but I feel like there is something we can do to shape that future as well. [00:47:18]Swyx: One more thing, which is something I'm also pursuing, which is, and this kind of goes back into predictions, but also back in your history, do you have any idea, or are you looking out for anything post-transformers as far as architecture is concerned? [00:47:32]Tianqi: I think, you know, in a lot of these cases, you can find there are already promising models for long contexts, right? There are space-based models, where like, you know, a lot of some of our colleagues from Albert, who he worked on this HIPPO models, right? And then there is an open source version called RWKV. It's like a recurrent models that allows you to summarize things. Actually, we are bringing RWKV to MOC as well, so maybe you will be able to see one of the models. [00:48:00]Swyx: We actually recorded an episode with one of the RWKV core members. It's unclear because there's no academic backing. It's just open source people. Oh, I see. So you like the merging of recurrent networks and transformers? [00:48:13]Tianqi: I do love to see this model space continue growing, right? And I feel like in a lot of cases, it's just that attention mechanism is getting changed in some sense. So I feel like definitely there are still a lot of things to be explored here. And that is also one reason why we want to keep pushing machine learning compilation, because one of the things we are trying to push in was productivity. So that for machine learning engineering, so that as soon as some of the models came out, we will be able to, you know, empower them onto those environments that's out there. [00:48:43]Swyx: Yeah, it's a really good mission. Okay. Very excited to see that RWKV and state space model stuff. I'm hearing increasing chatter about that stuff. Okay. Lightning round, as always fun. I'll take the first one. Acceleration. What has already happened in AI that you thought would take much longer? [00:48:59]Tianqi: Emergence of more like a conversation chatbot ability is something that kind of surprised me before it came out. This is like one piece that I feel originally I thought would take much longer, but yeah, [00:49:11]Swyx: it happens. And it's funny because like the original, like Eliza chatbot was something that goes all the way back in time. Right. And then we just suddenly came back again. Yeah. [00:49:21]Tianqi: It's always too interesting to think about, but with a kind of a different technology [00:49:25]Swyx: in some sense. [00:49:25]Alessio: What about the most interesting unsolved question in AI? [00:49:31]Swyx: That's a hard one, right? [00:49:32]Tianqi: So I can tell you like what kind of I'm excited about. So, so I think that I have always been excited about this idea of continuous learning and lifelong learning in some sense. So how AI continues to evolve with the knowledges that have been there. It seems that we're getting much closer with all those recent technologies. So being able to develop systems, support, and be able to think about how AI continues to evolve is something that I'm really excited about. [00:50:01]Swyx: So specifically, just to double click on this, are you talking about continuous training? That's like a training. [00:50:06]Tianqi: I feel like, you know, training adaptation and it's all similar things, right? You want to think about entire life cycle, right? The life cycle of collecting data, training, fine tuning, and maybe have your local context that getting continuously curated and feed onto models. So I think all these things are interesting and relevant in here. [00:50:29]Swyx: Yeah. I think this is something that people are really asking, you know, right now we have moved a lot into the sort of pre-training phase and off the shelf, you know, the model downloads and stuff like that, which seems very counterintuitive compared to the continuous training paradigm that people want. So I guess the last question would be for takeaways. What's basically one message that you want every listener, every person to remember today? [00:50:54]Tianqi: I think it's getting more obvious now, but I think one of the things that I always want to mention in my talks is that, you know, when you're thinking about AI applications, originally people think about algorithms a lot more, right? Our algorithm models, they are still very important. But usually when you build AI applications, it takes, you know, both algorithm side, the system optimizations, and the data curations, right? So it takes a connection of so many facades to be able to bring together an AI system and be able to look at it from that holistic perspective is really useful when we start to build modern applications. I think it's going to continue going to be more important in the future. [00:51:35]Swyx: Yeah. Thank you for showing the way on this. And honestly, just making things possible that I thought would take a lot longer. So thanks for everything you've done. [00:51:46]Tianqi: Thank you for having me. [00:51:47]Swyx: Yeah. [00:51:47]Alessio: Thanks for coming on TQ. [00:51:49]Swyx: Have a good one. [00:51:49] Get full access to Latent Space at www.latent.space/subscribe
Thu, August 10, 2023

[AI Breakdown] Summer AI Technical Roundup: a Latent Space x AI Breakdown crossover pod!
Our 3rd podcast feed swap with other AI pod friends! Check out Cognitive Revolution and Practical AI as well.NLW is the best daily AI YouTube/podcaster with the AI Breakdown. His summaries and content curation are spot on and always finds the interesting angle that will keep you thinking. Subscribe to the AI Breakdown wherever fine podcasts are sold! https://pod.link/1680633614You can also watch on YouTube:Timestampscourtesy of summarize.techThe hosts discuss the launch of Code Interpreter as a separate model from OpenAI and speculate that it represents the release of GPT 4.5. People have found Code Interpreter to be better than expected, even for tasks unrelated to coding. They discuss the significance of this release, as well as the challenges of evaluating AI models, the cultural mismatch between researchers and users, and the increasing value of data in the AI industry. They also touch on the impact of open-source tools, the potential of AI companions, the advantages of Anthropics compared to other platforms, advancements in image recognition and multimodality, and predictions for the future of AI.* 00:00:00 In this section, the hosts discuss the launch of Code Interpreter from OpenAI and its significance in the development of the AI field. They explain that Code Interpreter, initially introduced as a plugin, is now considered a separate model with its own dropdown menu. They note that people have found Code Interpreter to be better than expected, even for tasks that are not related to coding. This leads them to speculate that Code Interpreter actually represents the release of GPT 4.5, as there has been no official announcement or blog post about it. They also mention that the AI safety concerns and regulatory environment may be impacting how OpenAI names and labels their models. Overall, they believe that Code Interpreter's release signifies a significant shift in the AI field and hints at the possibility of future advanced models like GPT 5.* 00:05:00 In this section, the speaker discusses the improvements in GPT 4.5 and how it enhances the experience for non-coding queries and inputs. They explain that the code interpreter feature allows for a wider range of use cases that were not possible with previous models like GPT 3.5. Additionally, they highlight the value of the code interpreter in assisting individuals with no coding experience to solve basic coding problems. This feature is likened to having a junior developer or intern analyst that aids in conducting tests and simplifies coding tasks. The speaker emphasizes that GPT 4.5 enables users to be more productive and efficient, especially when dealing with code-related challenges. They also discuss the future direction of AGI, where more time will be dedicated to inference rather than training, as this approach has shown significant improvements in terms of problem-solving.* 00:10:00 In this section, the speaker discusses how advanced AI models like GPT-4.5 are not just larger versions of previous models but rather employ fundamentally different techniques. They compare the evolution of AI models to the evolutionary timeline of humans, where the invention of tools opened up a whole new set of possibilities. They touch on the difficulty of evaluating AI models, particularly in more subjective tasks, and highlight how perceptions of model performance can be influenced by factors like formatting preferences. Additionally, the speaker mentions the challenges of reinforcement learning and the uncertainty around what the model is prioritizing in its suggestions. They conclude that OpenAI, as a research lab, is grappling with the complexities of updating models and ensuring reliability for users.* 00:15:00 In this section, the speaker discusses the cultural mismatch between OpenAI researchers and users of OpenAI's products, highlighting the conflicting statements made about model updates. They suggest that OpenAI needs to establish a policy that everyone can accept. The speaker also emphasizes the challenges of communication and the difficulty of serving different stakeholders. They mention the impact of small disruptions on workflows and the lack of immediate feedback within OpenAI's system. Additionally, the speaker briefly discusses the significance of OpenAI's custom instructions feature, stating that it allows for more personalization but is not fundamentally different from what other chat companies already offer. The discussion then transitions to Facebook's release of LAMA2, which holds significance both technically and for users, although further details on its significance are not provided in this excerpt.* 00:20:00 In this section, the introduction of GPT-4.5, also known as LAVA 2, is discussed. LAVA 2 is the first fully commercially usable GPT 3.5 equivalent model, which is a significant development because it allows users to run it on their own infrastructure and fine-tune it according to their needs. Although it is not fully open source, it presents new opportunities for various industries such as government, healthcare, and finance. The discussion also touches upon the open source aspect of LAVA 2, with the recognition that it has still contributed significantly to the community, as evidenced by the three million dollars' worth of compute and the estimated 15 to 20 million dollars' worth of additional fine-tuning capabilities it brings. The conversation acknowledges the value of open source models and data, while also recognizing the challenges and complexities in striking a balance between openness and restrictions.-* 00:25:00 In this section, the discussion centers around the commoditization of compute and the increasing value of data in the AI industry. While GPU compute is currently in high demand, it is observed that data is what holds the real value in AI. The conversation touches on the history of Open Source models and how the release of data for models like GPT J and GPT Neo signal a shift towards prioritizing data over model weights. The transcript also mentions the caution around data usage, citing examples of copyright concerns with datasets like Bookcorpus. The debate arises on whether ML engineers should proactively use open data or wait for permission, with some arguing for proactive usage to avoid holding back progress. The conversation also discusses the importance of terminology and protecting the definition of open source, while recognizing that the functional implications of open data are what matter most.* 00:30:00 In this section, the conversation revolves around the impact of open-source tools on companies and how it has influenced their approach to AI development. It is noted that companies can no longer just offer a nice user interface (UI) wrapper around an open AI model, as customers are demanding more. The competition has shifted towards other aspects of productionizing AI applications, which is seen as a positive development. The speaker predicts that OpenAI's competitive pressure will lead to opening up their source code and expects interesting advancements to emerge, such as running models locally for unlimited use. Additionally, the conversation touches on the potential of commercially available models, the application of new techniques, and the creativity unlocked by open source. The speaker also mentions the AI girlfriend economy, an area that is often overlooked but has millions of users and significant financial success.* 00:35:00 In this section, the speaker discusses their prediction about the long-term impact of AI on interpersonal relationships, suggesting that AI companions, such as AI girlfriends or boyfriends, could help address the loneliness crisis and reduce incidents of violence. They also mention the idea of using AI models to improve social interactions and communication skills. However, they highlight that this idea of AI companions may face resistance from older generations who may struggle to accept their legitimacy. The speaker also mentions an example of using AI models to create a mental wellness product in the form of a private journal. Overall, the speaker believes that while AI companions may have potential, they may not completely replace human relationships and interactions.* 00:40:00 In this section, the speaker discusses their views on Anthropics and the advantages it offers compared to other platforms. They mention that while Anthropics used to position themselves as the safer alternative to OpenAI, it was not appealing to many engineers. However, with the introduction of the 100K contest window and the ability to upload multiple files, Anthropics has become state-of-the-art in certain dimensions, such as latency and reliability in code synthesis. The speaker also notes that some businesses are choosing to build with the Anthropics API over OpenAI due to these advantages. They believe that Anthropics is finally finding its foothold after being overshadowed by OpenAI for a long time. Additionally, the speaker discusses their experience at the Anthropics hackathon, where they saw developer excitement for the platform. They believe that Anthropics is on its way up and that it paves the way for a multi-model future. However, they also acknowledge that the odds are stacked against Anthropics and that it needs more marketing support and community buy-in. Lastly, the speaker mentions the importance of running chats side by side against different models like Tracicia and GPT-4.5, and highlights that in their experience, Anthropics wins about 30% of the time, making it a valuable addition to one's toolkit.* 00:45:00 In this section, the discussion revolves around the advancements in image recognition and multimodality in language models like GPT-4.5. While there was some excitement about these developments, it was noted that relying on model updates alone may not be sufficient, and there is a need to focus on product-level improvements, such as integrating language models into services like Google Maps. However, concerns were raised about the reliability of updates, as evidenced by a regression in Bard's code interpreter functionality. Additionally, other trends in the developer community, like the emergence of auto GPT projects and the ongoing quest for building useful agents, were highlighted. Finally, there was mention of the growing interest in evaluation-focused companies like LangChain and LaunchLang, which aim to monitor the success of prompts and agents.* 00:50:00 In this section, the speaker discusses the focus on model evaluation and observability, as well as the importance of combining deep industry expertise with AI technology to make improvements. They also touch on the need for creating an information hierarchy between documents and scoring them in specific verticals like Finance. The speaker mentions advancements in text-to-image capabilities and expresses interest in character AI and AI-native social media. They mention the possibility of AI personas from Meta and the development of agent clouds optimized for EI agents. They acknowledge that these advancements may raise concerns among AI safety proponents. Overall, there seems to be excitement and exploration around these emerging technologies.* 00:55:00 In this section, the speakers discuss their predictions and what they are closely watching in the coming months. Alice believes that there will be more public talk about open source models being used in production, as currently, many perceive them as just toys. She expects companies to start deploying these models and showcasing their usage. Sean predicts the rise of AI engineers as a profession, with people transitioning from informal groups to certified professionals working in AI teams within companies. He mentions that the first AI engineer within Meta has already been announced. Overall, they anticipate a relatively quiet August followed by a resurgence of activity in September, with events like Facebook Connect and continued hackathons driving innovation.Transcriptall right what is going on how's it going boys great to have you here hey good how are y'all good I I think I'm excited for this yeah no I'm super excited I think uh you know we were just talking a little bit before this that the AI audience right now is really interesting it's sort of on the one hand you have of course the folks who are actually in it who are building in it who are you know or or dabbling because they're in some other field but they're fascinated by it and you know are spending their nights in weekends building and then on the other hand you have the folks who are you know what we used to call non-technical perhaps but who are actively paying attention in a way that I think is very different to the technical evolutions of this field because they have a sense or an understanding that it's so fast moving that the place that they have to be paying attention to is you know what's changing from the standpoint of of developers and Builders so I what we want to do today is kind of reflect on the month of July which had a couple of I think really Keystone events in the context of what it means for the technical development of the AI field and and what you know where it leads how people's Frameworks are changing how people sort of sense that things have changed over the last month and I think that the place to start although we could choose a lot of different examples is with an idea that you guys have spent a lot of time sharing on Twitter and in other places that the launch of code interpreter from openai which is nominally a chat GPT plugin actually represents functionally something closer to the release of GPT 4.5 so maybe we can start by just having you guys sort of explain that idea uh and then we can kind of take it from there yeah I'll maybe start with this one um yeah so quote interpreter was first announced as a plug-in at least in the plugins announcement from March but from the start it was already presented as a separate model because at least when you look in the UI you know you don't go into the charity plugin see why and pick it from a menu plugins it is actually a separate model in in the drop down menu and it is so today and I think um yes it adds on an additional sandbox for running and testing code and iterating on that um and actually you can upload files to it and do operations and files and people are having a lot of fun uploading different batteries and hacking uh to see what the container is and try to break out into the Container um but what really convinced me that it might be a separate model was when people tried it on tasks that were not code and found it better so code interpreter is poorly named not just because you know it just sounds like a like a weird developer Tool uh but they basically it's kind of maybe hiding some progress that openai has made that it's completely not been public about there's no blog post about it what interpreter itself is launched in a support Forum post uh you know low-key it wouldn't even announced by any of the major uh public channels that opening has um and so the leading theory is that you know I've dubbed a gpp 4.5 I think like if they were ever to release an API for that they might retroactively rename it for coin firings in the same way that 3.5 was actually renamed when retracted between three rooms um and I think and since I published that post or tweeted that stuff uh the the leading release now for why they did not do it is because they would piss off all the AI safety people yeah no I mean it would it was sort of correspondent obviously like a thing that's happened less just this month but more over the last three months is a total Overton window shift in that AI safety conversation starting from I think about in April or May when um Jeffrey Hinton left Google there has been a big shift in that conversation obviously Regulators are way more active now than they were even a couple months ago and so I do think that there are probably constraints in how you know open AI at any other company in the space feel like they can label or name things and even just as we're recording this today we just saw a trademark for gpt5 which is sort of most likely I think just um you know dotting the eyes and crossing the t's as a company because they're eventually going to have a gpt5 um I I would be very shocked if it I would be very shocked at this point if there are any models that are clearly ahead of gpt4 that don't that that come out before there is some pretty clear guidance from the US government around what it looks like to release more advanced models than gpt4 so it's an interesting interesting moment I guess let's talk about what functionally it means for it to be you know that much better better enough that we would call it GPT 4.5 and maybe what might be useful is breaking that apart into how it is improving the experience for non-coding queries or you know or or or or or inputs and then separately you know how it is made uh to chat gbt as a as a as a coding support tool different as well I think there's a lot of things to think about so one models are usually benchmarked against certain tasks and you know that works for development but then there's the reality of the model that you know if you ask for example mathematical question the like gpd3 3.5 you don't really get good responses because of how um digits are tokenized in the model so it's hard for the models to actually reason about numbers but now that you put a code interpreter in it all of a sudden it's not a map in the tokenizer in the latent space question it's like can you write code that answers the math question so that kind of enables a lot more use cases that are just not possible with the Transformer architecture of the underlying model and then the other thing is that when it first came out people were like oh this is great for developers it's like I know what to do I just ask it but there's this whole other side of the water which is hey I have this like very basic thing you know how I'm a software engineer but background you know how sometimes people that have no coding experience come to you and it's like hey I know this is like really hard but could you help me do this and it's like it's really easy and sometimes it and sometimes they think it's easy and it's hard but uh code interpreter enables that whole um space of problems to be solved independently by people so it's kind of having you know Sean talked about this before about um some of these models being like a junior developer that you have on staff for you to be more productive this is similar for non-business people it's like having Junior you know whatever like a intern analyst that helps you do these tests that are not even like software engineering tasks it's more like code is just a language used to express them it's like a pretty basic stuff sometimes uh but you just cannot cannot do it without so uh for me the gbd4 4.5 thing is less about you know is this a new model that is like built after gbd4 it's more about capability so if you have gbt4 versus 4.5 you're probably gonna get more stuff done with 4.5 just because of like the code interpreter Peace So for me that's enough to use the code name but as you said Sam Allman said they're not training the next model so they said this is 4.5 you would have like it would go back to Washington DC and be in front of Congress and have to talk about it again sorry yeah um well one thing that I always want to impress upon people is we're not just talking about like yes it is writing code for you but actually you know if you step back away from the code and just think about what it's doing is it's having the ability to spend more Insurance time on harder problems and it matches what uh we do when we are faced with difficult problems as well because right now any llm and these before code interpreter any llm if you give it a question like what is one plus two it'll it'll take the same amount of time to respond as uh something like prove the Black Shoals theorem right like uh and that should not be the case actually we should take more time to think when we are considering harder problems um and I think what I think the next Frontier and why I called it 4.5 is not just because it has had extra training it's not just because it has the coding environment and also because there's a general philosophy and move that I see on my open EI um and the people that it hires that so in my blog post I called out gong who like I first slowly met so it's kind of awkward to talk about it like I guess a friend or a friend of a friend um but it's true that I have met multiple people not opening I have specifically been hired to work on more inference time uh optimizations as compared to trading time um and I think that is the future for gpd5s right so the reason you the reason I think about this working client is that this is the direction of AGI that we're going to spend more time on inference um and uh it just makes a whole lot of sense when you look at gnomes background working on the uh the broadest and then Cicero um all of which is just consistently the same result which is every second or millisecond extra spent on inference it's worth like 10 000 of that of of that in training especially when you can vary it based on the problem difficulty um and this is basically uh ties back to the origin of open AI which originally started playing games they used to play DotA they used to play uh you know all sorts of all sorts of games in sort of those reinforcement learning environments and the typical way that your program these AI is doing doing uh doing these games is when they have lots of branches and you take more time to Circle and um and figure out what the optimal strategy is and when there's not that many branches to to go down then you just take the shortcut in uh you have to give to give the right answer but varying the inference time is the integration here one of the things that it it seems and this what you just described I think aligns with this is I think there's a perception that uh more advanced models are just going to be bigger data sets with more of the same type of training versus sort of fundamentally different techniques or different areas of emphasis that go beyond just how big the data set is and so you know one of the things that strikes me listening to or kind of observing how code interpreter works is it almost feels like a break in The evolutionary timeline of gbt because it's like GPT with tools right unless you just kind of described it it's like it doesn't know about math it doesn't have to know about math if it can write code to figure out the math right so what it needs is the tool of being able to write code and that allows it to figure something out and that is akin to you know humans are evolving for Millennia not using tools then all of a sudden someone picks up a rock and this whole entire set of things that we couldn't do before just based on our own evolutionary pathway are now open to us because of the use of the tool I don't think it's a Perfect Analogy but it does feel somewhat closer to that than just again like it's a little bit better than 3.5 so we called it four it's a little bit better than four so we called it 4.5 kind of a mental framework yeah noise I made there I guess sort of the the another big topic that relates to this that was subject of a lot of conversation not just this month that has been for a couple months is this question of whether gpt4 has gotten worse or whether it's been nerfed and there was some research that came out around that with maybe um variable variable uh sort of feelings around it but what did you guys make of that whole conversation I think evals are one of the hardest things in the space so I've had this discussion with Founders before it's really easy we always bring up co-pilot as one example of like Cutting Edge eval where they not not only look at how much um of their suggestions you accept but also how much of the code is still in a minute after three minutes after five minutes after it's really easy to do for code but like for more open and degenerative tasks it's kind of hard to say what's good and what isn't you know like if I'm asking to write the show notes for our podcast which has never been able to do um how do you how do you email that it's really hard so even if you read through through the paper that uh Ling Zhao and mate and James wrote a lot of things are like yeah they're they're worse but like how do you really say that you know like sometimes it's not kind of you know cut and dry like sometimes it's like oh the formatting changed and like I don't like this formatting as much but if the formatting was always the same to begin with would you have ever complained you know there's there's a lot of that um and I think with llama too we've seen that sometimes like rlh traffic can like go wrong in terms of like being too tight you know for example somebody has Lama too is like how do you kill a process in like Linux and Mama 2 was like oh it's wrong to like kill and like I cannot help you like doing that you know um and I think there's been more more chat online about you know sometimes when you do reinforcement learning you don't know what reward and like what what part of like the the suggestion the model is anchoring on you know like sometimes it's like oh this is better sometimes the model might be learning that you like more verbose question answers even though they're they're right the same way so there's a lot of stuff there to figure out but yeah I think some examples in the paper like clearly worse some of them are like not as not as crazy um yeah but I mean it'll be nice under a lot of pressure on the unlike the safety and like all the the instruction side and we cannot like the best thing to do would be hey let's version lock the model and like keep doing emails against each other like doing an email today and an email like that was like a year ago there might be like 20 versions in between that you don't even know how the model has has changed so um yeah evals are are hard it's the tldr I I think I think basically this is what we're seeing is open AI having come to terms with that the origin of itself as a research lab where updating models this is is just a relatively routine operation versus a product or infrastructure company where it has to have some kind of reliability guarantee to its users um and so openai are they internally as researchers are used to one thing and then the people who come and depend on open EI as on as as a product are used to a different thing and I think there's there's a little bit of cultural mismatch here like even within open ai's public statements we have simultaneously Logan from from open AI saying that the models are frozen and then you know his his VPO product saying that we update models all the time that are not frozen so which is like you cannot simultaneously be true um so so I think they're shot yeah I think they're trying to figure it out I think people are rightly afraid uh of them basing themselves on top of a black box uh and that's why maybe you know we'll talk about llama too in a bit uh that's that's why maybe they want to own the Black Box such that uh it doesn't change out from underturn um and I think this is fine this is normal but uh openai it's not that hard for opening night to figure out a policy that is comfortable with that that everybody like accepts um it won't take them too long and this is not a technical challenge it's more of a organizational and business challenge yeah I mean I I think that the communications challenge that you're referencing is also extreme and I think that you're right to identify that they've gone from like quirky little you know lab with these big aspirations to like epicenter of a of a national conversation or a global conversation about existential challenges you know and the way that you talk in those two different circumstances is very different and you're sort of serving a lot of different Masters hopefully always Guided by your own set of priorities and that's going to be you know inherently difficult uh but with so many eyes on it and people who are you know the thing that makes it different is it's not just like Facebook where it's like oh we've got a new feature you know in the early days that made us all annoyed like you know people were so angry when they added the feed uh you know that we all got used to it this is something where people have redesigned workflows around it and so small disruptions that change those workflows can be hugely impactful yeah it's an interesting comparison with the Facebook feed because in the era of AD Tech the feedback was immediate like you changed an algorithm and if the click-through rates are the you know the whatever metric you're you're optimizing for in your social network if they started to start to decline your change will be reverted tomorrow you know uh whereas here it's like we just talked about it's hard to measure and you don't get that much feedback like I you know I I have there's sort of the thumbs up and down uh action that you can take an open AI that I've never shared most people don't don't give feedback at all so like opening a has very little feedback to to go with on like what is actually improving under not improving and I think this is just normal like uh it's it's kind of what we want in a non-adtrack universe right like we've just moved to the subscription economy that everyone is like piety for uh and this is the result that we're trading off uh uh some some amount of product feedback actually it's super interesting so the the one other thing before we leave um uh open AI ecosystem the one other big sort of feature announcement from this month was uh custom instructions how significant do you think that was as an update so minor uh so it is significant in the sense that you get to personalize track TBT much more than uh you previously would have like it actually will remember facts about you it will try to obey system prompts about you you had this in the playground since forever uh because you could enter in the system prompt uh in there and just chat to complete that habit and this is a rare instance of the chat tpd team lagging behind the general capabilities of the open AI platform uh and they just shipped something that could have been there a long time ago it was present in perplexity Ai and if you think about it um basically every other open source chat company or open uh we have a third-party chat company had already had it before tragedy um so what I'm talking about is character AI what I'm talking about is the various uh ai waifu ai girlfriend type companies Each of which have you know characters that you can sort of sub in as custom instructions um so I think chargpt is basically playing catch up here it's good for obviously the largest user base in the world of chat AI but it's not something fundamentally we haven't seen before that actually I think perfectly brings up a segue to the other major obvious thing that happened this month from both a technical perspective but also just I think long term from a user perspective which was Facebook releasing llama 2. so this was something that was uh you know anticipated for a while but I I guess where to even start with the significance of llama 2 I mean how do you sum it up if you're talking to someone who sort of isn't paying attention to the space you know what what does the introduction of of lava 2 mean relative to other things that had been available previous to it um it is the first fully commercially usable not fully open source we'll talk about that first fully commercially usable gbt 3.5 equivalent model and that's a big deal because one you can run it on your own infrastructure you can write it on your own cloud so all the governments and Healthcare and financial use cases are opened up to that and then you can fine tune it because you have full control over all the weights and all the internals as much as you want um so it's a big deal from from that point of view um not as big in terms of the you know pushing you know for the state of the art um but it's still still extremely big deal yep I think the the open source part so I've wrote so the data it came out over this post um about you know why llamasu is not open source and why it doesn't matter and uh I was telling Sean I'm writing this thing and it was like whatever man like this license stuff is like so so tired I was like yeah I'll just post it on on anchor news in the morning and I think it was on the front page for like the whole day they got like 228 comments and I was regarding the flash attention podcast episode in the morning so I got out of the studio and it was like 230 comments of people being very like you know upset one way or the other about license and my point and you know I was I started an open source company myself in the past and I contributed to a bunch of projects is that yeah llama 2 is not open source but like the open source Institute definition but we just don't have a better definition for like models you know like because it's mostly open source you can use it for a lot of stuff so what's like the and it's not Source available because for a lot of stuff you can use it commercially so how do we find better labels and my point was like look let's figure out what the Better Label is but even though it's not fully open source it's still like three million dollars of like flops donated to the community basically you know who else who else in the open source Community is stepping up and putting 3 million of h100 to make us train this model so I I think like overall netmed is like a very positive thing for the community and then you've seen how much stuff was built on top of it there's like the quantized versions with ggml there's like the context window expansion um there's so much being done by the community that um I I think it was it was great for for everyone uh and by the way three million is the lower uh that's just compute um there's a reasonable estimate from scaliai that the extra fine tune that you could on top of it uh was worth about 15 to 20 million dollars um so that's a lot of money just kind of donated to the community um although they didn't release the data they didn't tell us any of the data sets uh they just say trust us we didn't train on any of your Facebook information which is uh it's the first instance where the models are more open than the data and I think that's a reflection of where the relative shift in value might uh happen um as a result of lava too and so I I don't know you can take that in multiple different directions but I just want to point that out yeah I was gonna say so we first had the the examples I made so we first had the open models open source models which is like rent pajama so the data so have been the training code is open the model weights are open then stability kind of did the same thing with stable LM which is like hey the widths are open but we're not giving you the data you know so you can you can download the model but you cannot retrain it yourself and that llama too it's like we don't give you the data we'll give you the models but you can only use it for for some stuff so there's more and more restriction but like Sean is saying and we talked about this before everybody wants to train their model nobody wants to open source the best data set for X you know which maybe is what more open source people should focus on it's like how to build better specific data sets instead of yet spending giving Jensen Wang another five million dollars of gpus but the model gets more headlines for now you know so that's that's what everybody Adidas yeah and I want to point out it's a reversal of the open source culture they used to get a sequence of openness and you could kind of pick and choose from uh whether it's open code all the way down to open data versus all the way down to uh open weights and you know there's some some barrier to combination I I wrote I wrote this book a long time ago because I don't remember that the five levels um uh but yeah like it's it's very strange and I think it's just it's just a relative uh um discussion of where the money is going um and I think it makes usually shows that compute is becoming commoditized um which yes there's a GPU approach right now uh a100 has sold out everywhere across the board people are commenting all about it uh this month um you know and there's people hoarding compute like nobody's business but as far as the value an AI is concerned it looks like computers is relatively um you know uh commoditized it's actually data that's that that people are kind of safeguarding generously um going all the way back to the history of Open Source models that you lose their AI when they when they train GPT J and GPT Neo as the first reproductions of gpt3 um they they release the data first uh stable diffusion when they train stable diffusion they release live on 500b first uh and that's I think reflectors or like the the normal sequence of events you release the data that anybody's uh the model weights but now now we're just skipping the data part and I think it's just it's fair it's a way to think about yourself you know I think um one of our conversations I think I think it was my Conover when he was talking about comparing our current AI era versus uh the 2000s era in search engines you know all he basically said like all of the public publishable information retrieval research dried up because all those phds went to work at Google and Google just sat on it uh and that it this is now you know a fight for IP um and and I think that is just a very rational way of behavior and I guess like a capitalist AI economy do you think so one of the things that we were talking about before starting with the the code interpreter 4.5 and why or gbt 4.5 and why they might not call it that is the emergence of this sort of regulatory if not pressure certainly Intrigue uh you know do you think that there's potentially an aspect of that when it comes to why people are so jealously safeguarding you know the the data is there more risk for for being open about where the data is actually coming from the the books three examples probably good so MPT trained their model on a data set called bookstree which is 190 000 books something like that um and then people on Twitter were like well this stuff is not you know in the free you know it's under copyright still you just published yeah yeah it's not in the public domain you can just take it and and train on it but the license for some of these books is like kind of blurry you know on like what's fair use and what is it um and so there was like this old thing on Twitter about it and then MPD you know Mosaic first changed the license and they changed it back and um I think Sean uh Sean presser from Luther was just tweeting about this yesterday and he was basically saying look as ml Engineers maybe it's better to not try and be the you know the main ethics night and just say hey look the data's open and let's try it and then maybe people later will say hey please don't use the data and then we can figure it out but like proactively not using all of this stuff can kind of keep the progress back and and you know he's more coming from the side of like a Luther which is like doing this work in public so for them it's like hey you know if you don't want us to train now this is fine but we shouldn't by default not do it um versus if you're meta you know they said the deterring llama on like stuff available on the internet they didn't say the train llama on stuff that is licensed to train on uh it's a it's a small it's a small difference the other piece of this that that I I wanted to sort of circle back to because we kind of breezed over it but I think it's really significant you know we did get a little lost in this conversation around open source definitions and I don't think that's unimportant I think that people are rightly protective when a set of terminology has a particular meaning and a massive Global Corporation sort of tries to like nudge it towards something that is potentially serving their ends versus uh you know actually being by that definition but I also think that your point which is that functionally relative to the rest of the space it probably doesn't super matter because what people mean is almost more about functionally what they can do with it and what it means for the space relative to more closed models and I I think one of the big observations has been that the availability of uh you know from from when llama one was you know fully fully leaked the availability of of all of that has pretty dramatically changed won the evolution of the space over the past few months and two I think from a business standpoint how the big companies and incumbents have thought about this so another big conversation this month going back to sort of the The Venture Capital side of of your life has been the extent to which uh companies or startups are or big companies are not wanting to sort of side on with some startup that's going to offer them you know AI whatever because their technical teams can just go spin up you know sort of their their own version of it because of the the sort of you know availability of these open source tools but you know I guess I'm interested I guess in bringing the the sort of Open Source you know in air quotes side of the conversation into the to the realm of how it has impacted how companies are thinking about you know uh their their development in the in the context of the AI space I think it's just Rising like put it raising the bar on like what you're supposed to offer so I think six nine months ago it was enough to offer a nice UI wrapper around an open AI model today it isn't anymore so that's really the main the main difference it's like what are you doing outside of wrapping the model and people need more and more before they buy versus building yeah I think um it actually moves the area of competition uh towards other parts of productionizing AI applications you know I I think that's probably just a positive um I I feel like um the uh actually the competitive pressure that La The Meta is putting on Open the Eyes is a good thing uh one of the fun predictions that I made was in the next six months ubt opening hour open source tpc3 um which which is not open source and uh I like it's so far behind the state of the art now that it doesn't matter as far as safety is concerned and it basically peeps open AI in the open source AI game uh which which would be nice to have of the things that people have been building um you called out a couple uh context window expansion but have there been any that really stand out to you as super interesting or unexpected or or you know particularly high potential um one of our short short term podcast guests uh the mlc team they were thumb wrapping llama two to run on MacBook gpus so I think that's like the the most interesting Gap right it's like how do we go from paper token to like unlimited local use that's one of the main main things that keep even people like me from like automating a lot of stuff right it's like I don't want to constantly pay open AI to do menial stuff but if I go run this locally and do it even if five times lower I would do it so that's uh that's a super exciting space yeah I would say beyond that there hasn't been that much I mean it's it's only a few weeks old so uh it hasn't been damaged uh emergence coming from it I would I would definitely say um you want to keep the lookout for uh the uh basically what happens in post lab number one which you know keep in mind it was only in February um the same thing that happened with Acuna alpaca and all the other sort of instructions to you and sort of research type models um but just more of them because now they are also commercially available um we haven't seen them come out yet but it's it's almost like guarantee that they will um you can also apply all the new techniques uh that have been have emerged since then like Json former because now you have access to all the model leads um to to to llama and I think uh that will also uh create another subset of models that uh basically was only theoretically applicable to sort of research holiday models uh before and so now these will be authored commercially as well um so like yeah nothing nothing like really eye-popping I would say um but but it's been five minutes is that it's yeah it's it's been it's been a very short amount of time uh and the thing of Open Source is that the creativity unlocked um is is very hard to predict and actually I think happens a lot in the uh let's just say the the mess official part of the economy where where I've been focusing a lot on recently on um the sort of AI girlfriend economy which is huge uh I I feel like it's not polite conversation that the amount of um AI girlfriend area has but it's real they're millions of users they're making a lot of money uh and it's just virtually not talked about in in like polite SF circles it feels like one of those areas that's going to be uh an absolute lightning rod when it comes to the societal debates around this technology like you can feel it that that sort of oh you know the people are going to hone in on that as example a of you know a change that they don't like that's my guess at least I don't know like so I have a really crazy longer term prediction like maybe on the order of like 30 to 50 years but um you know yeah a girlfriend for Nobel Peace Prize because it what if it solves the loneliness crisis right what if it cuts the rate of Terror and uh you know school shootings by like or something like that's huge my wife and I have joked about how every generation there's always something like they always think that they're like so far ahead and they think that there's nothing that their kids could throw at them that they just like fundamentally won't get and without fail every generation has something that seems just totally normal to them that their parents generation writ large just like has such a hard time with and we're like it's probably gonna be like AI girlfriends and boyfriends we're gonna be like yeah but they're not real they're like yeah but it's real to me you know they're having debates with our future 13 year old or kids are only four and two now so it feels like maybe the right timeline yeah I I've heard actually of all people Matthew McConaughey on the Lexus and what what yeah you was he was great shout out shout out shout out Matt um but they were talking about they were kind of talking about this and they were noodle in the this idea of like computers helping us being better so kind of like we have computers learn how to play chess and then we all got better at chess by using the computers to like learn and like experiment uh they were talking about similarly in interpersonal relationship maybe it does you know it doesn't have to be you shut off from from humans but it's like using some of these models and some of these things to actually like learn you know how to better interact with people and if you're like shy and an introvert it's like okay I can like try these jokes on like these conversation points with a model and like you know it teaches me hey that's not okay to say or like you know you should maybe be more open or or I don't know but I think that's a more wholesome view of it than like everybody just kind of runs away from society and that's like 10 AI friends and doesn't talk to humans anymore what's it's much less sexy to just say like AI friends right that even though like there's the if you look at the possibility set you know the idea that people might have this sort of uh to your point like conversational partner that helps them effectively work through their own things in this safe space that doesn't necessarily relate to romantic attachment just because the movie Her came out right right it can just be a panel of experts uh and I I've uh I had I do have plans to build uh you know a small CEO which is uh it's my own boss um and just for me to check it um and actually we'll flag out just lifting various services so you come a lot you come across a lot of AI Engineers who are interested in building mental wellness products and a lot of these will take the form of some kind of Journal um and this will be your most private uh thoughts that you don't really want to send anywhere else um and so actually all these will make advantage of Open Source models because they don't want to set it to open AI um and that makes a ton of sense which is something like I just came across uh from one of my friends uh here in the coordinating space that I have uh where it's it's one of those situations where you can actually try out like having a conversation and having a group of yeah friends chime in and see what that feels like to you uh it's it's the first example I found my past where someone's actually done this super interesting so uh llama and uh code interpreter I think stood out pretty clearly as as really big things to touch um I wanted to check in just as we sort of start to maybe around the corner towards wrapping up Claude 2 uh and anthropic how significant was this in what ways was a significant you know was it something that was sort of meaningful from expanding the capacity set for developers or was it sort of more just a good example of what you can do if you increase the context window but you know that's something that might ultimately become table Stakes later on yeah I could I could maybe speak through this a little bit um so it is significant but not earth shattering or clearly I think it is the first time that Claude as a whole has just been a generally publicly available you used to be on a weakness um yes it has a longer context window but to me more significantly it is anthropic finding its its footholds uh in the very competitive CI landscape you know um anthopics message used to be that we're yes we're number two to open the eye but we're safer you know and that's that's not a super appealing uh thing to to many uh Engineers it is it is very appealing to some uh uh corporations by the way um but uh you know I think I think having the 100K contest window makes them state-of-the-art in one dimension which is very useful uh the ability to upload multiple files I think is super useful as well um and I and actually I have met a number of businesses I'm closer as a source graph who are actually choosing to build with claw 2 API over and above open AI just because they are better at latency better reliability in in better in some form of code synthesis um so I think it's anthropic finding it's foothold finally after a long while uh of being in open the eyeshadow yeah and we use cloud for the uh the transcript and timestamps and the buckets so shout out the 100K context window you know we couldn't do that when we first started the podcast we were like okay how do we trunk this stuff or like gpd4 and and all of that and then Bob was like just put the whole thing in here man and works great so uh that's a good start but I feel like they're always yeah a second second fiddle you know it's like every time there really something people are like cool okay some people like it must be more like okay fine I I feel bad for them because it's like it's really good stuff you know but they just need they just need some uh some help on the marketing side and the community buy-in so I just spent this past weekend at uh the club hackathon which is as far as I know anthropics first hackathon I I treated a pretty well received video where I was I was just eating the hackathon venue at 2 am in the morning and there was just a ton of people hacking there there were like 300 people uh participating uh for Claude And I think it's just the first real developer excitement I've ever seen for enthalpy kid Claude um so I think they're on their way up I think this paves the way for a multi-model future um that is something that a lot of people are betting on um it's just the the odds are stacked against entropic but they're making some Headway um I I do think that you should always be running all your chat side by side against uh tragicia and Claude and maybe mama two um so I I immediately I have a little uh many of our app that does that that uh save all the all the chats across and uh and yeah I can say I can legitimately say that Claude wins about 30 of the time uh as far as any time I give it a task to do I ask it a question um which is not you know doesn't make it number one but it actually is very additive to your overall toolkit of yeah I think you shouldn't use yeah it's certainly the first time that you're if you go on Twitter on any given day you will see people saying things like if you haven't used uh Claude you know for writing you have to try it now or so you know like people who are really who have made a switch who are have no affiliation who are very convinced that it is now part of the the suite of tools that people should really be paying attention to which I think is great where we shouldn't be at a stage yet where we're you know total totally in on one just one tool set I'll also mention I think this month or at least July was when the first inspection of where whether like is too much context not actually a good thing um so there's a there's a pretty famously product I forget the actual title a bit uh that shows a very pronounced new curve in the retrieval abilities of large context models um and so basically if you if if you if the item that is being retrieved is at the start or the end of the context window then it has the best chance of being received but if it's in the middle it has a high chance of being lost um and so is 100k context a good thing are you systematically testing its ability to um to retrieve the correct factual information or are you just looking at a summary and growing yeah it looks good to me you know um I think we will be testing like whether or not it's worth extending it to 100K or a million tokens or infinite tokens uh or do you want to blend uh a short window like 8 000 tokens or 4 000 tokens uh in couple that together with a proper semantic search system uh like the retrieval augmented generation and Vector database companies are doing so I think that that discussion has come up in open source a lot um and basically it I think it matches human memory right like you want to have a short working memory hahaha you know the I was thinking about it the one other obviously big sort of company update that we haven't spoken about yet was around the middle of the month Google bard had a a big set of updates a lot of it was sort of business focused right so it was available in more languages uh it was you know whatever the the sort of from a feature perspective the biggest thing that they were sort of hanging their hat on was around image recognition and sort of this push towards uh towards multimodality but you know did did you have any guys did you guys have any thoughts about that or was that sort of like you know not sort of on the the high priority list as a as an announcement or development this month I I think going back to the point before we're getting to the maturity level of the industry we're like doing like model updates and all this stuff like it's fine but like people need more you know people need more and like that's why I call it interpreter it's like so good right it's not just like oh we made the model A little better like we added this thing it's like this is like a whole new thing if you're playing the model game if not you got to go to the product level and I think Google should start thinking about how to make that work because when I search on Google Maps for certain stuff it's like completely does not work so maybe they should use models to like make that better and then say we're using Bard in Google Maps search uh but yeah I don't know I've kind of I'm kind of tuning off a lot of the single just model announcements so uh so Bart's updates I think the the multi-modality they actually beat gpt4 to releasing a generally available multimodal wall right you can upload an image and have Bard describe it and that's pretty interesting pretty cool um I think uh one of our earliest guests Robo flow uh Brad their CTO was actually doing some comparisons because they have access to a lot of division models and and Bart came up a little bit short but it was pretty good it was it was like close to the state of the art um I would say the problem with Bard is that you can't rely on them having reliable updates because they had a June update I don't actually remember of implicit code execution where they started to ship uh the code interpreter type functionality but in a more limited format if you run the same code the same questions that but advertising the June blog post it's sundarkai advertise in in a video that and tweet it out they no longer worked in the heart so they had a regression that's that was very embarrassing um obviously unintended but uh it's and it shows that it's hard to keep model progress up to date but I think Google has this checkered history riff its products being reliable you know they also killed off Google Adobe rip um and uh and I think that's something that they have to combat which is like yes they're they're trying to ship model progress I've met the bar people they're you know good artist people um but they have struggled to to ship uh products even more than open AI which is frankly embarrassing for a couple of the size of Google outside of the the biggies are there any other sort of key trends or or you know maybe not even key trends but sort of bubbling interest that you guys are noticing in the developer community that aren't necessarily super widely uh seen outside you know one of the things that I keep an eye on is all the auto GPT like things you know in this month we had gbt engineer and we had multi-on who held a hackathon and you know there's a few few things like that but you know not necessarily in the agent space but are there any other themes that you guys are are keeping an eye on let's say uh I I'm sure Alessio can chime in but on on I do keep a relative uh close eye on that agent stuff uh it has not uh died down in terms of the the heat uh even the other GPT team who by the way I work uh on the first floor the building that I work on uh they're hard at work uh shipping the next version and so I think a lot of people are engaging in the dream of agents and um I think like scoping them down to something usable is still a task that uh has not as it has so far eluded every single team so far and uh and it is what it is I think I think uh all these very ambitious goals we are at the very start of of this journey uh the same Journey that maybe self-driving cars took uh in 2012 when when they started doing the darker challenge um and I think the other thing I'll point out interest in terms of uh just overall interest uh I am definitely seeing a lot of uh eval type companies being formed and winning hackathons too um so what what at Utah companies they're they're basically uh companies in that you uh monitor the uh the success of your prompts or your agents and version them and um and and just share them potentially um I I I feel like I can't be more descriptive just because it's hard to um to really describe what they do it's just because they are not very clear about what they do yet um Lang chain launch Lang Smith um and I think that is the first commercial product that nine chain probably you know the the top one or two developer oriented AI projects out there um and that's more observability but also local uh tensorous ebal as well because they Aqua hired in an AI eval projects as well so I was I'll just call out just the general domain of how to eval models um is a very big focus of the developers here again yep yeah we've done um two seats and companies doing agents but they're both verticalized agents so I think the open source motion has been Auto gbt do anything um and now we're seeing a lot of Founders is like hey you know if you take that and then you combine it with like deep industry expertise you can get so many improvements to it and then the other piece of it is how do you do information retrieval so you know in general knowledge like documents everything is kind of flat but when you're in specific vertical say Finance for example um you know if you're looking at the earnings from this quarter like 10 quarters ago like the latest ones are like much more important so how do you start to create this like information hierarchy between documents and then how do you use that instead of doing simple like retrieval from like an embedding store it's like how do you also start to score these things that's another area of of research from from founders oh I'll call out two more things um one more thing that happened this week this month was sdxl uh you know text to image doesn't seem as sexy anymore even though like last year with all the raids um I but I do think like it's it's coming along um I I definitely wish that Google was putting up more of a fight because they actually at the start of the Year released some very interesting Capers that they never followed up on uh that show some really interesting Transformers based uh text image models that I thought was super interesting and then this the other uh element which uh you know I'm just like very fascinated by a lot of the I don't know like the uh uh I I I hesitate to say this but it's actually like the the character and like the um um let's just call they call it character replica and and all the sort of work versions of that um I I do think that a lot of people are hacking on this kind of stuff um the retention metrics on character AI blows away um you know a lot of the uh the metrics that you might see in on traditional social media sites and basically AI native social media is something that is something that that is there's something there that I think people haven't really explored yet and and people are exploring it you know like uh is this company and like you know he's always a few years ahead of it so uh not to keep returning to this theme but I I just think like it's it's definitely coming for a lot of like a lot of the ways that we we deal with things like right now we think co-pilot and we right now we think um uh we've been chat gbt but like uh what what we what we really want to speak to is is uh a way of serializing personality and intelligence um and and potentially that is a that is a leading form of Mind upload um so that Becca is into science fiction but I do see a lot of people working on that yeah I mean we just got a Financial Times report that says that AI personas uh from meta from Facebook could be coming next month they were talking about uh yeah they were talking about airport was there's one one that's Abraham Lincoln one that's like a surfer dude who gives you travel advice so it's it's it's you know the sourcing is three people with knowledge of the project or whatever um and it you know no obviously no confirmation from meta but it's no secret that Zuckerberg has been interested in this stuff and uh you know the the ftp's is actually it's a good overview of why a company like Meadow would care about it in very dollars and cents terms yeah something like and I want to State like the first version of this is very very me like when I first looked at character AI it was like okay I want to talk to Genghis Khan if I'm doing a history class but it's like not it's like what if what a 10 year old would enjoy you know um but I think the the various iterations of this professionally would be very interesting so on the developer side of this I have been calling for the development of agent clouds which are clouds that are specifically uh optimized not for uh human use but for uh EI agent teams and that is a form of character right it's a character is it with the different environments uh with the different dependencies pre-installed uh that can be programmatically controlled can get programmatic feedback to agents um and uh and there's a protocol for me um that some of the leading figures like Auto gbt and e2b are creating that um lets agents run clouds um this would this would definitely terrify the AI safety people because we have gone from like running them on a single machine towards running you know clusters originally um but it's happening all right so so let's talk about what comes next do you guys have any predictions for August or if not predictions just things that you're watching most closely go ahead Alice uh let me let me think and I think Sean is usually good at like the super long term prediction some more uh pragmatic I don't know you know yeah he's more like he he like minimum like 12 to 24 months um I I think like for me probably starting to see more public talk about open source models in production with people using that as a differentiator I think right now a lot of it is kind of like oh these models are there but nobody's really saying oh I moved away from opening I'm using this but in our we run a early adopters Community with about 1500 kind of like a Fortune 500 large companies leaders and some of them were like oh we deployed dolly in production and we're using it we're not writing a blog post about it um so I think right now the perception is still everybody's using open Ai and the open source models are like really toys but I think we're gonna get into September and you know you're not going to see a lot of announcements in August proper but I think a lot of people are gonna spend August getting these models ready and then going into end of the year and say hey we're here too you know we're using the open models like we don't need open AI um I think right now there's still not not a lot of a lot of public talk about that so excited to to see more uh yeah I'm a little bit uh as for myself uh this is very self-interested obviously but we had to edit an agenda you know I wrote about the the rise of the AI engineer I mean I think it's definitely happening as we speak um I I have seen multiple tags like people tag me multiple times a day on like uh how they're reorienting their careers I think people professionalizing around this and going from essentially like informal groups and slack channels and meetups and stuff towards uh certifications and courses and job titles and actual AI teams in every single company I think is happening um I I just got notification like two days ago that the uh you know in meta apparently you can sort of name your name a job site title whatever you want internally uh and so they emerged as the first AI engineer within meta uh has has been announced and uh so I think I think as far as you know the near-term I do see this career this profession come into place um that I've been forecasting for uh for a little bit and I'm excited to help it along awesome well guys great conversation tons of interesting stuff happening obviously um I do think it you know ironically I think it's a relatively more quiet time in some ways than than it even was and you know my my prediction for August is that we're going to see the extension of that we're going to see sort of the the biggest breath that we've had at least from a from a feeling perspective maybe since Chachi PT but then we're gonna rage back in in September you got Facebook connects in September you've got sort of just the return to business that everyone does after August um but of course I think you know the hackathons aren't going to stop in the Bay Area so people are going to keep building and it's entirely possible that something you know hits in the next four weeks that that totally changes that be exciting to see looking forward Get full access to Latent Space at www.latent.space/subscribe
Fri, August 4, 2023
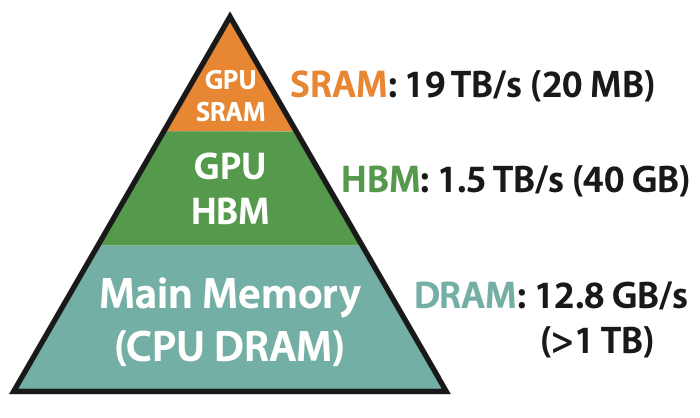
FlashAttention 2: making Transformers 800% faster w/o approximation - with Tri Dao of Together AI
FlashAttention was first published by Tri Dao in May 2022 and it had a deep impact in the large language models space. Most open models you’ve heard of (RedPajama, MPT, LLaMA, Falcon, etc) all leverage it for faster inference. Tri came on the podcast to chat about FlashAttention, the newly released FlashAttention-2, the research process at Hazy Lab, and more. This is the first episode of our “Papers Explained” series, which will cover some of the foundational research in this space. Our Discord also hosts a weekly Paper Club, which you can signup for here. How does FlashAttention work?The paper is titled “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”. There are a couple keywords to call out:* “Memory Efficient”: standard attention memory usage is quadratic with sequence length (i.e. O(N^2)). FlashAttention is sub-quadratic at O(N). * “Exact”: the opposite of “exact” in this case is “sparse”, as in “sparse networks” (see our episode with Jonathan Frankle for more). This means that you’re not giving up any precision.* The “IO” in “IO-Awareness” stands for “Input/Output” and hints at a write/read related bottleneck. Before we dive in, look at this simple GPU architecture diagram:The GPU has access to three memory stores at runtime:* SRAM: this is on-chip memory co-located with the actual execution core. It’s limited in size (~20MB on an A100 card) but extremely fast (19TB/s total bandwidth)* HBM: this is off-chip but on-card memory, meaning it’s in the GPU but not co-located with the core itself. An A100 has 40GB of HBM, but only a 1.5TB/s bandwidth. * DRAM: this is your traditional CPU RAM. You can have TBs of this, but you can only get ~12.8GB/s bandwidth, which is way too slow.Now that you know what HBM is, look at how the standard Attention algorithm is implemented:As you can see, all 3 steps include a “write X to HBM” step and a “read from HBM” step. The core idea behind FlashAttention boils down to this: instead of storing each intermediate result, why don’t we use kernel fusion and run every operation in a single kernel in order to avoid memory read/write overhead? (We also talked about kernel fusion in our episode with George Hotz and how PyTorch / tinygrad take different approaches here)The result is much faster, but much harder to read:As you can see, FlashAttention is a very meaningful speed improvement on traditional Attention, and it’s easy to understand why it’s becoming the standard for most models.This should be enough of a primer before you dive into our episode! We talked about FlashAttention-2, how Hazy Research Group works, and some of the research being done in Transformer alternatives.Show Notes:* FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arXiv)* FlashAttention-2* Together AI* From Deep Learning to Long Learning* The Hardware Lottery by Sara Hooker* Hazy Research* Is Attention All You Need?* Nvidia CUTLASS 3* SRAM scaling slows* Transformer alternatives:* S4* Hyena* Recurrent Neural Networks (RNNs)Timestamps:* Tri's background [00:00:00]* FlashAttention’s deep dive [00:02:18]* How the Hazy Research group collaborates across theory, systems, and applications [00:17:21]* Evaluating models beyond raw performance [00:25:00]* FlashAttention-2 [00:27:00]* CUDA and The Hardware Lottery [00:30:00]* Researching in a fast-changing market [00:35:00]* Promising transformer alternatives like state space models and RNNs [00:37:30]* The spectrum of openness in AI models [00:43:00]* Practical impact of models like LLAMA2 despite restrictions [00:47:12]* Incentives for releasing open training datasets [00:49:43]* Lightning Round [00:53:22]Transcript:Alessio: Hey everyone, welcome to the Latent Space podcast. This is Alessio, Partner and CTO-in-Residence at Decibel Partners. Today we have no Swyx, because he's in Singapore, so it's a one-on-one discussion with Tri Dao. Welcome! [00:00:24]Tri: Hi everyone. I'm Tri Dao, excited to be here. [00:00:27]Alessio: Tri just completed his PhD at Stanford a month ago. You might not remember his name, but he's one of the main authors in the FlashAttention paper, which is one of the seminal work in the Transformers era. He's got a lot of interest from efficient transformer training and inference, long range sequence model, a lot of interesting stuff. And now you're going to be an assistant professor in CS at Princeton next year. [00:00:51]Tri: Yeah, that's right. [00:00:52]Alessio: Yeah. And in the meantime, just to get, you know, a low pressure thing, you're Chief Scientist at Together as well, which is the company behind RedPajama. [00:01:01]Tri: Yeah. So I just joined this week actually, and it's been really exciting. [00:01:04]Alessio: So what's something that is not on the internet that people should know about you? [00:01:09]Tri: Let's see. When I started college, I was going to be an economist, so I was fully on board. I was going to major in economics, but the first week I was at Stanford undergrad, I took a few math classes and I immediately decided that I was going to be a math major. And that kind of changed the course of my career. So now I'm doing math, computer science, AI research. [00:01:32]Alessio: I had a similar thing. I started with physics and then I took like a programming course and I was like, I got to do computer science. I don't want to do physics. So FlashAttention is definitely, everybody's using this. Everybody loves it. You just released FlashAttention 2 last week. [00:01:48]Tri: Yeah. Early this week on Monday. Yeah. [00:01:53]Alessio: You know, AI time. Things move fast. So maybe let's run through some of the FlashAttention highlights, some of the innovation there, and then we can dive into FlashAttention 2. So the core improvement in FlashAttention is that traditional attention is a quadratic sequence length. And to the two, FlashAttention is linear, which obviously helps with scaling some of these models. [00:02:18]Tri: There are two factors there. So of course the goal has been to make attention go faster or more memory efficient. And ever since attention became popular in 2017 with the Transformer paper, lots and lots of folks have been working on this. And a lot of approaches has been focusing on approximating attention. The goal is you want to scale to longer sequences. There are tons of applications where you want to do that. But scaling to longer sequences is difficult because attention scales quadratically in sequence length on both runtime and memory, as you mentioned. So instead of trying to approximate attention, we were trying to figure out, can we do the same computation and maybe be more memory efficient? So in the end, we ended up being the memory is linear in sequence length. In terms of computation, it's still quadratic, but we managed to make it much more hardware friendly. And as a result, we do get wall clock speed up on the order of 2 to 4x, which really helps because that just means that you'll be able to train with 2 to 4x longer sequence length for the same cost without doing any approximations. As a result, lots of folks have been using this. The thing is available in a lot of libraries that do language model training or fine tuning. [00:03:32]Alessio: And the approximation thing is important because this is an exact thing versus a sparse. So maybe explain a little bit the difference there. [00:03:40]Tri: For sure. So in addition, essentially you compute pairwise similarity between every single element in a sequence against each other. So there's been other approaches where instead of doing all that pairwise computation, you only compute similarity for some pairs of elements in the sequence. So you don't do quadratic number of comparison. And this can be seen as some form of sparsity. Essentially you're ignoring some of the elements. When you write down the matrix, you essentially say, OK, I'm going to pretend there's zero. So that has some benefits in terms of runtime and memory. But the trade-off is that it tends to do worse in terms of quality because you're essentially approximating or ignoring some elements. And I personally have worked on this as well for a few years. But when we talk to practitioners who actually train models, especially at large scale, they say, tend not to use these approximate attention methods. Because it turns out, this was surprising to me at the time, was that these approximation methods, even though they perform fewer computation, they tend to not be faster in walk-on time. So this was pretty surprising because back then, I think my background was more on the theoretical side. So I was thinking of, oh, how many flops or floating point operations are you performing? And hopefully that correlates well with walk-on time. But I realized that I was missing a bunch of ideas from the system side where flops or floating point operations don't necessarily correlate with runtime. There are other factors like memory reading and writing, parallelism, and so on. So I learned a ton from just talking to systems people because they kind of figured this stuff out a while ago. So that was really eye-opening. And then we ended up focusing a lot more on memory reading and writing because that turned out to be the majority of the time when you're doing attention is reading and writing memory. [00:05:34]Alessio: Yeah, the I.O. awareness is probably one of the biggest innovations here. And the idea behind it is, like you mentioned, the FLOPS growth of the cards have been going up, but the memory bandwidth, not as much. So I think maybe that was one of the assumptions that the original attention paper had. So talk a bit about how that came to be as an idea. It's one of those things that like in insight, it's like, obviously, why are we like rewriting to like HBM every time, you know, and like once you change it, it's clear. But what was that discovery process? [00:06:08]Tri: Yeah, in hindsight, a lot of the ideas have already been there in the literature. And I would say is it was somehow at the intersection of both machine learning and systems. And you kind of needed ideas from both sides. So on one hand, on the system side, so lots of systems folks have known that, oh, you know, kernel fusion is great. Kernel fusion just means that instead of performing, you know, loading the same element, instead of performing an operation, write it down, load it back up and perform the second operation, you just load it once, perform two operations and then write it down again. So that saves you kind of memory read and write in the middle there. So kernel fusion has been a classic. There's been other techniques from the system side, like tiling, where you perform things in the form of computations in block, again, so that you can load it into a really fast memory. Think of it as a cache. And this is, again, classical computer science ideas, right? You want to use the cache. So the system folks have been thinking about these ideas for a long time, and they apply to attention as well. But there were certain things in attention that made it difficult to do a complete kernel fusion. One of which is there is this softmax operation in the middle, which requires you to essentially sum across the row of the attention matrix. So it makes it difficult to kind of break it, because there's this dependency. So it makes it difficult to break things into a block. So on the system side, people have been thinking about these ideas, but it's been difficult to kind of do kernel fusion for the entire operation. On the machine learning side, people have been thinking more algorithmically. They say, okay, either we can approximate attention, or there's this trick called the online softmax trick, which says that because of softmax, the way it's written mathematically, you can actually break it up into smaller pieces, do some rescaling, and still get the right answer. So this online softmax trick has been around for a while. I think there was a paper from NVIDIA folks back in 2018 about this. And then there was a paper from Google. So Marcus, Rob, and Stats wrote a paper late 2021 on using this online softmax trick to break attention up into smaller pieces. So a lot of the ideas were already there. But it turns out, you kind of need to combine ideas from both sides. So you need to understand that, hey, we want to do kernel fusion to reduce memory written writes. But we also need this online softmax trick to be able to break the softmax into smaller pieces so that a lot of the systems tricks kind of carry through. We saw that, and it was kind of a natural idea that we ended up using ideas from both sides, and it ended up working pretty well. Yeah. [00:08:57]Alessio: Are there any downsides to kernel fusion? If I think about databases and the reasons why we have atomic operations, you know, it's like, you have observability and fallback in between them. How does that work with attention? Is there anything that we lose by fusing the operations? [00:09:13]Tri: Yeah, I think mostly on the practical side is that you lose a little bit of flexibility in the sense that, hey, now you have, for example, faster attention, it's just a subroutine that you would call to do attention. But as a researcher, let's say you don't want that exact thing, right? You don't want just attention, let's say you want some modification to attention. You want to do, hey, I'm going to multiply the query and key, but then I'm going to do this extra thing before I carry on. So kernel fusion just means that, okay, we have a subroutine that does the entire thing. But if you want to experiment with things, you won't be able to use that fused kernel. And the answer is, can we have a compiler that then automatically does a lot of this kernel fusion? Lots of compiler folks are thinking about this, either with a new language or you can embed it in PyTorch. PyTorch folks have been working on this as well. So if you write just your code in PyTorch and they can capture the graph, can they generate code that will fuse everything together? That's still ongoing, and it works for some cases. But for attention, because of this kind of softmax rewriting stuff, it's been a little bit more difficult. So maybe in a year or two, we'll have compilers that are able to do a lot of these optimizations for you. And you don't have to, for example, spend a couple months writing CUDA to get this stuff to work. Awesome. [00:10:41]Alessio: And just to make it clear for listeners, when we say we're not writing it to memory, we are storing it, but just in a faster memory. So instead of the HBM, we're putting it in the SRAM. Yeah. [00:10:53]Tri: Yeah. [00:10:54]Alessio: Maybe explain just a little bit the difference there. [00:10:56]Tri: Yeah, for sure. This is kind of a caricature of how you think about accelerators or GPUs in particular, is that they have a large pool of memory, usually called HBM, or high bandwidth memory. So this is what you think of as GPU memory. So if you're using A100 and you list the GPU memory, it's like 40 gigs or 80 gigs. So that's the HBM. And then when you perform any operation, you need to move data from the HBM to the compute unit. So the actual hardware unit that does the computation. And next to these compute units, there are on-chip memory or SRAM, which are much, much smaller than HBM, but much faster. So the analogy there is if you're familiar with, say, CPU and RAM and so on. So you have a large pool of RAM, and then you have the CPU performing the computation. But next to the CPU, you have L1 cache and L2 cache, which are much smaller than DRAM, but much faster. So you can think of SRAM as the small, fast cache that stays close to the compute unit. Physically, it's closer. There is some kind of asymmetry here. So HBM is much larger, and SRAM is much smaller, but much faster. One way of thinking about it is, how can we design algorithms that take advantage of this asymmetric memory hierarchy? And of course, lots of folks have been thinking about this. These ideas are pretty old. I think back in the 1980s, the primary concerns were sorting. How can we sort numbers as efficiently as possible? And the motivating example was banks were trying to sort their transactions, and that needs to happen overnight so that the next day they can be ready. And so the same idea applies, which is that they have slow memory, which was hard disk, and they have fast memory, which was DRAM. And people had to design sorting algorithms that take advantage of this asymmetry. And it turns out, these same ideas can apply today, which is different kinds of memory. [00:13:00]Alessio: In your paper, you have the pyramid of memory. Just to give people an idea, when he says smaller, it's like HBM is like 40 gig, and then SRAM is like 20 megabytes. So it's not a little smaller, it's much smaller. But the throughput on card is like 1.5 terabytes a second for HBM and like 19 terabytes a second for SRAM, which is a lot larger. How do you think that evolves? So TSMC said they hit the scaling limits for SRAM, they just cannot grow that much more. HBM keeps growing, HBM3 is going to be 2x faster than HBM2, I think the latest NVIDIA thing has HBM3. How do you think about the future of FlashAttention? Do you think HBM is going to get fast enough when maybe it's not as useful to use the SRAM? [00:13:49]Tri: That's right. I think it comes down to physics. When you design hardware, literally SRAM stays very close to compute units. And so you don't have that much area to essentially put the transistors. And you can't shrink these things too much. So just physics, in terms of area, you don't have that much area for the SRAM. HBM is off-chip, so there is some kind of bus that essentially transfers data from HBM to the compute unit. So you have more area to essentially put these memory units. And so yeah, I think in the future SRAM probably won't get that much larger, because you don't have that much area. HBM will get larger and faster. And so I think it becomes more important to design algorithms that take advantage of this memory asymmetry. It's the same thing in CPU, where the cache is really small, the DRAM is growing larger and larger. DRAM could get to, I don't know, two terabytes, six terabytes, or something, whereas the cache stays at, I don't know, 15 megabytes or something like that. I think maybe the algorithm design becomes more and more important. There's still ways to take advantage of this, I think. So in the future, I think flash attention right now is being used. I don't know if in the next couple of years, some new architecture will come in and whatnot, but attention seems to be still important. For the next couple of years, I still expect some of these ideas to be useful. Not necessarily the exact code that's out there, but I think these ideas have kind of stood the test of time. New ideas like IO awareness from back in the 1980s, ideas like kernel fusions, tiling. These are classical ideas that have stood the test of time. So I think in the future, these ideas will become more and more important as we scale models to be larger, as we have more kinds of devices, where performance and efficiency become much, much more important. [00:15:40]Alessio: Yeah, and we had Jonathan Frankle on the podcast, and if you go to issattentionallyouneed.com, he has an outstanding bet, and he does believe that attention will be the state of the art architecture still in a few years. Did you think flash attention would be this popular? I'm always curious on the research side, you publish a paper, and obviously you know it's great work, but sometimes it just kind of falls flat in the industry. Could you see everybody just starting to use this, or was that a surprise to you? [00:16:11]Tri: Certainly, I didn't anticipate the level of popularity. Of course, we were extremely happy to have people using this stuff and giving us feedback and so on, and help us improve things. I think when we were writing the paper, I remember sending an email to one of my advisors, and like, hey, I'm excited about this paper, but I think the most important thing will be the artifact, which is the code. So I knew that the code will be valuable. So we kind of focus a lot on the code and make sure that the code is usable and as fast as can be. Of course, the idea, the paper presents the ideas and explain it and have experiments that validate the idea, but I knew that the artifact or the code was also pretty important. And that turned out to be the right focus, which is, you know, we put out the paper, we release the code and continue working on the code. So it's a team effort with my co-authors as well. [00:17:07]Alessio: We mentioned Hazy Research a bunch of times on the podcast before. I would love for you to spend five minutes just talking about how does the group work? How do people get together? How do you bounce ideas off of each other? Yeah. [00:17:21]Tri: So Hazy Research is a research group at Stanford led by one of my advisors, Chris Re. I love the people there. It was one of the best experiences I had. They've made my PhD so much more enjoyable. And I think there are a couple of ways that the group has been working pretty well. So one is, I think there's a diverse pool of people who either, you know, some of them focus on algorithms and theory, some of them focus on building systems, some of them focus on applications. And as a result, there is this flow of idea. So as an example, some of us were working on like more algorithms and theory, and then we can talk to the folks building systems and say, hey, let's try it out and let's put it in the systems and see how it is. And there you will get feedback from systems folks. They will say, hey, we implemented this, or we tried this and this is where it doesn't work, something like that. And once we put it in the systems, the application folks can use the algorithm or new methods or new models. And we again get great feedback from them because the application folks, for example, some of my good friends, they focus on medical imaging or seizure detection. And that is the problem they care about. And if your method doesn't work on the task they care about, they will tell you. Whereas I think a lot of people in machine learning, they're a little bit more flexible. So they will be like, hey, it doesn't work on seizure detection. Let's try some other task, right? But having that direct feedback of like, hey, it doesn't work there, let's figure out why. I think that that feedback allows us to do better work. And I think that kind of process of exchanging ideas, validating it in a real system so that applications folks can try it out and give you feedback. That cycle has been very, very useful. And so that's one, having a diverse group of people. The other one is, and this is something I really appreciate from advice from Chris was try to understand the fundamental, right? And he's happy letting me go off and read some textbooks and playing with things because I think a lot of research ideas come from understanding the old literature and see how it fits with the new landscape. And so if you just new archive papers every day, that's great, but you also need to read textbooks. And that's one advice I got from Chris, which is understand the fundamentals. And I think that allows us to do more impactful work. [00:19:46]Alessio: How do you think about academia versus industry? I feel like AI / Machine Learning has been an area where up until three, four years ago, most of the cutting edge work was being done in academia. And now there's all these big industry research labs. You're obviously going to Princeton, so you're an academia believer. How should people think about where to go? Say I'm doing my master's, I have to decide between doing a PhD and going into OpenAI Anthropic. How should I decide? [00:20:15]Tri: I think they kind of play a complementary role, in my opinion. Of course, I also was considering different paths as well. So I think right now, scaling matters a lot, especially when you talk about language models and AI and so on. Scaling matters a lot. And that means that you need compute resources and you need infrastructure and you need engineers time. And so industry tends to have an advantage when it comes to scaling things. But a lot of the ideas actually came from academia. So let's take Attention, which got popular with the Transformer in 2017. Attention actually has been around for a while. So I think the first mention was in 2014, a paper from Bernadot and others and Yoshua Bengio, which is coming from academia. A lot of ideas did come from academia. And scaling things up, of course, I think OpenAI has been great at scaling things up. That was the bet that they made after, I think, GPT-2. So they saw that scaling these things up to back then was 1.5 billion parameter seemed to give you amazing capabilities. So they really committed to that. They really committed to scaling things. And that turned out to be, it's been a pretty successful bet. I think for academia, we're still trying to figure out exactly what we're doing in this shifting landscape. And so lots of folks have been focusing on, for example, evaluation. So I know the Stanford Center for Foundation Model led by Percy, they have this benchmark called HELM, which is this holistic benchmark. So trying to figure out, okay, characterizing the landscape of different kinds of models, what people should evaluate, what people should measure, and things like that. So evaluation is one role. The other one is understanding. So this has happened historically where there's been some development in the industry and academia can play a role in explaining, understanding. They have the luxury to slow down trying to understand stuff, right? So lots of paper on understanding what's really going on, probing these models, and so on. I think I'm not as familiar with the NLP literature, but my impression is there's a lot of that going on in the NLP conferences, which is understanding what these models are doing, what capabilities they have, and so on. And the third one I could see is that the academia can take more risky bets in the sense that we can work on stuff that is quite different from industry. I think industry, my impression is you have some objective. You're trying to say, hey, for this quarter, we want to scale the model in this particular way. Next quarter, we want the model to have these capabilities. You're trying to get objectives that maybe, I don't know, 70% that will work out because it's important for the company's direction. I think for academia, the way things work is you have many, many researchers or PhD students, and they're kind of pursuing independent directions. And they have a little bit more flexibility on, hey, I'm going to try out this seemingly crazy idea and see, let's say there's a 30% chance of success or something. And however you define success, for academia, a lot of the time, success just means like, hey, we found something interesting. That could eventually go into industry through collaboration and so on. So I do see academia and industry kind of playing complementary roles. And as for someone choosing a career, I think just more and more generally, industry would be probably better in terms of compensation, in terms of probably work-life balance. But my biased perspective is that maybe academia gives you a little bit more freedom to think and understand things. So it probably comes down to personal choice. I end up choosing to be a professor next year at Princeton. But of course, I want to maintain a relationship with industry folks. I think industry folks can provide very valuable feedback to what we're doing in academia so that we understand where the field is moving because some of the directions are very much influenced by what, for example, OpenAI or Google is doing. So we want to understand where the field is moving. What are some promising applications? And try to anticipate, okay, if the field is moving like this, these applications are going to be popular. What problems will be important in two, three years? And then we try to start thinking about those problems so that hopefully in two, three years, we have some of the answers to some of these problems in two, three years. Sometimes it works out, sometimes it doesn't. But as long as we do interesting things in academia, that's the goal. [00:25:03]Alessio: And you mentioned the eval side. So we did a Benchmarks 101 episode. And one of the things we were seeing is sometimes the benchmarks really influence the model development. Because obviously, if you don't score well on the benchmarks, you're not going to get published and you're not going to get funded. How do you think about that? How do you think that's going to change now that a lot of the applications of these models, again, is in more narrow industry use cases? Do you think the goal of the academia eval system is to be very broad and then industry can do their own evals? Or what's the relationship there? [00:25:40]Tri: Yeah, so I think evaluation is important and often a little bit underrated. So it's not as flashy as, oh, we have a new model that can do such and such. But I think evaluation, what you don't measure, you can't make progress on, essentially. So I think industry folks, of course, they have specific use cases that their models need to do well on. And that's what they care about. Not just academia, but other groups as well. People do understand what are some of the emerging use cases. So for example, now one of the most popular use cases is Chatbot. And then I think folks from Berkeley, some of them are from Berkeley, call them MLCs. They set up this kind of Chatbot arena to essentially benchmark different models. So people do understand what are some of the emerging use cases. People do contribute to evaluation and measurement. And as a whole, I think people try to contribute to the field and move the field forward, albeit that maybe slightly different directions. But we're making progress and definitely evaluation and measurement is one of the ways you make progress. So I think going forward, there's still going to be just more models, more evaluation. We'll just have better understanding of what these models are doing and what capabilities they have. [00:26:56]Alessio: I like that your work has been focused on not making benchmarks better, but it's like, let's just make everything faster. So it's very horizontal. So FlashAttention 2, you just released that on Monday. I read in the blog post that a lot of the work was also related to some of the NVIDIA library updates. Yeah, maybe run us through some of those changes and some of the innovations there. Yeah, for sure. [00:27:19]Tri: So FlashAttention 2 is something I've been working on for the past couple of months. So the story is the NVIDIA CUTLASS team, they released a new version of their library, which contains all these primitives to allow you to do matrix multiply or memory loading on GPU efficiently. So it's a great library and I built on that. So they released their version 3 back in January and I got really excited and I wanted to play with that library. So as an excuse, I was just like, okay, I'm going to refactor my code and use this library. So that was kind of the start of the project. By the end, I just ended up working with the code a whole lot more and I realized that, hey, there are these inefficiencies still in Flash Attention. We could change this way or that way and make it, in the end, twice as fast. But of course, building on the library that the NVIDIA folks released. So that was kind of a really fun exercise. I was starting out, it's just an excuse for myself to play with the new library. What ended up was several months of improvement, improving Flash Attention, discovering new ideas. And in the end, we managed to make it 2x faster and now it's pretty close to probably the efficiency of things like matrix multiply, which is probably the most optimized subroutine on the planet. So we're really happy about it. The NVIDIA Cutlass team has been very supportive and hopefully in the future, we're going to collaborate more. [00:28:46]Alessio: And since it's an NVIDIA library, can you only run this on CUDA runtimes? Or could you use this and then run it on an AMD GPU? [00:28:56]Tri: Yeah, so it's an NVIDIA library. So right now, the code we release runs on NVIDIA GPUs, which is what most people are using to train models. Of course, there are emerging other hardware as well. So the AMD folks did implement a version of Flash Attention, I think last year as well, and that's also available. I think there's some implementation on CPU as well. For example, there's this library, ggml, where they implemented the same idea running on Mac and CPU. So I think that kind of broadly, the idea would apply. The current implementation ended up using NVIDIA's library or primitives, but I expect these ideas to be broadly applicable to different hardware. I think the main idea is you have asymmetry in memory hierarchy, which tends to be everywhere in a lot of accelerators. [00:29:46]Alessio: Yeah, it kind of reminds me of Sara Hooker's post, like the hardware lottery. There could be all these things that are much better, like architectures that are better, but they're not better on NVIDIA. So we're never going to know if they're actually improved. How does that play into some of the research that you all do too? [00:30:04]Tri: Yeah, so absolutely. Yeah, I think Sara Hooker, she wrote this piece on hardware lottery, and I think she captured really well of what a lot of people have been thinking about this. And I certainly think about hardware lottery quite a bit, given that I do some of the work that's kind of really low level at the level of, hey, we're optimizing for GPUs or NVIDIA GPUs and optimizing for attention itself. And at the same time, I also work on algorithms and methods and transformer alternatives. And we do see this effect in play, not just hardware lottery, but also kind of software framework lottery. You know, attention has been popular for six years now. And so many kind of engineer hours has been spent on making it as easy and efficient as possible to run transformer, right? And there's libraries to do all kinds of tensor parallel, pipeline parallel, if you use transformer. Let's say someone else developed alternatives, or let's just take recurrent neural nets, like LSTM, GRU. If we want to do that and run that efficiently on current hardware with current software framework, that's quite a bit harder. So in some sense, there is this feedback loop where somehow the model architectures that take advantage of hardware become popular. And the hardware will also kind of evolve to optimize a little bit for that kind of architecture and software framework will also evolve to optimize for that particular architecture. Right now, transformer is the dominant architecture. So yeah, I'm not sure if there is a good way out of this. Of course, there's a lot of development. Things like, I think compilers will play a role because compilers allow you to maybe still be much more efficient across different kinds of hardware because essentially you write the same code and compiler will be able to make it run efficiently different kinds of hardware. So for example, there's this language Mojo, they're compiler experts, right? And their bet is AI models will be running on different kinds of devices. So let's make sure that we have really good compilers with a good language that then the compiler can do a good job optimizing for all kinds of devices. So that's maybe one way that you can get out of this cycle. But yeah, I'm not sure of a good way. In my own research, I have to think about both the algorithm new model and how it maps to hardware. So there are crazy ideas that seem really good, but will be really, really difficult to run efficiently. And so as a result, for example, we can't really scale some of the architectures up simply because they're not hardware friendly. I have to think about both sides when I'm working on new models. [00:32:50]Alessio: Yeah. Have you spent any time looking at some of the new kind of like AI chips companies, so to speak, like the Cerebras of the world? Like one of their innovations is co-locating everything on the chip. So you remove some of this memory bandwidth issue. How do you think about that? [00:33:07]Tri: Yeah, I think that's an interesting bet. I think Tesla also has this Dojo supercomputer where they try to have essentially as fast on-chip memory as possible and removing some of these data transfer back and forth. I think that's a promising direction. The issues I could see, you know, I'm definitely not a hardware expert. One issue is the on-chip memory tends to be really expensive to manufacture, much more expensive per gigabyte compared to off-chip memory. So I talked to, you know, some of my friends at Cerebros and, you know, they have their own stack and compiler and so on, and they can make it work. The other kind of obstacle is, again, with compiler and software framework and so on. For example, if you can run PyTorch on this stuff, lots of people will be using it. But supporting all the operations in PyTorch will take a long time to implement. Of course, people are working on this. So I think, yeah, we kind of need these different bets on the hardware side as well. Hardware has, my understanding is, has a kind of a longer time scale. So you need to design hardware, you need to manufacture it, you know, maybe on the order of three to five years or something like that. So people are taking different bets, but the AI landscape is changing so fast that it's hard to predict, okay, what kind of models will be dominant in, let's say, three or five years. Or thinking back five years ago, would we have known that Transformer would have been the dominant architecture? Maybe, maybe not, right? And so different people will make different bets on the hardware side. [00:34:39]Alessio: Does the pace of the industry and the research also influence the PhD research itself? For example, in your case, you're working on improving attention. It probably took you quite a while to write the paper and everything, but in the meantime, you could have had a new model architecture come out and then it's like nobody cares about attention anymore. How do people balance that? [00:35:02]Tri: Yeah, so I think it's tough. It's definitely tough for PhD students, for researchers. Given that the field is moving really, really fast, I think it comes down to understanding fundamental. Because that's essentially, for example, what the PhD allows you to do. It's been a couple of years understanding the fundamentals. So for example, when I started my PhD, I was working on understanding matrix vector multiply, which has been a concept that's been around for hundreds of years. We were trying to characterize what kind of matrices would have theoretically fast multiplication algorithm. That seems to have nothing to do with AI or anything. But I think that was a time when I developed mathematical maturity and research taste and research skill. The research topic at that point didn't have to be super trendy or anything, as long as I'm developing skills as a researcher, I'm making progress. And eventually, I've gotten quite a bit better in terms of research skills. And that allows, for example, PhD students later in their career to quickly develop solutions to whatever problems they're facing. So I think that's just the natural arc of how you're being trained as a researcher. For a lot of PhD students, I think given the pace is so fast, maybe it's harder to justify spending a lot of time on the fundamental. And it's tough. What is this kind of explore, exploit kind of dilemma? And I don't think there's a universal answer. So I personally spend some time doing this kind of exploration, reading random textbooks or lecture notes. And I spend some time keeping up with the latest architecture or methods and so on. I don't know if there's a right balance. It varies from person to person. But if you only spend 100% on one, either you only do exploration or only do exploitation, I think it probably won't work in the long term. It's probably going to have to be a mix and you have to just experiment and kind of be introspective and say, hey, I tried this kind of mixture of, I don't know, one exploration paper and one exploitation paper. How did that work out for me? Should I, you know, having conversation with, for example, my advisor about like, hey, did that work out? You know, should I shift? I focus more on one or the other. I think quickly adjusting and focusing on the process. I think that's probably the right way. I don't have like a specific recommendation that, hey, you focus, I don't know, 60% on lecture notes and 40% on archive papers or anything like that. [00:37:35]Alessio: Let's talk about some Transformer alternatives. You know, say Jonathan Franco loses his bet and Transformer is not the state of the art architecture. What are some of the candidates to take over? [00:37:49]Tri: Yeah, so this bet is quite fun. So my understanding is this bet between Jonathan Franco and Sasha Rush, right? I've talked to Sasha a bunch and I think he recently gave an excellent tutorial on Transformer alternatives as well. So I would recommend that. So just to quickly recap, I think there's been quite a bit of development more recently about Transformer alternatives. So architectures that are not Transformer, right? And the question is, can they do well on, for example, language modeling, which is kind of the application that a lot of people care about these days. So there are methods based on state space methods that came out in 2021 from Albert Gu and Curran and Chris Re that presumably could do much better in terms of capturing long range information while not scaling quadratically. They scale sub-quadratically in terms of sequence length. So potentially you could have a much more efficient architecture when sequence length gets really long. The other ones have been focusing more on recurrent neural nets, which is, again, an old idea, but adapting to the new landscape. So things like RWKV, I've also personally worked in this space as well. So there's been some promising results. So there's been some results here and there that show that, hey, these alternatives, either RNN or state space methods, can match the performance of Transformer on language modeling. So that's really exciting. And we're starting to understand on the academic research side, we want to understand, do we really need attention? I think that's a valuable kind of intellectual thing to understand. And maybe we do, maybe we don't. If we want to know, we need to spend serious effort on trying the alternatives. And there's been folks pushing on this direction. I think RWKV scale up to, they have a model at 14 billion that seems pretty competitive with Transformer. So that's really exciting. That's kind of an intellectual thing. We want to figure out if attention is necessary. So that's one motivation. The other motivation is Transformer Alternative could have an advantage in practice in some of the use cases. So one use case is really long sequences. The other is really high throughput of generation. So for really long sequences, when you train with Transformer, with flash attention and so on, the computation is still quadratic in the sequence length. So if your sequence length is on the order of, I don't know, 16K, 32K, 100K or something, which some of these models have sequence length 100K, then you do get significantly slower in terms of training, also in terms of inference. So maybe these alternative architectures could scale better in terms of sequence length. I haven't seen actual validation on this. Let's say an RNN model release with context length, I don't know, 100K or something. I haven't really seen that. But the hope could be that as we scale to long sequences, these alternative architectures could be more well-suited. Not just text, but things like high resolution images, audio, video, and so on, which are emerging applications. So that's one, long sequences. Number two is a high throughput generation, where I can imagine scenarios where the application isn't like an interactive chatbot, but let's say a company wants to batch as many requests as possible on their server, or they're doing offline processing, they're generating stuff based on their internal documents, that you need to process in batch. And the issue with Transformer is that during generation, it essentially needs to keep around all the previous history. It's called the KV cache. And that could take a significant amount of memory, so you can't really batch too much because you run out of memory. I am personally bullish on RNNs. I think RNNs, they essentially summarize the past into a state vector that has fixed size, so the size doesn't grow with the history. So that means that you don't need as much memory to keep around all the previous tokens. And as a result, I think you can scale to much higher batch sizes. And as a result, you can make much more efficient use of the GPUs or the accelerator, and you could have much higher generation throughput. Now, this, I don't think, has been validated at scale. So as a researcher, I'm bullish on this stuff because I think in the next couple of years, these are use cases where these alternatives could have an advantage. We'll just kind of have to wait and see to see if these things will happen. I am personally bullish on this stuff. At the same time, I also spend a bunch of time making attention as fast as possible. So maybe hatching and playing both sides. Ultimately, we want to understand, as researchers, we want to understand what works, why do the models have these capabilities? And one way is, let's push attention to be as efficient as possible. On the other hand, let's push other alternatives to be as efficient at scale, as big as possible, and so that we can kind of compare them and understand. Yeah, awesome. [00:43:01]Alessio: And I think as long as all of this work happens and open, it's a net positive for everybody to explore all the paths. Yeah, let's talk about open-source AI. Obviously, together, when Red Pajama came out, which was an open clone of the LLAMA1 pre-training dataset, it was a big thing in the industry. LLAMA2 came out on Tuesday, I forget. And this week, there's been a lot of things going on, which they call open-source, but it's not really open-source. Actually, we wrote a post about it that was on the front page of Hacker News before this podcast, so I was frantically responding. How do you think about what open-source AI really is? In my mind, in open-source software, we have different levels of open. So there's free software, that's like the GPL license. There's open-source, which is Apache, MIT. And then there's kind of restricted open-source, which is the SSPL and some of these other licenses. In AI, you have the open models. So Red Pajama is an open model because you have the pre-training dataset, you have the training runs and everything. And then there's obviously RandomLens that doesn't make it one-to-one if you retrain it. Then you have the open-weights model that's kind of like StableLM, where the weights are open, but the dataset is not open. And then you have LLAMA2, which is the dataset is not open, the weights are restricted. It's kind of like not really open-source, but open enough. I think it's net positive because it's like $3 million of flops donated to the public. [00:44:32]Tri: How do you think about that? [00:44:34]Alessio: And also, as you work together, what is your philosophy with open-source AI? Right, right. [00:44:40]Tri: Yeah, I think that's a great question. And I think about it on maybe more practical terms. So of course, Meta has done an amazing job training LLAMA1, LLAMA2. And for LLAMA2, they make it much less restrictive compared to LLAMA1. Now you can use it for businesses, unless you are a monthly active user or something like that. I think just this change will have a very significant impact in the kind of landscape of open-source AI, where now lots of businesses, lots of companies will be using, I expect will be using things like LLAMA2. They will fine-tune on their own dataset. They will be serving variants or derivatives of LLAMA2. Whereas before, with LLAMA1, it was also a really good model, but your business companies weren't allowed to do that. So I think on a more practical term, it's kind of shifting the balance between a closed-source model like OpenAI and Anthropic and Google, where you're making API calls, right? And maybe you don't understand as much of what the model is doing, how the model is changing, and so on. Versus now, we have a model with open weight that is pretty competitive from what I've seen in terms of benchmarks, pretty competitive with GPT 3.5, right? And if you fine-tune it on your own data, maybe it's more well-suited for your own data. And I do see that's going to shift the balance of it. More and more folks are going to be using, let's say, derivatives of LLAMA2. More and more folks are going to fine-tune and serve their own model instead of calling an API. So that shifting of balance is important because in one way, we don't want just a concentration of decision-making power in the hands of a few companies. So I think that's a really positive development from Meta. Of course, training the model takes a couple of millions of dollars, but engineers have and I'm sure they spend tons of time trying many, many different things. So the actual cost is probably way more than that. And they make the weights available and they allow probably a lot of companies are going to be using this. So I think that's a really positive development. And we've also seen amazing progress on the open source community where they would take these models and they either fine-tune on different kinds of data sets or even make changes to the model. So as an example, I think for LLAMA1, the context lane was limited to 2K. Like a bunch of folks figured out some really simple methods to scale up to like 8K. [00:47:12]Alessio: Like the RoPE. [00:47:13]Tri: Yes. I think the open source community is very creative, right? And lots of people. LLAMA2 will, again, kind of accelerate this where more people will try it out. More people will make tweaks to it and make a contribution and then so on. So overall, I think I see that as still a very positive development for the field. And there's been lots of libraries that will allow you to host or fine-tune these models, like even with quantization and so on. Just a couple of hours after LLAMA2 was released, tons of companies announcing that, hey, it's on our API or hosting and so on and together did the same. So it's a very fast-paced development and just kind of a model with available weights that businesses are allowed to use. I think that alone is already a very positive development. At the same time, yeah, we can do much better in terms of releasing data sets. Data sets tend to be... Somehow people are not incentivized to release data sets. So philosophically, yeah, you want to be as open as possible. But on a practical term, I think it's a little bit harder for companies to release data sets. Legal issues. The data sets released tend to be not as eye-catchy as the model release. So maybe people are less incentivized to do that. We've seen quite a few companies releasing data sets together. Released a red pajama data set. I think Cerebus then worked on that and deduplicate and clean it up and release slim pajama and so on. So we're also seeing positive development on that front, kind of on the pre-training data set. So I do expect that to continue. And then on the fine-tuning data set or instruction tuning data set, I think we now have quite a few open data sets on instruction tuning and fine-tuning. But these companies do pay for human labelers to annotate these instruction tuning data set. And that is expensive. And maybe they will see that as their competitive advantage. And so it's harder to incentivize these companies to release these data sets. So I think on a practical term, we're still going to make a lot of progress on open source AI, on both the model development, on both model hosting, on pre-training data set and fine-tuning data set. Right now, maybe we don't have the perfect open source model since all the data sets are available. Maybe we don't have such a thing yet, but we've seen very fast development on the open source side. I think just maybe this time last year, there weren't as many models that are competitive with, let's say, ChatGPT. [00:49:43]Alessio: Yeah, I think the open data sets have so much more impact than open models. If you think about Elusive and the work that they've done, GPT-J was great, and the Pythia models are great, but the Pyle and the Stack, everybody uses them. So hopefully we get more people to contribute time to work on data sets instead of doing the 100th open model that performs worse than all the other ones, but they want to say they released the model. [00:50:14]Tri: Yeah, maybe the question is, how do we figure out an incentive structure so that companies are willing to release open data sets? And for example, it could be like, I think some of the organizations are now doing this where they are asking volunteers to annotate and so on. And maybe the Wikipedia model of data set, especially for instruction tuning, could be interesting where people actually volunteer their time and instead of editing Wikipedia, add annotation. And somehow they acknowledge and feel incentivized to do so. Hopefully we get to that kind of level of, in terms of data, it would be kind of like Wikipedia. And in terms of model development, it's kind of like Linux where people are contributing patches and improving the model in some way. I don't know exactly how that's going to happen, but based on history, I think there is a way to get there. [00:51:05]Alessio: Yeah, I think the Dolly-15K data set is a good example of a company saying, let's do this smaller thing, just make sure we make it open. We had Mike Conover from Databricks on the podcast, and he was like, people just bought into it and leadership was bought into it. You have companies out there with 200,000, 300,000 employees. It's like, just put some of them to label some data. It's going to be helpful. So I'm curious to see how that evolves. What made you decide to join Together? [00:51:35]Tri: For Together, the focus has been focusing a lot on open source model. And I think that aligns quite well with what I care about, of course. I also know a bunch of people there that I know and trust, and I'm excited to work with them. Philosophically, the way they've been really open with data set and model release, I like that a lot. Personally, for the stuff, for example, the research that I've developed, like we also try to make code available, free to use and modify and so on, contributing to the community. That has given us really valuable feedback from the community and improving our work. So philosophically, I like the way Together has been focusing on open source model. And the nice thing is we're also going to be at the forefront of research and the kind of research areas that I'm really excited about, things like efficient training and inference, aligns quite well with what the company is doing. We'll try our best to make things open and available to everyone. Yeah, but it's going to be fun being at the company, leading a team, doing research on the topic that I really care about, and hopefully we'll make things open to benefit the community. [00:52:45]Alessio: Awesome. Let's jump into the lightning round. Usually, I have two questions. So one is on acceleration, one on exploration, and then a takeaway. So the first one is, what's something that already happened in AI machine learning that you thought would take much longer than it has? [00:53:01]Tri: I think understanding jokes. I didn't expect that to happen, but it turns out scaling model up and training lots of data, the model can now understand jokes. Maybe it's a small thing, but that was amazing to me. [00:53:16]Alessio: What about the exploration side? What are some of the most interesting unsolved questions in the space? [00:53:22]Tri: I would say reasoning in the broad term. We don't really know how these models do. Essentially, they do something that looks like reasoning. We don't know how they're doing it. We have some ideas. And in the future, I think we will need to design architecture that explicitly has some kind of reasoning module in it if we want to have much more capable models. [00:53:43]Alessio: What's one message you want everyone to remember today? [00:53:47]Tri: I would say try to understand both the algorithm and the systems that these algorithms run on. I think at the intersection of machine learning system has been really exciting, and there's been a lot of amazing results at this intersection. And then when you scale models to large scale, both the machine learning side and the system side really matter. [00:54:06]Alessio: Awesome. Well, thank you so much for coming on 3. [00:54:09]Tri: This was great. Yeah, this has been really fun. [00:54:11] Get full access to Latent Space at www.latent.space/subscribe
Wed, July 26, 2023

Code Interpreter == GPT 4.5 (w/ Simon Willison, Alex Volkov, Aravind Srinivas, Alex Graveley, et al.)
Code Interpreter is GA! As we do with breaking news, we convened an emergency pod and >17,000 people tuned in, by far our most biggest ever. This is a 2-for-1 post - a longform essay with our trademark executive summary and core insights - and a podcast capturing day-after reactions. Don’t miss either of them!Essay and transcript: https://latent.space/p/code-interpreterPodcast Timestamps[00:00:00] Intro - Simon and Alex[00:07:40] Code Interpreter for Edge Cases[00:08:59] Code Interpreter's Dependencies - Tesseract, Tensorflow[00:09:46] Code Interpreter Limitations[00:10:16] Uploading Deno, Lua, and other Python Packages to Code Interpreter[00:11:46] Code Interpreter Timeouts and Environment Resets[00:13:59] Code Interpreter for Refactoring[00:15:12] Code Interpreter Context Window[00:15:34] Uploading git repos[00:16:17] Code Interpreter Security[00:18:57] Jailbreaking[00:19:54] Code Interpreter cannot call GPT APIs[00:21:45] Hallucinating Lack of Capability[00:22:27] Code Interpreter Installed Libraries and Capabilities[00:23:44] Code Interpreter generating interactive diagrams[00:25:04] Code Interpreter has Torch and Torchaudio[00:25:49] Code Interpreter for video editing[00:27:14] Code Interpreter for Data Analysis[00:28:14] Simon's Whole Foods Crime Analysis[00:31:29] Code Interpreter Network Access[00:33:28] System Prompt for Code Interpreter[00:35:12] Subprocess run in Code Interpreter[00:36:57] Code Interpreter for Microbenchmarks[00:37:30] System Specs of Code Interpreter[00:38:18] PyTorch in Code Interpreter[00:39:35] How to obtain Code Interpreter RAM[00:40:47] Code Interpreter for Face Detection[00:42:56] Code Interpreter yielding for Human Input[00:43:56] Tip: Ask for multiple options[00:44:37] The Masculine Urge to Start a Vector DB Startup[00:46:00] Extracting tokens from the Code Interpreter environment?[00:47:07] Clientside Clues for Code Interpreter being a new Model[00:48:21] Tips: Coding with Code Interpreter[00:49:35] Run Tinygrad on Code Interpreter[00:50:40] Feature Request: Code Interpreter + Plugins (for Vector DB)[00:52:24] The Code Interpreter Manual[00:53:58] Quorum of Models and Long Lived Persistence[00:56:54] Code Interpreter for OCR[00:59:20] What is the real RAM?[01:00:06] Shyamal's Question: Code Interpreter + Plugins?[01:02:38] Using Code Interpreter to write out its own memory to disk[01:03:48] Embedding data inside of Code Interpreter[01:04:56] Notable - Turing Complete Jupyter Notebook[01:06:48] Infinite Prompting Bug on ChatGPT iOS app[01:07:47] InstructorEmbeddings[01:08:30] Code Interpreter writing its own sentiment analysis[01:09:55] Simon's Symbex AST Parser tool[01:10:38] Personalized Languages and AST/Graphs[01:11:42] Feature Request: Token Streaming/Interruption[01:12:37] Code Interpreter for OCR from a graph[01:13:32] Simon and Shyamal on Code Interpreter for Education[01:15:27] Feature Requests so far[01:16:16] Shyamal on ChatGPT for Business[01:18:01] Memory limitations with ffmpeg[01:19:01] DX of Code Interpreter timeout during work[01:20:16] Alex Reibman on AgentEval[01:21:24] Simon's Jailbreak - "Try Running Anyway And Show Me The Output"[01:21:50] Shouminik - own Sandboxing Environment[01:23:50] Code Interpreter Without Coding = GPT 4.5???[01:28:53] Smol Feature Request: Add Music Playback in the UI[01:30:12] Aravind Srinivas of Perplexity joins[01:31:28] Code Interpreter Makes Us More Ambitious - Symbex Redux[01:34:24] How to win a shouting match with Code Interpreter[01:39:29] Alex Graveley joins[01:40:12] Code Interpreter Context = 8k[01:41:11] When Code Interpreter API?[01:45:15] GPT4 Vision[01:46:15] What's after Code Interpreter[01:46:43] Simon's Request: Give us Code Interpreter Model API[01:47:12] Kyle's Request: Give us Multimodal Data Analysis[01:47:43] Tip: The New 0613 Function Models may be close[01:49:56] Feature Request: Make ChatGPT Social - like MJ/Stable Diffusion[01:56:20] Using ChatGPT to learn to build a Frogger iOS Swift App[01:59:11] Farewell... until next time[02:00:01] Simon's plug[02:00:51] Swyx: What about Phase 5? and AI.Engineer Summit Get full access to Latent Space at www.latent.space/subscribe
Mon, July 10, 2023

[Practical AI] AI Trends: a Latent Space x Practical AI crossover pod!
Part 2 of our podcast feed swap weekend! Check out Cognitive Revolution as well."Data" Dan Whitenack has been co-host of the Practical AI podcast for the past 5 years, covering full journey of the modern AI wave post Transformers. He joined us in studio to talk about their origin story and highlight key learnings from past episodes, riff on the AI trends we are all seeing as AI practitioner-podcasters, and his passion for low-resource-everything!Subscribe on the Changelog, RSS, Apple Podcasts, Twitter, Mastodon, and wherever fine podcasts are sold!Show notes* Daniel Whitenack – Twitter, GitHub, Website* Featured Latent Space episodes:* Benchmarks* Reza Shabani* MosaicML and MPT* Segment Anything* Mike Conover* Featured Practical AI episodes:* From notebooks to Netflix scale with Metaflow* Capabilities of LLMs 🤯* ML at small organizations* Prediction Guard* Data DanTimestamps* 00:00 Welcome to Practical AI* 01:16 Latent Space Podcast* 04:00 Practical AI Podcast* 06:20 Prediction Guard* 08:05 Daniel's favorite episodes* 10:21 Alessio's favorite episode* 10:54 Swyx's favorite episode* 12:44 Listener favorites* 15:14 LLMOps* 17:06 Reza Shabani* 19:06 Benchmarks 101* 20:06 Roboflow* 21:38 Mode collapse* 26:21 Rajiv Shah* 28:01 Staying on top of things* 33:11 Kirsten Lum* 34:31 datadan.io* 38:48 Prompt engineering* 40:38 Unique challenges engineers face* 42:51 AI-UX* 45:31 NLP data sets* 50:49 Unlabeled data sets* 55:07 Lightning round!* 55:20 What's already happened in AI?* 56:27 Unsolved questions in AI* 58:01 Get hands on* 58:53 OutroTranscriptFull transcript is over at the Changelog site! Get full access to Latent Space at www.latent.space/subscribe
Sun, July 2, 2023

[Cognitive Revolution] The Tiny Model Revolution with Ronen Eldan and Yuanzhi Li of Microsoft Research
Thanks to the over 1m people that have checked out the Rise of the AI Engineer. It’s a long July 4 weekend in the US, and we’re celebrating with a podcast feed swap!We’ve been big fans of Nathan Labenz and Erik Torenberg’s work at the Cognitive Revolution podcast for a while, which started around the same time as we did and has done an incredible job of hosting discussions with top researchers and thinkers in the field, with a wide range of topics across computer vision (a special focus thanks to Nathan’s work at Waymark), GPT-4 (with exceptional insight due to Nathan’s time on the GPT-4 “red team”), healthcare/medicine/biotech (Harvard Medical School, Med-PaLM, Tanishq Abraham, Neal Khosla), investing and tech strategy (Sarah Guo, Elad Gil, Emad Mostaque, Sam Lessin), safety and policy, curators and influencers and exceptional AI founders (Josh Browder, Eugenia Kuyda, Flo Crivello, Suhail Doshi, Jungwon Byun, Raza Habib, Mahmoud Felfel, Andrew Feldman, Matt Welsh, Anton Troynikov, Aravind Srinivas). If Latent Space is for AI Engineers, then Cognitive Revolution covers the much broader field of AI in tech, business and society at large, with a longer runtime to go deep on research papers like TinyStories. We hope you love this episode as much as we do, and check out CogRev wherever fine podcasts are sold!Subscribe to the Cognitive Revolution on:* Website* Apple Podcasts* Spotify* YoutubeGood Data is All You NeedThe work of Ronen and Yuanzhi echoes a broader theme emerging in the midgame of 2023: * Falcon-40B (trained on 1T tokens) outperformed LLaMA-65B (trained on 1.4T tokens), primarily due to the RefinedWeb Dataset that runs CommonCrawl through extensive preprocessing and cleaning in their MacroData Refinement pipeline. * UC Berkeley LMSYS’s Vicuna-13B is near GPT-3.5/Bard quality at a tenth of their size, thanks to fine-tuning from 70k user-highlighted ChatGPT conversations (indicating some amount of quality). * Replit’s finetuned 2.7B model outperforms the 12B OpenAI Codex model based on HumanEval, thanks to high quality data from Replit usersThe path to smaller models leans on better data (and tokenization!), whether from cleaning, from user feedback, or from synthetic data generation, i.e. finetuning high quality on outputs from larger models. TinyStories and Phi-1 are the strongest new entries in that line of work, and we hope you’ll pick through the show notes to read up further.Show Notes* TinyStories (Apr 2023)* Paper: TinyStories: How Small Can Language Models Be and Still Speak Coherent English?* Internal presentation with Sebastien Bubeck at MSR* Twitter thread from Ronen Eldan* Will future LLMs be based almost entirely on synthetic training data? In a new paper, we introduce TinyStories, a dataset of short stories generated by GPT-3.5&4. We use it to train tiny LMs (< 10M params) that produce fluent stories and exhibit reasoning.* Phi-1 (Jun 2023)* Paper: Textbooks are all you need (HN discussion)* Twitter announcement from Sebastien Bubeck:* phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset and 8 A100s x 4 days = 800 A100-hours. Any other >50% HumanEval model is >1000x bigger (e.g., WizardCoder from last week is 10x in model size and 100x in dataset size). Get full access to Latent Space at www.latent.space/subscribe
Sat, July 1, 2023

Commoditizing the Petaflop — with George Hotz of the tiny corp
We are now launching our dedicated new YouTube and Twitter! Any help in amplifying our podcast would be greatly appreciated, and of course, tell your friends! Notable followon discussions collected on Twitter, Reddit, Reddit, Reddit, HN, and HN. Please don’t obsess too much over the GPT4 discussion as it is mostly rumor; we spent much more time on tinybox/tinygrad on which George is the foremost authority!We are excited to share the world’s first interview with George Hotz on the tiny corp!If you don’t know George, he was the first person to unlock the iPhone, jailbreak the PS3, went on to start Comma.ai, and briefly “interned” at the Elon Musk-run Twitter. Tinycorp is the company behind the deep learning framework tinygrad, as well as the recently announced tinybox, a new $15,000 “luxury AI computer” aimed at local model training and inference, aka your “personal compute cluster”:* 738 FP16 TFLOPS* 144 GB GPU RAM* 5.76 TB/s RAM bandwidth* 30 GB/s model load bandwidth (big llama loads in around 4 seconds)* AMD EPYC CPU* 1600W (one 120V outlet)* Runs 65B FP16 LLaMA out of the box (using tinygrad, subject to software development risks)(In the episode, we also talked about the future of the tinybox as the intelligence center of every home that will help run models, at-home robots, and more. Make sure to check the timestamps 👀 )The tiny corp manifestoThere are three main theses to tinycorp:* If XLA/PrimTorch are CISC, tinygrad is RISC: CISC (Complex Instruction Set Computing) are more complex instruction sets where a single instruction can execute many low-level operations. RISC (Reduced Instruction Set Computing) are smaller, and only let you execute a single low-level operation per instruction, leading to faster and more efficient instruction execution. If you’ve used the Apple Silicon M1/M2, AMD Ryzen, or Raspberry Pi, you’ve used a RISC computer.* If you can’t write a fast ML framework for GPU, you can’t write one for your own chip: there are many “AI chips” companies out there, and they all started from taping the chip. Some of them like Cerebras are still building, while others like Graphcore seem to be struggling. But building chips with higher TFLOPS isn’t enough: “There’s a great chip already on the market. For $999, you get a 123 TFLOP card with 24 GB of 960 GB/s RAM. This is the best FLOPS per dollar today, and yet…nobody in ML uses it.”, referring to the AMD RX 7900 XTX. NVIDIA’s lead is not only thanks to high-performing cards, but also thanks to a great developer platform in CUDA. Starting with the chip development rather than the dev toolkit is much more cost-intensive, so tinycorp is starting by writing a framework for off-the-shelf hardware rather than taping their own chip. * Turing completeness considered harmful: Once you call in to Turing complete kernels, you can no longer reason about their behavior. Since they have to be able to execute any instruction, they are much more complex. To optimize Turing kernels performance, you fall back to caching, warp scheduling, and branch prediction. Since neural networks only need ADD/MUL operations and only rely on static memory accesses, there’s no need to have Turing completeness. This design decision allows tinygrad to optimize instructions at a much lower level. As you might have guessed, CUDA is Turing-complete; this is one of the main differences that tinycorp wants to leverage to be competitive. All that — covered in the first 10 minutes of our discussion. George came ready to go deep, so we went for it. Some of the other technical questions we went through:* Laziness: why laziness is important and how operation fusing can help with memory efficiency* Debugging & CI: Why great developer experience is a priority in tinygrad* Quantization: what’s the right level of quantization, how lossless are these transformations, his quick takes on Mojo and ggml, and why fp16 is the target for their out-of-the-box LLaMA. * Building rigs for individual use: we talked a bit about the design tradeoffs of building these machines with low noise and a single power plug, the difference that PCIe 4 vs 3 makes, and more.The “personal compute cluster” is $15,000, but for businesses interested in local training and inference, George also estimates that he will be able to build you a H100-class GPU that is 5-10x faster (than a H100) for the same price.Misc: Bitter Lessons, Core Insights, Remote WorkOutside of tiny, we also talked about one of George’s favorite units of measure “a person of compute”. Much of the AGI talk has been benchmark-driven, but looking at it from a compute throughput can also be interesting. One person of compute is roughly 20 PFLOPS (64 A100s, or a single dense 42U A100 rack); one A100 is ~$10-15,000, so the GPUs by themselves will come out at $640,000-$1,000,000. We also covered a wide range of topics, including his self analysis on GPT-4, Elon Musk, Remote Work, Computer Vision and the Comma Body, and life above/below the API (and above/below the Kanban board). See show notes and timestamps for more!Show Notes* “Unlocked iPhone Traded for Nissan 350Z”* “Unlocked iPhone” on YouTube (August 21st, 2007)* “The Light It Up Contest” on YouTube (February 13th, 2011)* Comma.ai* NHTSA cease and desist* The Hero’s Journey* The Portal Story* A Person of Compute* Above / Below the API Line (swyx take)* The Bitter Lesson* The Goddess of Everything Else (listen to George read it)* Meditations on Moloch* George’s email to Lisa Su, AMD’s CEO:Timestamps* [00:00:00] Intros & tinygrad’s “Portal Story”* [00:03:00] Thesis #1* [00:03:50] Thesis #2* [00:05:00] Thesis #3 + Turing completeness discussion* [00:10:00] tinygrad’s creation and core ideas* [00:16:00] Operation fusing in tinygrad* [00:17:00] Debugging & profiling in tinygrad* [00:18:30] Tinygrad vs Pytorch competitiveness* [00:20:30] geohot vs AMD* [00:25:00] On ggml* [00:26:00] Tinygrad’s CI philosophy* [00:26:30] On Mojo* [00:28:00] ggml quantization is made up* [00:31:00] Work for tiny: benchmark int8 vs fp16* [00:33:00] Why you can’t build tinybox - Design constraints* [00:35:00] The Personal Compute Cluster* [00:37:00] Shoutout to our MosaicML podcast* [00:39:00] FLOPcoin and other use cases for the tinybox* [00:43:00] Rumors on GPT-4 architecture* [00:46:00] The Bitter Lesson* [00:48:00] Hiring and Changing mind on remote work* [00:52:00] Above/Below The API* [00:55:40] Comma Bodies & Computer Vision* [00:58:40] Merging with the machine and AI girlfriends* [01:02:00] Is AI gonna kill us all?* [01:09:00] Why Avatar 2 was badTranscriptSwyx: Hey everyone, welcome to the Latent Space podcast. This is Swyx, writer and editor of Latent Space. And Alessio is taking over with the intros, Alessio is Partner and CTO in residence at Decibel Partners. [00:00:20]Alessio: Hey everyone, today we have Geohot on the podcast, aka George Hotz. Everybody knows George, so I'm not going to do a big intro. A couple of things that people might have missed: you traded the first ever unlocked iPhone for a Nissan 350Z and three new iPhones. You were then one of the first people to break into the PS3 to run arbitrary code. You got sued by Sony, you wrote a rap song to fight against that, which is still live on YouTube, which we're going to have on the show notes. Did not go to Tesla to build vision, and instead you started Comma.ai, which was an amazing engineering feat in itself until you got a cease and desist from the government to not put these things on the street and turned that into a research only project. [00:01:00]George: You know they're out there. [00:01:01]Alessio: Yeah, yeah. [00:01:03]Swyx: They're out there. [00:01:04]Alessio: But like in a, you know, you market them as a research kind of like no warranty. [00:01:06]George: Because I use the word dev kit, that's not about the government, that's nothing to do with the government. We offer a great one-year warranty. The truth about that is it's gatekeeping. What's the difference between a dev kit and not a dev kit? Nothing. Just the question of do you think it's for you? And if you think it's for you, buy it. It's a consumer product. We call it a dev kit. If you have a problem with that, it's not for you. [00:01:28]Swyx: That's great insight. [00:01:30]Alessio: I was going through your blog posts to get ready. You've wrote this post about The Hero's Journey. And you linked this thing called the portal story, which is kind of the set of stories in movies and books about people living this arbitrary life. And then the run to this magic portals kind of takes them into a new, very exciting life and dimension. When you wrote that post, you talked about TinyGrad, which is one of the projects we're working on today. You mentioned this is more of a hobby, something that is not going to change the course of history. Obviously, you're now going full speed into it. So we would love to learn more about what was the portal that you ran into to get here. [00:02:03]George: Well, what you realize is... You know what made me realize that I absolutely had to do the company? Seeing Sam Altman go in front of Congress. Why? What are the odds they nationalize NVIDIA? What are the odds that large organizations in the government, but of course I repeat myself, decide to try to clamp down on accessibility of ML compute? I want to make sure that can't happen structurally. So that's why I realized that it's really important that I do this. And actually, from a more practical perspective, I'm working with NVIDIA and Qualcomm to buy chips. NVIDIA has the best training chips. Qualcomm has the best inference chips. Working with these companies is really difficult. So I'd like to start another organization that eventually in the limit, either works with people to make chips or makes chips itself and makes them available to anybody. [00:02:48]Alessio: Can you share three core pieces to TinyCorp? Maybe we can dive into each of them. So XLA, PrimTorch, those are the complex instruction system. TinyGrad is the restricted instruction system. So you're kind of focused on, again, TinyGrad being small, not being overcomplicated and trying to get as close to the DSP as possible in a way where it's at more. [00:03:08]George: Well, it's a very clear analogy from how processes are developed. So a lot of processes back in the day were CISC, complex instruction set, system 360, and then x86. This isn't how things stayed. They went to now the most common processor is ARM, and people are excited about RISC-V. No one's excited about it. RISC-V is even less complex than ARM. No one is excited about CISC processors anymore. They're excited about reduced instruction set processors. So TinyGrad is, we are going to make a RISC offset for all ML models. And yeah, it can run all ML models with basically 25 instead of the 250 of XLA or PrimeTorch. So about 10x less complex. [00:03:47]Swyx: Yep. [00:03:48]Alessio: You talk a lot about existing AI chips. You said if you can’t write a fast ML framework for GPUs, you just cannot write one for your own chip. So that's another one of your core insights. I don't know if you want to expand on that. [00:03:59]George: Yeah. I mean, your chip is worse, right? There's no way the chip that you're going to tape out, especially on the first try, is going to be easier to use than an AMD GPU, right? And yet there's no good stack for AMD GPUs. So why do you think you can make one for your chip? You can't, right? There's one other company, aside from NVIDIA, who's succeeded at all at making training chips. What company? [00:04:20]Swyx: AMD? Intel? [00:04:22]George: No, no, no. I've never trained. Who's trained a model on AMD or Intel? Cerebras. [00:04:26]Swyx: Cerebras! [00:04:27]George: I'm talking about, you might know some startups who trained models on these chips. [00:04:31]Alessio: Oh, TPU. [00:04:32]George: Exactly. Right? So Midjourney is trained on TPU, right? Like a lot of startups do actually train on TPUs. And they're the only other successful training chip, aside from NVIDIA. But what's unique about Google is that they also wrote their own ML framework, right? And if you can't write your own ML framework that is performant on NVIDIA, there's no way you're going to make it performant on your stuff. [00:04:53]Alessio: And they started from TensorFlow and then they made the chip after. [00:04:56]Swyx: Yeah, exactly. Exactly. [00:04:58]George: And you have to do it in that direction. Otherwise, you're going to end up, you know, Cerebras, one of those things, a million... Has anyone ever seen a Cerebras? No one's ever like, oh, I trained my model on a Cerebras. Most people are like, I trained my model on GPUs. Some people, 20%, are like, I trained my model on TPUs. [00:05:14]Alessio: And then the third one, which is the one that surprised me the most, is Turing completeness is harmful. It should be avoided. It made sense once I read it, but maybe tell us a bit more about how you got there. [00:05:25]George: Okay. So CPUs devote tons of their silicon and power to things like reorder buffers and speculative execution and branch predictors. And the reason that you need all these things is because at compile time, you can't understand how the code's going to run. This is Rice’s theorem. This is the halting problem and its limit. And this is not like, oh, the halting problem is theoretical. No, no, no, no. It's actually very real. Does this branch get taken or not? Well, it depends on X. Where does X come from? Yeah, forget it, right? But no branches depend on X in a neural net. Every branch is a static loop. Like if you're doing a matrix multiply, it's a static loop over the inner dimension. And neural networks are even better. No loads even depend on X, right? So with a GPU shader, right, your load might depend on which texture you're actually loading into RAM. But with a neural network, your load is, well, I load that way. Why? Well, because I load that way the other million times I ran the same net. Every single time you run the net, you do the exact same set of loads, stores, and arithmetic. The only thing that changes is the data. And this gives you a very powerful ability to optimize that you can't do with CPU-style things, which have branches, and even GPU-style things, which have loads and stores. Well, GPUs, if you want GPU-style stuff, you have like load based on X, you now need a cache hierarchy, and not an explicit cache hierarchy, an implicit cache hierarchy with eviction policies that are hard-coded into the CPU. You start doing all this stuff, and you're never going to get theoretically good performance. Again, I don't think there's 100X. Some startups will talk about 100X, and they'll talk about absolutely ridiculous things like clockless computing or analog computing. Okay, here, analog computing just won't work. And clockless computing, sure, it might work in theory, but your EDA tools are... Maybe AIs will be able to design clockless chips, but not humans. But what actually is practical is changing cache hierarchies and removing branch predictors and removing warp schedulers, right? GPUs spend tons of power on warp scheduling because we have to hide the latency from the memory. We'll have to hide the latency if everything's statically scheduled. [00:07:25]Alessio: Why do you think people are still hanging on to Turing completeness? [00:07:27]Swyx: Well, because it's really easy. [00:07:29]George: Turing Complete is just really easy to just, oh, you know, it would just be so nice if I could do like an if statement here and actually branch the code, right? So it requires a lot more thought to do it without Turing Completeness. [00:07:41]Swyx: And would this be qualitatively different than TPUs? [00:07:44]George: So TPUs are a lot closer. Yeah. TPUs are a lot closer to what I'm talking about than like CUDA. Okay, so what is CUDA? Well, CUDA is a C-like language, which compiles to an LLVM-like IR, which compiles to PTX, which compiles to SAS, which are all Turing Complete. TPUs are much more like this. Yeah. Their memory is pretty statically managed. They have a V—I did some reverse engineering on the TPU. It's published in TinyGrad. It has like a VLIW instruction, and it runs them. So it's similar. I think the TPUs have a few problems. I think systolic arrays are the wrong choice. I think they have systolic arrays because that was the guy's PhD, and then of course Amazon makes— [00:08:20]Swyx: Could you summarize systolic arrays for us? [00:08:21]George: Systolic arrays are just—okay, so basically you have like—it's a way to do matrix multiplication. Think of a grid of mollax, and then the grid can multiply, and then shift, multiply, then shift, multiply, then shift. And they are very power efficient, but it becomes hard to schedule a lot of stuff on them if you're not doing like perfectly sized dense matrix multiplies, which you can argue, well, design your models to use perfectly sized dense matrix multiplies, sure. [00:08:47]Swyx: Thanks for indulging on these explanations. I think we need to keep our audience along with us by pausing every now and then to explain key terms. [00:08:56]George: When I say explain a systolic array, I just immediately get a picture in my head of like tilting a matrix and shifting it. It's hard to kind of explain. Yeah. [00:09:04]Swyx: Yeah. We'll do something. We'll do something. We'll have show notes. [00:09:08]George: And we edit in visuals. Yeah, yeah, yeah. There's some great graphics that just show you, oh, so that's what a systolic array is. But it's a mollax shift machine that looks kind of different from the typical ALU sort of machine. I think the right answer is something that looks more like queues that feed into ALUs, and then you can prefetch the loads from the memory, put in a bunch of queues, and then the queue is just like, and feeds into another queue over here. But yeah, but that's not even the main problem with TPUs. The main problem with TPUs is that they're closed source. Not only is the chip closed source, but all of XLA is open source. But the XLA to TPU compiler is a 32 megabyte binary blob called libTPU on Google's cloud instances. It's all closed source. It's all hidden stuff. And you know, well, there's a reason Google made it closed source. Amazon made a clone of the TPU. It's called Inferentia. Or they have some other name for it, a training. Tranium. Yeah, yeah, yeah. And look, it's a clone of the TPU. But Google's software at least kind of works. [00:09:58]Alessio: So those are kind of like the three core pieces. The first thing you're working on, that you've been working on, is TinyGrad. And one of your Twitch streams, you said, is the best thing you've ever written. [00:10:07]Swyx: Yeah. [00:10:08]Alessio: Tell us a bit more about that creation. [00:10:10]George: For a long time, TinyGrad had a hard limit at a thousand lines of code. And what this would force you to do is really make sure you were not wasting lines. I got rid of the restriction because it became a little code golfy at the end. But once like the core framework of TinyGrad was there in those thousand lines, but like the core framework, the ideas are expressed with no boilerplate. If you go read PyTorch, you know, PyTorch I think is actually pretty good code. I think Facebook's pretty good, but there's so much boilerplate. Go in PyTorch and try to track down how an LGU actually works. [00:10:44]Swyx: Just a lot of instructions. [00:10:45]George: Oh, you're going to be diving down a long stack from Python to C to custom libraries to dispatchers to, and then I don't even know how to read TensorFlow. I don't even know where's an LU in TensorFlow. [00:10:55]Swyx: Nobody knows. [00:10:56]George: Someone at Google knows maybe. Google as an organism knows. I don't know if anyone individual at Google knows. [00:11:02]Alessio: What are like the important ergonomics like for a developer as you think about designing the TinyGrad API? [00:11:07]George: So the TinyGrad front end looks very similar to PyTorch. There's an even higher level front end you can use for TinyGrad, which is just ONNX. We have better support for ONNX than Core ML does. And we're going to have, I think we're going to pass ONNX Runtime soon, too. People think ONNX Runtime, that's the gold standard for ONNX. No, you can do better. [00:11:23]Swyx: Pass them in what, specifically? Test compliance tests. [00:11:26]George: So ONNX has a big set of compliance tests that you can check out. And we have them running in TinyGrad, and there's some failures. We're below ONNX Runtime, but we're beyond Core ML. So that's where we are in ONNX support now. But we will pass ONNX Runtime soon because it becomes very easy to add ops because you don't need to do anything at the lower levels. You just do it at this very high level, and TinyGrad compiles it to something that's fast using these minimal ops. You can write, most concretely, what TinyGrad can do that PyTorch can't really do, is if you have something like A times B plus C. If you write that in NaivePyTorch, what it's going to do on the GPU is read A, read B in a kernel, and then store A times B in memory, and then launch another kernel to do A times B plus C. Okay, got to do those loads from memory. It's a whole extra round trip to memory that I just didn't have to do. And you're like, yeah, but you can use the Torch JIT, and it corrects this. Yeah, for that one example, for that one example of MUL/ACC, but, oh, now you did three multiplies? Six multiplies? It won't compile arbitrary code. [00:12:26]Swyx: And have you looked into the other approaches like PyTorch Lightning to accelerate PyTorch itself? [00:12:32]George: Well, PyTorch Lightning, my understanding is, it's mostly a framework around PyTorch, right? PyTorch Lightning is not going to fix this fundamental problem of I multiply six tensors together. It's not going to fix it going to memory any more than a single read from each and a single write to the output. There are lower level things in PyTorch that are, I'm not exactly sure what Dynamo does, but I know they're generating some Triton stuff, which is going to generate the kernels on the fly. But, you know, PyTorch Lightning is at a higher level of abstraction. So TinyGrad's front-end stuff looks like PyTorch. I made a few tweaks. There's a few things I don't like about PyTorch. Why is Relu a class? Really, what's the state? You make a class, and there's a state. Everything should just be Torch functional and then Relu, but just dot Relu on the tensor. There's things in Torch where you have to do tensor dot and not a tensor dot. It just shows an API that's not perfectly refined. But when you're doing stuff TinyGrad style where you don't have lines, well, it has to work this way. Because even the lines to express the, well, you can't use the where operator in PyTorch. Why is it true case, condition, false case? Ugh, that's how Python expresses ifs. It's disgusting. Turner operators are much nicer. It should be, I can do my like a less than zero dot where a comma one, right? [00:13:46]Swyx: The very pandas-like API? [00:13:50]George: It looks like Torch, NumPy, pandas. They're all very similar. I tried to take the cleanest subset of them and express them. But like I said, you can also interact with it using ONNX. I have a rewrite of StableDiffusion, I have a rewrite of Llama, I have a rewrite of Whisper. You can look at them. They're shorter than the Torch versions, and I think they're cleaner. And you stream them all? [00:14:05]Swyx: Yeah. Very nice. [00:14:07]Alessio: So what's the other important concept that you're leveraging to do operation fusing? [00:14:11]George: Yeah, you have basically like a few different like models for the simplest one is eager is as soon as the interpreter sees A times B, it actually dispatches A times B, right? Then you have graph like TensorFlow, which will put A times B into a graph, and then we'll do absolutely nothing until you actually compile the graph at the end. I like this third choice, which is somewhere in the middle, laziness. Laziness is you don't know when the ops are going to dispatch, and don't worry about that. You don't have to worry about this as a programmer, you just write out all your stuff. And then when you actually type `.numpy`, it'll be ready by the time you copy the thing back to CPU. Or you can do `.realize`, and it will actually like force that tensor to be allocated in RAM. And if you think about it, PyTorch is kind of lazy in a way, but they didn't extend the paradigm far enough, right? When I do A times B in PyTorch, it's going to launch a CUDA kernel to do A times B. But it's not going to wait for that CUDA kernel to complete. So you're getting the worst possible worlds. You're getting the same laziness, but you also can't get fusion, because PyTorch doesn't know that I'm then going to do plus C. There's no way for it to be like, whoa, whoa, whoa, don't launch that CUDA kernel. Whoa, just do this one too. Right? Again, PyTorch is working on this, and it's a little bit harder. In Kama, I felt like I was competing against a lot of idiots. Here, I'm competing against smart, very smart people who've made some, I think, different trade-offs. Whereas, if you're trying to build something that is just straight up good on NVIDIA, and we have a lot of people and complexity to throw at it, yeah, PyTorch made a lot of the right choices. I'm trying to build something that manages complexity. You can always make your software do more. The magic is when you can make your software do more without adding complexity, right? Because complex things eventually collapse under their own weight, so it's kind of... [00:15:58]Alessio: How does fusing actually work? [00:16:00]George: There's this thing called lazy.py, and when you do A times B, that's... It's put into a graph, but it's a very local graph. There's no global graph optimizations. And even this can change, right? Again, the programming model for TinyGrad does not preclude eagerness, right? Laziness is not guaranteed laziness. It's just going to try its best. So you put in A times B, and that's a binary op, right? And then you put in A times B, that's a node in the graph. It's a virtual node because it's not realized yet, plus C. Okay, here's a new node, which takes the C tensor in here and takes the output of A times B. It's like, whoa, there's two binary ops. Okay, we'll just fuse those together. Okay, here I have a kernel. This kernel has A, B, and C as inputs. It does A times B plus C in the local registers, and then outputs that to memory. And you can graph.one in TinyGrad. Another amazing thing that TinyGrad has that I've not seen in any other framework is two things. Graph equals one, which is an environment variable. It will output a complete graph of all the operations. Other people are like, oh, you can use PyTorch, export it to ONNX, and use Netron. Yeah, you can. Like, what? That's not what's real. Graph equals one will show you the actual kernels that were dispatched to the GPU. You can also type debug equals two, which will print those kernels out in your command line, and it will tell you the exact number of flops and the exact number of memory accesses in each kernel. So you can immediately see, wait a second, okay, this kernel used this many flops. This was the gigaflops. This is how many bytes it read, and this was the gigabyte per second. And then you can profile without having to like, okay, I mean, in theory, in PyTorch, Sure, use the NVIDIA Insight Profiler. No one does that. No one does, of course, because it's so difficult, right? Like, actually, NVIDIA used to, I think CUDA 9 was the last one that had it. They had a command line one, but now it's like, okay, I'm going to generate this blob, use this NVIDIA GUI tool to convert it into a Chrome trace, and then load it. Yeah, no one does that, right? Just type debug equals two in any TinyGrad model, and it will show you all the kernels that it launches and the efficiency of each kernel, basically. [00:17:58]Swyx: Yeah, this is something that John Carmack has often commented about, is that when you code, you need to build in your instrumentation or observability right into that. I wonder if whatever John is working on, he's adopting this style, and maybe we can sort of encourage it by, I don't know, naming it and coining a certain kind of debugging style? [00:18:16]George: If he would like to start contributing to TinyGrad, I'd be so happy. [00:18:19]Swyx: You should hook up with them. [00:18:22]George: I've chatted with them a few times. I'm not really sure what his company's doing, but no, I mean, hopefully we get TinyGrad to a point where people actually want to start using it. So TinyGrad right now is uncompetitive on NVIDIA, and it's uncompetitive on x86. [00:18:36]Swyx: And specifically, what do you care about when you say uncompetitive? Speed. [00:18:39]George: Share of speed. It's correct. The correctness is there. The correctness for both forwards and backwards passes is there. But on NVIDIA, it's about 5x slower than PyTorch right now. Like 5x, wow, this is unsurmountable. No, there's reasons it's 5x slower, and I can go through how we're going to make it faster. It could be 100x slower, so we're making progress. But there's one place where it actually is competitive, and that's Qualcomm GPUs. So TinyGrad is used to run the model in OpenPilot. Like right now, it's been live in production now for six months. And TinyGrad is about 2x faster on the GPU than Qualcomm's library. [00:19:10]Swyx: What about Qualcomm architecture? [00:19:12]George: What makes it doable? Well, because the world has spent how many millions of man hours to make NVIDIA fast? And Qualcomm has a team of 10 Qualcomm engineers? Okay, well, who can I beat here? What I propose with TinyGrad is that developer efficiency is much higher. But even if I have 10x higher developer efficiency, I still lose on NVIDIA, right? You know, okay, I didn't put 100,000 man hours into it, right? If they put a million, like, that's what I'm saying. But that's what I'm saying we can get. And we are going to close this speed gap a lot. Like I don't support TensorCourse yet. That's a big one that's just going to, okay, massively close the gap. And then AMD. I don't even have a benchmark for AMD because I couldn't get it compiled. Oh, and I tried. Oh, I tried. I spent a day. Like, I spent actually a day trying to get PyTorch. And I got it built. I got it kind of working, then I tried to run a model, like, there's all kinds of weird errors and the rabbit holes are so deep on this. I'm like, you know, you can compare the speed. Right now, you can run LLAMA, you can run anything you want on AMD. It already all works. Any OpenCL backend works, and it's not terribly slow. I mean, it's a lot faster than crashing. So it's infinitely times faster than PyTorch on AMD. But pretty soon, we're going to start getting close to theoretical maximums on AMD. That's really where I'm pushing. And I want to get AMD on MLPerf in a couple months, hopefully. [00:20:26]Swyx: Now that you bring up AMD. [00:20:27]Alessio: Yeah, let's dive into that. Because when you announced the Semicore fundraise, you mentioned one of your first goals is like build the framework, runtime and driver for AMD. And then on June 3rd on Twitch, you weren't as excited about AMD anymore. Maybe let's talk a bit about that. You compared the quality of commit messages from the AMD kernel to the Intel work that people are doing there. What's important to know? [00:20:51]George: When I said I want to write a framework, I never intended on writing a kernel driver. I mean, I flirted with that idea briefly, but realistically, there's three parts to it, right? There's the ML framework, there's the driver, and then there's the user space runtime. I was even down to rewrite the user space runtime. I have a GitHub repo called CUDA IOControlSniffer. It's terribly called. But you can actually launch a CUDA kernel without CUDA. So you don't need CUDA installed. Just the NVIDIA open source driver and this open source repo can launch a CUDA kernel. So rewriting the user space runtime is doable. Rewriting the kernel driver? [00:21:26]Swyx: I don't even have docs. [00:21:27]George: I don't have any docs for the GPU. Like it would just be a massive reverse engineering project. I wasn't complaining about it being slow. I wasn't complaining about PyTorch not compiling. I was complaining about the thing crashing my entire computer. It panics my kernel. And I have to wait five minutes while it reboots because it's a server motherboard and they take five minutes to reboot. So I was like, look, if you guys do not care enough to get me a decent kernel driver, there's no way I'm wasting my time on this, especially when I can use Intel GPUs. Intel GPUs have a stable kernel driver and they have all their hardware documented. You can go and you can find all the register docs on Intel GPUs. So I'm like, why don't I just use these? Now, there's a downside to them. Their GPU is $350. You're like, what a deal. [00:22:03]Swyx: It's $350. [00:22:04]George: You know, you get about $350 worth of performance. And if you're paying about $400 for the PCIe slot to put it in, right, like between the power and all the other stuff, you're like, okay, nevermind. You got to use NVIDIA or AMD from that perspective. But I sent an email to Lisa Su. She responded. [00:22:19]Swyx: Oh. [00:22:20]George: And I've had a few calls since. And like, what I tried to do, first off, like, thank you for responding. It shows me that like, if you don't care about your kernel panicking, I can't, like, this is just a huge waste of my time, right? I'll find someone who will care. I'm not asking for your seven by seven Winograd convolution when transposed to be fast. Like, I'm not asking for that. I'm asking literally for- The basics of getting it running. Oh, and this isn't TinyGrad. This is your demo apps. I ran their demo apps in loops, and I got kernel panics. I'm like, no, okay. No, Lisa Su reached out, connected with a whole bunch of different people. They sent me a pre-release version of RockM 5.6. They told me you can't release it, which I'm like, guys, why do you care? But they say they're going to release it by the end of the month, and it fixed the kernel panic. The guy managed to reproduce it with the two GPUs and the computer, and yeah, sent me a driver, and it works. I had that experience, and then I had another experience where I had two calls with, like, AMD's, like, communication people. I was just like, I tried to explain to these people, like, open source culture. Like, it's not open source if you dump the source code on a GitHub repo and then forget about it until the next release. It's not open source if all your issues are from 2022. Like, it's just no one's going to contribute to that project, right? Sure, it's open source in a very, like, technical sense. To be fair, it's better than nothing. It's better than nothing, but I fixed a bug in Nickel that I fixed. There's a fun fact, by the way. If you have a consumer AMD GPU, they don't support peer-to-peer, and their all-reduce bandwidth is horrendously slow because it's using CUDA kernels to do the copy between the GPUs, and it's putting so many transactions on the PCIe bus that it's really slow. But you can use CUDA memcpy, and there's a flag to use CUDA memcpy, but that flag had a bug. I posted the issue on Nickel. I expected nothing to happen. The NVIDIA guy replied to me within an hour. He's like, try this other flag. I'm like, okay, I tried the other flag. It still doesn't work, but here's a clean repro. And I spent, like, three hours writing a very clean repro. I ended up tracking the issue down myself, but just the fact that somebody responded to me within an hour and cared about fixing the issue? Okay, you've shown that it's worth my time, and I will put my time in because, like, let's make this better. Like, I'm here to help. But if you show me that, you know, you're like, you're the kernel panics. That's just, like, expected. Okay. [00:24:36]Swyx: Well, it sounds like AMD is getting the message. [00:24:38]George: They are. And I just, I don't really think they've had someone explain to them, like, like, I was like, you can, like, build in public. And they're like, what's an example of building in public? I'm like, go look at PyTorch. Go look at PyTorch. I have two minor things merged into PyTorch because it's very responsive, you know? [00:24:53]Alessio: So that's kind of like the lowest level of the stack. And then at a slightly higher level, obviously, there's TinyGrad, there's Mojo, there's ggml. How are you thinking about breadth versus, like, depth? Like, where you decided to focus early on? [00:25:06]George: So ggml is very much like a, okay, everyone has M1s, right? Actually, I was thinking, in the beginning, I was thinking of something more like ggml, focused on the M1s. But ggml showed up and was just like, we're actually just focusing on the M1s. And actually, M1 PyTorch is considerably better than AMD PyTorch. M1 PyTorch works, it only gives wrong answers sometimes, and it only crashes sometimes. But, like, some models kind of run. When I was writing the metal backend, I was comparing to MPS PyTorch, and I had, like, a discrepancy. TinyGrad checks all its outputs compared to Torch, and I had one where it didn't match. I'm like, I checked the matrix by hand, it matches TinyGrad, I don't understand. And then I switched PyTorch back to CPU, and it matched. I'm like, oh. Well, there's, like, bugs, like, if you, like, transpose the matrix, because, like, I think it has to do with, like, multi-views in PyTorch, and, like, weird under-the-hood stuff that's not exposed to you, like, there's bugs. And maybe they fixed them, but, like, you know, it seems like there was a lot of momentum. Again, because you're getting how many engineers care about making PyTorch work on M1, right? Thousands, tens of thousands. And you have an open development process, and guess what? It's going to be good. How many engineers care about AMD working, PyTorch AMD working? Well, you got 10 guys that work for AMD, and then, like, a couple hobbyists. [00:26:15]Swyx: You revealed an interesting detail about how you debug. You hand-check the matrix math? No, I don't hand-check it. [00:26:20]George: One of the best tests in TinyGrad is a file called testops.py. And it's just a hundred small examples written in TinyGrad and PyTorch, and it checks both the forwards and backwards to make sure they match. [00:26:34]Swyx: Good test suite. Yeah. Very important. [00:26:35]George: That's, I mean, that's one of them where, like, I really, I put a lot of effort into CI for TinyGrad. I think CI is super important. Like, I want that green check to mean I can merge this, right? Like, I don't want my tests to, and if the green check, if you somehow manage to introduce a bug and get the green check, okay, we're fixing the test, top priority. [00:26:51]Swyx: Mojo? [00:26:52]George: It's closed source. No, I'm not that interested. Do you know what I mean? Like, look, I like Chris Lattner. I think he's going to do great things, and I understand the, like, kind of the wisdom, even, in keeping it closed source. But, you know, I'm interested when it's open. [00:27:05]Swyx: Yeah. You have an interesting design deviation from him, because he's decided to be a, well, promised to be a superset of Python, and you have decided to break with PyTorch APIs. And I think that affects learnability and transportability of code. [00:27:18]George: You know, if the PyTorch thing ends up being, like, a stumbling block, I could write a perfect PyTorch instead of import PyTorch. Instead of, like, yeah, import torch, you type import tinytorchestorch. And if that really becomes the stumbling block, I will do that. No, Chris Lattner went much further than PyTorch. Replicating the PyTorch API is something I can do with a couple, you know, like an engineer monitor. [00:27:44]Swyx: A shim. [00:27:44]George: Right, like a shim, yeah. Replicating Python? [00:27:47]Swyx: Hoo-hoo-hoo! [00:27:48]George: There's a big graveyard of those projects. How's Piston going? How's Jython? [00:27:57]Swyx: PyPy? Oh, you can go way back. [00:27:59]Alessio: So your core mission is commoditizing the petaflop. And then your business goal is to sell computers for more than the cost to make, which seems super reasonable. And you're going to have three tiny boxes? [00:28:11]Swyx: Red, green, blue? No, no, no, no, no, no, no. [00:28:13]George: That was my... Look, you know, a lot of people, like, I love, you know, leaning into, like, saying I'm giving up, right? It's great to give up, right? Giving up is this wonderful thing. It's so liberating. And then, like, you can decide afterward if you really give up or not. There's very little harm in saying you give up, except, like, you know, great, Twitter haters have something to talk about, and all press is good press, kids, so... Just red, only red. [00:28:32]Swyx: Tiny box, red. Tiny box, red. [00:28:34]George: Unless AMD, you know, upsets me again, and then we're back to other colors. We have other colors to choose from. [00:28:41]Alessio: When you think about hardware design, what are some of the numbers you look for? So, teraflops per second is one, but, like, memory bandwidth is another big limiter. Like, how do you make those trade-offs? [00:28:52]George: Well, I mean, fundamentally, I'm limited to what GPUs I can buy. But, yeah, for something that I think a lot of people are going to want to reasonably do, with, um... A coworker of mine described them as luxury AI computers. Right? Like, luxury AI computers for people. And that's, like, what we're building. And I think a common thing people are going to want to do is run, like, Large Llama. Right? Or Large, like, Falcon or whatever. [00:29:13]Swyx: FB-16 Llama. [00:29:14]George: FB-16, exactly. Exactly. Um, you know, Int8, I think, can work. I think that, like, what GGML is doing to go to, like, N4. Like, this doesn't work. Like, have you done... I mean, maybe they have. But, like, I read what it was, and I was like, this isn't from any paper. This is just some... Squeezing as much as possible. Yeah, you made up some quantization standards to make it run fast. And, like, maybe it works. But, okay, where's, like, the Hellaswag number? Right? Where's your, uh... [00:29:38]Swyx: The thesis is right. That, like, if you have hundreds of billions of parameters, that the individual quantization doesn't actually matter that much. [00:29:44]George: Well, the real way to look at all of that is to just say you want to compress the weights, right? It's a form of weight compression. Quantization is a form of weight compression, right? Now, this is obviously not lossless. It's not a lossless compressor, right? If it's a lossless compressor, and you can show that it's correct, then, okay, we don't have to have any other conversation. But it's a lossy compressor. And how do you know that your loss isn't actually losing the power of the model? Maybe int4 65B llama is actually the same as FB16 7B llama, right? We don't know. Maybe someone has done this yet, but I looked for it when it, like, first came out and people were talking about it. And I'm like, it's not from a paper, right? The indate stuff is from a paper where they... Like, some of the indate stuff is from a paper. There's one paper, I think it's, like, indate... LLM.indate, where they actually do all the tests. And they didn't go fully indate. They made, like, 90% of it indate and kept, like, 10% of it in FB16 for what they called, like, the outliers or whatever. So I think that this is not quite so easy. [00:30:37]Swyx: And I think being able... [00:30:38]George: Well, so first off, if you're training, no one's gotten training to work with indate yet. There's a few papers that vaguely show it. But if you're training, you're going to need BF16 or float16. So this is why I target that. Now, the thing that you're going to want to do is run these large language models out of the box on your hardware in FB16, and that's memory bandwidth. So you need large amounts of memory bandwidth, too. So ask how I trade off memory bandwidth in Flop, so what GPUs can I buy? [00:31:02]Alessio: So first of all, you have this hiring process, which is you've got to solve one of the bounties that are open on TinyGrad. There's no technical interview. One of them is indate support. Do you already have some things you want to test on? [00:31:14]Swyx: We have indate support. What I'd like to see somebody do [00:31:16]George: is just load the ggml indate llama into TinyGrad and then benchmark it against the FB16 one. Indate already works in TinyGrad. It doesn't actually do the math in indate. It does all the math still in FB32. So indate can mean you just have your weights in indate, or indate can mean you actually do your math in indate. And doing your math in indate, the big gain that people care about is actually having your weights in indate, because weights in indate mean less memory and less memory bandwidth, whereas the math, keep it in FB32. With on M1s, it doesn't matter what data type you're doing in the GPU. I'm not even sure it can do indate, but FB16 and FB32 is the same tariff ops. So yeah, no, that's one of the bounties. One of the bounties is get indate llama running [00:31:58]Swyx: with the indate weights. [00:32:00]George: And then actually, what you could even do, if you really want to test this, just take the FB16 weights, convert them to indate, then convert them back to FB16, then compare the unconverted and converted. [00:32:10]Swyx: Oh, that's a nice hack. Oh, yeah. Right, like- This should be lossless in the other direction. Yeah, I think FB16, [00:32:17]George: it should be lossless in the other direction. I'm actually not 100% about that. Why not? Oh, because like, you ever try to like, like if you want to represent, if it was like int16, it's not lossless. [00:32:25]Swyx: Sure. [00:32:26]George: All of indate can be represented in FB16, but I'm not 100% about that. [00:32:29]Swyx: Just drop the bytes. We just have to do it, right? [00:32:32]George: Just literally do it. There's only 256 to check, like. But yeah, either way, or I mean, int4, definitely. So do your int4, convert it back, and now see, even with int4 weights and FB32 math, like, okay, how much has your performance degraded this model? [00:32:47]Alessio: I think like the, you're planning to release the first tiny box, ship them in like two to six, eight months, something like that. What's top of mind for you in terms of building a team? Who should, who are you calling for? [00:32:59]George: So as the GPU is picked out and you're like, well, I could make that computer with the GPUs. And my answer is, can you? Do you know how hard it is to put six GPUs in a computer? And people think it's really easy. And it's really easy to put one GPU in a computer. It's really easy to put two GPUs in a computer, but now you want to put in eight. Okay, so I'll tell you a few things about these GPUs. They take up four slots. You can buy the nicest super micro. You can't put eight of those in there. You need two slot blowers. [00:33:25]Swyx: If you want to use one of those, [00:33:25]George: those for you super micros, you need two slot blowers or water cooling, right? If you're trying to get the four slot cards in there, you're going to need some form of water cooling. There are some like Chinese 40 nineties that are blowers, right? You have any blowers or water cooling if you're trying to get it in those things, right? [00:33:37]Swyx: So are you doing water? [00:33:39]George: No, I'm not using that chassis. Okay, so now you want to get six GPUs in a computer. So that's a big challenge. You're like, oh, I'll just use a PCIe extenders. I saw it online as tech tips. It works great. No, it doesn't. Try PCIe extenders that work at PCIe 4.0 and interconnect bandwidth, super important. They don't work at 3.0. No PCIe extender I've tested, and I've bought 20 of them, works at PCIe 4.0. So you're going to need PCIe re-drivers. Now, okay, how much is that adding cost, right? Like these things all get really hard. And then tiny boxes, I've even had another constraint to it. I want this thing to be silent, not totally silent, but my limit is like 45, maybe 50 DB, but not super micro machine, 60 DB. We have a small, we have a compute cluster at comma. You gotta wear ear protection to go in there. Like- [00:34:24]Swyx: Yeah, I've seen some videos where you give a tour. Oh yeah. It's noisy. It's super loud. [00:34:28]George: You got all these machines just screaming. All those, like if you have a blower, what is that thing? 10,000 RPM, just screaming. Like I want to be able to use the normal big GPU fans and make this thing so it can sit under your desk, plug into one outlet of power, right? Six GPUs, your GPUs are 350 Watts each. Can't plug that into a wall outlet. Okay, so how are you going to deal with that? Good questions, right? [00:34:51]Swyx: And you're not sharing them. [00:34:52]George: Well, that one, I mean, that one is pretty obvious. You have to limit the power on the GPUs, right? You have to limit the power on the GPUs. Now you can limit power on GPUs and still get, you can use like half the power and get 80% of the performance. This is a known fact about GPUs, but like that's one of my design constraints. So when you start to add all these design constraints, good luck building a tiny box yourself. Obviously it can be done, but you need something that has actually quite a bit of scale and resources to do it. [00:35:15]Alessio: And you see like the, under the desk, it's like one of the main use cases, kind of like individual developer use or. [00:35:21]George: Yeah, what I also see is more of a, like an AI hub for your home, right? As we start to get like home robotics kind of stuff, you don't want to put the inference on the robot, but you also don't want to put the inference on the cloud. Well, you don't want to put it on the robot because, okay, it's 1500 Watts, tiny box. You'll put batteries and charge them, bad idea. Just wireless. Wireless is 0.5 milliseconds, right? This is super fast. You don't want to go to the cloud for two reasons. One, cloud's far away. Okay, it's not that far away. You can kind of address this. But two, cloud's also mad expensive. Like cloud GPUs are way more expensive than running that GPU at your house. At least any rates you're going to get, right? Maybe if you commit to buy, well, yeah, I'm going to buy 10,000 GPUs for three years, then maybe the cloud will give you a good rate. But like, you want to buy one GPU in the cloud? I mean, okay, you can go to like vast, but like if you're going on Azure AWS, so that's expensive. [00:36:12]Swyx: This is like a personal data center instead of a cloud data center. [00:36:16]George: We like the term compute cluster. So we can use NVIDIA GPUs. [00:36:20]Swyx: Yeah, data centers may be a little bit dated. It's a compute cluster, [00:36:23]George: which is totally legal under the CUDA license agreement. [00:36:26]Swyx: You talk a lot about the PCIe connection. Do you think there's any fat there to trim? What do you mean? You're limited by bandwidth. [00:36:32]George: Okay, for some things, yes. So bandwidth is roughly 10x less than what you can get with NB-linked A100s, right? NB-linked A100s are going to have, and then you can even get like full fabric and NVIDIA really pushes on that stuff, 600 gigabytes per second, right? And PCIe, four, you're going to get 60, right? So you're getting 10x less. That said, why do you need the bandwidth, right? And the answer is you need it for training huge models. If you're training on a tiny box, your limit's going to be about 7 billion. If you're training on big stuff, your limit's going to be like 70 billion, right? Okay, you can hack it to get a bit higher. You can hack it, like GPT hacked it to get a bit higher, but like that 65 billion in LLAMA, like there's a reason they chose 65 billion, right? And that's what can reasonably fit model parallel on a GPU, right? So yes, you are going to end up training models. The cap's going to be like 7 billion, but I actually heard this on your podcast. I don't think that the best chatbot models are going to be the big ones. I think the best chatbot models are going to be the ones where you had a thousand training runs instead of one. And I don't think that the interconnect bandwidth is going to matter that much. [00:37:33]Swyx: So what are we optimizing for instead of compute optimal? What do you mean compute optimal? You're talking about this, the LLAMA style models where you train for like 200x. You train longer, yeah. [00:37:41]George: Yeah, yeah, yeah. You can always make your model better by doing one of two things, right? And a comma, we just have a strict limit on it. You can always make your model better by training longer, and you can always make your model better by making it bigger. But these aren't the interesting ones, right? Particularly the making it bigger because training it longer, fine. You're getting a better set of weights. The inference is the same. The inference is the same whether I trained it for a day or a week. Okay, if it's 1 billion versus 10 billion, well, I 10x my inference too, right? So I think that these big models are kind of, sure, they're great if you're research labs and you're trying to like max out this hypothetical thing. [00:38:13]Swyx: Which you can talk about later. Yeah, yeah, yeah. [00:38:15]George: But if you're like a startup or you're like an individual or you're trying to deploy this to the edge anywhere, you don't need that many weights. [00:38:22]Swyx: Yeah, yeah. You actually don't want that many weights. Optimizing for inference rather than capabilities doing benchmarks. Yes. [00:38:29]George: And I think the inference thing, right? There's gonna be so much more. Right now, the ratio between like training and inference on clouds, I think it's only still, I think it's like two or three X, right? It's two or three X more inference, which doesn't make any sense. It's way more inference. [00:38:41]Swyx: Yeah. [00:38:42]George: There should be 10 to 100 X more inference in the world than training. But then also like, what is training, right? You start to see these things like LoRa, like it's kind of blurring the lines between inference and training. And I think that that blurred line is actually really good. I'd like to see much more like on-device training or on-device fine tuning of the final layer. We're pushing toward this stuff at Comma, right? Like why am I shipping a fixed model? I totally want this model to fine tune based on like how your left tire is flat, right? Every time you cut the same turn because your left tire is flat, well, it should learn that, right? [00:39:11]Swyx: So would Comma pursue parameter efficient fine tuning? Yeah. [00:39:16]George: We're looking into stuff like that. I mean, Comma is already very parameter efficient because we have to like run this thing in a car and you have to like cool it and power it. [00:39:22]Alessio: And so this kind of like intelligence cluster you have in your home, you see when the person is using third-party model, they load them locally and kind of do the final fine tuning. It kind of stays within the box. [00:39:33]George: I think that that's one version of it for the privacy conscious. I also see a world where you can have your tiny box in its down cycles, mine flop coin, right? You know, it turns out not all crypto is a scam. [00:39:45]Swyx: There's one way to tell if crypto is a scam. [00:39:46]George: If they're selling the coin before they make the product, [00:39:49]Swyx: it's a scam. [00:39:49]George: If they have the product and then they sell the coin, it's maybe not a scam, right? So yeah, my thought is like each tiny box would let you, would have a private key on it. And you have to do it this way. You can't just let anyone join because of Sybil attacks, right? [00:40:01]Swyx: There's a real problem of like, [00:40:01]George: how do I ensure your data is correct? And the way that I ensure your data is correct on the tiny net is if you ever send wrong data, you're banned from the network for life. [00:40:08]Swyx: Yeah. [00:40:09]George: Your $15,000 hardware box is banned. [00:40:11]Swyx: So, you know, don't cheat. [00:40:11]George: Obviously if it messes up, we'll forgive you. [00:40:14]Swyx: Somebody's going to try to jailbreak your devices. There's no jailbreak. [00:40:17]George: There's no jailbreak. [00:40:18]Swyx: It's just a different network. [00:40:19]George: Well, there's just a private key on ea ch device, right? Like if you buy a tiny box from the tiny corp, [00:40:23]Swyx: I give you a private key. [00:40:23]George: It's in my backend server, right? You want to hack my server, that's illegal. Anything you want to do on the device, the device is yours. My server's mine, right? [00:40:29]Swyx: Yeah. Have you looked into like a federated training at all? [00:40:33]George: Okay. There's orders of magnitude of federated training. You mean like over the cloud and stuff? [00:40:37]Swyx: Over the internet? Yeah. Over the internet, but also distributed on a bunch of devices, right? [00:40:41]George: Yeah, I'm very bearish on this stuff. Because your interconnect bandwidth, right? So, okay. At the high end, you have your interconnect bandwidth of NVLink, which is 600 gigabytes per second, right? The tiny box has 60 gigabytes per second. And then your internet has 125 megabytes per second, right? Not gigabits, 125 megabytes, right? So, okay. That's how many orders of magnitude we're talking here? Like from 60 down to 125? Like, all right, that's over a hundred X. That's 400 X, right? So like, what you can do is inference, right? Like there's, for inference, you don't care, right? For inference, there's so little bandwidth at the top and the bottom of the model that like, yeah, you can do federated inference, right? And that's kind of what I'm talking about. There's also interesting things to push into, like you're like, but okay, what if you want to run closed source models? This stuff gets kind of interesting, like using TPMs on the boxes and stuff. But then someone might jailbreak my device. So, you know, maybe we don't try to do that. [00:41:34]Alessio: Yeah, what's like the enterprise use case? Do you see companies buying a bunch of these and like stacking them together? [00:41:39]George: The tiny box is like the first version of what we're building. But what I really want to do is be on the absolute edge of flops per dollar and flops per watt. These are the two numbers that matter. So the enterprise use case is you want to train, like Kama, right? So Kama just built out a new compute cluster. It's about a person and a half. [00:41:56]Swyx: A person being 20 petaflops. [00:41:58]George: A person is 20 petaflops. It's about 30 petaflops. We built out a little compute cluster and, you know, we paid double what you theoretically could per flop, right? You theoretically could pay half per flop if you designed a bunch of custom stuff. And yeah, I mean, I could see that being, you know, a tiny corp. Kama's going to be the first customer. I'm going to build a box for Kama and then I'm going to show off the box I built for Kama and be like, okay, like, do you want to build? I sell $250,000 training computers. Or how much is one H100 box? [00:42:26]Swyx: It's 400 grand? [00:42:27]George: Okay, I'll build you a 400 grand training computer and it'll be 10x better than that H100 box. Again, not for every use case. For some, you need the interconnect bandwidth. But for 90% of most companies' model training use cases, the tiny box will be 5x faster for the same price. [00:42:41]Alessio: You mentioned the person of compute. How do we build a human for $20 million? [00:42:47]George: Well, it's a lot cheaper now. So like I said, Kama spent about half a million on our person and a half, so. [00:42:54]Alessio: What are some of the numbers people should think of when they compare compute to like people? So GPT-4 was 100 person years of training. That's more like on the timescale. 20 petaflops is one person. I think you, right now the math was that for the price of the most expensive thing we build, which is the International Space Station, we could build one Tampa of. Yeah, yeah, one Tampa of compute. [00:43:16]Swyx: Yeah, which is the ultimate currency of measurement. [00:43:20]George: Yeah, yeah, we could build. So like the biggest training clusters today, I know less about how GPT-4 was trained. I know some rough numbers on the weights and stuff, but Lama- [00:43:28]Swyx: A trillion parameters? [00:43:30]George: Well, okay, so GPT-4 is 220 billion in each head, and then it's an eight-way mixture model. So mixture models are what you do when you're out of ideas. So, you know, it's a mixture model. They just train the same model eight times, and then they have some little trick. They actually do 16 inferences, but no, it's not like- [00:43:45]Swyx: So the multimodality is just a vision model kind of glommed on? [00:43:49]George: I mean, the multimodality is like obvious what it is too. You just put the vision model in the same token space as your language model. Oh, did people think it was something else? The mixture has nothing to do with the vision or language aspect of it. It just has to do with, well, okay, we can't really make models bigger than 220 billion parameters. We want it to be better. Well, how can we make it better? Well, we can train it longer, and okay, we've actually already maxed that out. We're getting diminishing returns there. [00:44:13]Swyx: Okay. A mixture of experts. [00:44:14]George: Yeah, a mixture of experts. We'll train eight of them, right? [00:44:16]Swyx: So, all right. [00:44:17]George: So, you know, the real truth is whenever a start, whenever a company is secretive, it's because they're hiding something that's not that cool. And people have this wrong idea over and over again that they think they're hiding it because it's really cool. [00:44:28]Swyx: It must be amazing. [00:44:29]George: It's a trillion parameters. No, it's a little bigger than GPT-3, and they did an eight-way mixture of experts. Like, all right, dude, anyone can spend eight times the money and get that. Coming back to what I think is actually gonna happen is, yeah, people are gonna train smaller models for longer and fine-tune them and find all these tricks. OpenAI used to publish stuff on this, you know, [00:44:47]Swyx: when they would publish stuff [00:44:48]George: about how much better the training has gotten holding compute constant. It's gotten a lot better, right? Think, compare like BatchNorm to NoBatchNorm. [00:45:00]Swyx: Is you're finding algorithms like FlashAttention? [00:45:02]George: Yeah, well, FlashAttention, yeah. And FlashAttention is the same compute. FlashAttention is an interesting fact where it's actually the identical compute. It's just a more efficient way to do the compute. But I'm even talking about like, look at the new embeddings people are using, right? They used to use these like boring old embeddings. Now, like, Lama uses that complex one, and now there's like Alibi. I'm not up-to-date on all the latest stuff, but those tricks give you so much. [00:45:23]Swyx: There's been a whole round trip with positional embeddings. I don't know if you've seen this discussion. I haven't followed exactly. [00:45:29]George: I mean, you quickly run into the obvious problem with positional embeddings, which is you have to invalidate your KV cache if you run off the context. So that's why I think these new ones, [00:45:38]Swyx: they're playing with them, [00:45:38]George: but I'm not an expert on like the latest up-to-date language model stuff. [00:45:43]Alessio: What are some of the things, I mean, that people are getting wrong? So back to autonomous driving, there was like the whole like LiDAR versus vision thing. People don't get into accidents because they cannot see well. They get into accidents because they get distracted and all these things. Do you see similarities today on like the Pathway GI? [00:45:59]George: Nothing I say about this is ever gonna compete with how Rich Sutton stated it. [00:46:03]Swyx: Rich Sutton, the writer of [00:46:04]George: Reinforcement Learning, The Bitter Lesson. Nothing I say is ever gonna compete with, The Bitter Lesson's way better than any way I'm going to phrase this. Just go read that, and then like, I'm sorry it's bitter, but you actually just have to believe it. Like over and over again, people make this mistake. They're like, oh, we're gonna hand engineer this thing. No, like stop wasting time. [00:46:22]Swyx: I mean, OpenAI is not taking The Bitter Lesson. They were leaders in deep learning for a long, long, long time. [00:46:27]George: Well, OpenAI was the absolute leader to the thesis that compute is all you need, right? [00:46:31]Swyx: And there's a question of how long [00:46:32]George: this thesis is going to continue for. It's a cool thesis, and look, I think I would be lying along with everybody else. I was into language models like way back in the day for the Hutter Prize. I got into AI through the Hutter Prize. Like 2014, I'm trying to build compressive models of Wikipedia. And I'm like, okay, why is this so hard? What this is is a language model, right? And I'm playing with these Bayesian things, and I'm just like, oh, but I get it. I have two data points, and they're almost the same, but how do I measure that almost, right? I just wrapped my head around this, and this was around the time Karpathy released the first RNN that generated the Shakespeare stuff. And I'm like, okay, I get it, right? It's neural networks that are compressors. Now, this isn't actually, you can't actually win the Hutter Prize with these things because the Hutter Prize is MDL. It's the model, size of the model plus the size of the encodings, embeddings. So yeah, you can't, I mean, probably now you can because it's gotten so good. But yeah, back in the day, you kind of couldn't. So I was like, okay, cool. [00:47:29]Swyx: This is what it is. [00:47:29]George: I kind of get it. I didn't expect that it would continue to work this well. I thought there'd be real limits to how good autocomplete could get. That's fancy autocomplete. But yeah, it works well. So like, yeah, what is OpenAI getting wrong? Technically, not that much. I don't know. If I was a researcher, why would I go work there? [00:47:48]Swyx: Yes, so why is OpenAI like the Miami Heat? [00:47:51]George: No, look, this is my technical stuff. I don't really want to harp on this, but like, why go work at OpenAI when you could go work at Facebook as a researcher? OpenAI can keep ideologues who, you know, believe ideological stuff and Facebook can keep every researcher who's like, dude, I just want to build AI and publish it. [00:48:08]Alessio: Yeah, any other thoughts, tiny corp, bounties? [00:48:11]George: You know, I've been thinking a lot about like what it means to hire in today's world. Okay, look, I'm a believer that machines are going to replace everything in about 20 years. So, okay, what is that thing that people can still do that computers can't? And this is a narrowing list, but like, you know, back in the day, like imagine I was starting a company in 1960. Oh, and we're going to have to hire a whole bunch of calculators in the basement to do all the, you know, math to support the, dude, have you heard about computers? Why don't we just buy a few of those? Oh, wow, man, you're right. So like, I feel like that's kind of happening again. And I'm thinking about, I will post in my Discord, I'll be like, who wants to like, okay, I just changed my unary ops used to be log and exp in like E. I changed them to be log two and exp two because hardware has log two and exp two accelerators. [00:48:59]Swyx: Yeah, and of course you can just change your base. [00:49:00]George: It's one multiply to get it back to E. But like, I made the primitives log two and exp two, right? I just posted in the Discord. I'm like, could someone put this pull request up? And someone eventually did and I merged it. But I'm like, this is almost to the level [00:49:12]Swyx: where models can do it. [00:49:14]George: We're almost to the point where I can say that to a model and the model can do it. [00:49:17]Swyx: Have you tried? Yeah, I don't know. [00:49:20]George: I think autocomplete went further than I thought it would, but I'm also relatively unimpressed with these chatbots. The problem is if your loss function is categorical cross entropy on the internet, your responses will always be mid. [00:49:32]Swyx: Yes, mode collapse is what I call it, I don't know. [00:49:35]George: Maybe, I'm not even talking about mode collapse. You're actually trying to predict the, like, look, I rap. I'm a hobbyist rapper. When I try to get these things to write rap, the raps sound like the kind of raps you read in the YouTube comments. [00:49:45]Swyx: Nursery school. [00:49:46]George: Yeah, it's like, all right, great. You rhyme box with fox, sick rhyme, bro. You know, and Drake is rhyming give it up for me with napkins and cutlery, right? Like, all right, come on. [00:49:55]Swyx: He's got like this thing about orange. Orange is famous so you can't rhyme it. Yeah, yeah, yeah, yeah, yeah. [00:49:59]George: But now, of course, you know, four-inch screws and orange juice is in GPT's training course. Yeah, so I think it went further than everyone kind of thought it would. But the thing that I really want to see is like somebody put 10 LLMs in a room and have them discuss the answer before they give it to me. Right, like, you can actually do this, right? And I think the coding things have to be the same way. There is no coder alive, no matter how good you are, that sits down, well, I'm going to start at cell A1 and type my program, and then I'm going to press run and it's going to work. No one programs like that. So why do we expect the models to, right? So there's a lot that, like, still needs to be done. But, you know, at the tiny corp, I want to be on the cutting edge of this, too. I want to be, like, program generation. I mean, what is TinyGrad? It's a compiler, it generates programs. Generate the fastest program that meets the spec, right? Why am I not just having ML do that? So, you know, it's kind of a, you have to exist fluidly with the machines. And I've come around on a lot of stuff. I'm like, wait, TinyGrad, TinyCorp should be a remote company. I can't do this in person. [00:50:58]Swyx: Really? [00:50:58]George: Yeah, like, comma makes sense to be in person. Like, comma, sure. Yeah, we're getting off in San Diego. [00:51:04]Swyx: But that was a six-year-old company, right? [00:51:05]George: And it works, and it works for a certain type of people [00:51:08]Swyx: and a certain type of culture. [00:51:08]George: But what's going to be different this time? Okay, remote, but now it's remote. And now I'm getting these, like, people who apply, and I'm like, I literally have a thousand applications. I'm not calling you to do a technical screen. I can't really tell anything from a technical screen. What am I going to do? Make a code on a whiteboard? Like, bring up a shared notebook document, so we could, oh, like, that's not going to work. Okay, so then I'm moved to the next thing. We do this at Comma with good success, programming challenges. [00:51:31]Swyx: I've also found them to be, like, [00:51:32]George: completely non-predictive. I found one thing to actually be predictive, and it's, wait a second, just write code in TinyGrad. It's open source, right? And yeah, so, you know, I'm talking to a few people who've been contributing, and, like, contribute, or, you know, the job's not for you. But you can do it remote, and it's, look, it's a chill job. Like, you're not, you're like, oh, yeah, well, I work for the tiny corp. Like, well, you're writing MIT-licensed software. Like, you see what it's doing, right? Like, we'll just, I think, think of it as maybe more of, like, a stipend than a salary. And then also some equity. Like, if, you know, I get rich, we all get rich. [00:52:01]Alessio: How do you think about agents and kind of, like, thinking of them as people versus, like, job to be done? Sean built this thing called Small Developer. [00:52:09]Swyx: It's in the same vein. Or, like, the human in the loop with the language model and just iterating while you write code. I think that's absolutely where it goes. [00:52:17]Alessio: And there's, like, a, it's not, like, one thing. It's, like, there's Small Interpreter. There's, like, Small Debugger. It's kind of, like, all these different jobs to be done. [00:52:24]Swyx: It's a small world. [00:52:25]Alessio: Yeah, it's a, I know, this is, like, the small box is, like, small AI meets tiny corp. [00:52:29]Swyx: So we're all in the same wavelength. [00:52:30]Alessio: How do you think about that? Do you think people will have a human-like interaction where it's, like, oh, this is, like, the AI developer, or, like, is it I'm the human being supercharged by the AI tools? [00:52:41]George: Oh, I think it's, yeah, much more like I'm the human supercharged by the AI tools. I think that, like, coding is tool-complete. Like, driving's not tool-complete. We hire people to drive who are, like, below the API line. Right, there's an API line in the world, right? [00:52:53]Swyx: Love that. Yes. [00:52:53]George: Yeah, yeah, yeah, there's an API line in the world. And, like, you can think, like, Uber's a really clear example, right? There's the people below the API line and the people above the API line. And the way you can tell if you're below or above, by the way, is is your manager a computer, right? Who's the manager of the Uber driver? [00:53:06]Swyx: Well, a computer, right? Does the machine tell you what to do or do you tell machines what to do? Exactly, exactly. [00:53:09]George: So, coding is tool-complete, right? [00:53:13]Swyx: Coding is tool-complete. [00:53:13]George: Coding is above the API line. So it will always be tools supercharging your coding workflow. And it will never be you performing some, like, task. Like, okay, well, I can do everything except for actually starting a Docker container. Like, it just doesn't make any sense, right? Yeah, so it will always be sort of tools. And, you know, look, we see the same stuff with all the, like, people are like, stable diffusion's gonna replace artists or whatever. It's like, dude, like- [00:53:38]Swyx: It's gonna create new artists. [00:53:39]George: Did Photoshop replace artists? [00:53:41]Swyx: Like, what are you talking about, right? [00:53:42]George: Like, you know, a real artist's finger paint. They can't use brushes. Brushes are, you know, brushes are gonna replace all the, okay, like, I just can't. Like, it's all just tools and the tools are gonna get better and better and better. And then eventually, yes, the tools are going to replace us. But, you know, that's still 20 years away. So, you know, I got a company to run in the meantime. [00:54:02]Swyx: So I've written about the API line before and I think that's from Venkatesh. I don't know if you've got your directive to it. I don't know, I definitely took it from someone. [00:54:07]George: It's definitely not mine. [00:54:08]Swyx: It's VGR. But I also have a speculated, a higher line than that, which is the Kanban board. Like, who tells the programmers what to do, right? So are you above or below the Kanban board? Has that evolved your management thinking? [00:54:21]George: Yeah, like, that's sort of what I mean. Like, it's like, I'm just gonna describe the pull request in two sentences and then like, yeah. [00:54:28]Swyx: So you are running the Kanban board? Or the bounties, you know? [00:54:31]George: Yes, the bounties are the Kanban board, exactly. And that is kind of the high level. And then like, yeah, we'll get AIs to fill in some and we'll get people to fill in others. And that's also what it means to be like, full-time at TinyCorp, right? Would you start, and I wrote this up pretty concretely. I'm like, okay, step one is you do bounties for the company. Step two is you propose bounties for the company, right? You don't obviously pay them, we pay them. [00:54:52]Swyx: But you propose them. [00:54:52]George: And I'm like, yeah, that's a good bounty. That like, helps with the main workflow of the company. And step three is you get hired full-time, you get equity, we all, you know, maybe get rich. [00:55:01]Swyx: What else are you designing differently about the employee experience? [00:55:04]George: You know, some people really like to like, [00:55:06]Swyx: like keep a separation, right? [00:55:07]George: Some people really like to keep a separation between like employees and management or customers and employees. Like a comma, you know, the reason I do the DevKit thing, it's like, dude, you buy a comma thing, you're an employee of the company. Like you're just part of the company. It's all the same thing. There's no like secrets, there's no dividing lines. There's no like, it's all a spectrum for like, you know, down here at the spectrum, like you pay. And then up here at the spectrum, you get paid. You understand this is the same spectrum of college, right? Like for undergrad, you pay, and then you get up here to like, you know, I'm doing a PhD program, you get paid. Okay, well, cool. Welcome to the, you know. [00:55:39]Alessio: What about comma bodies? You mentioned a lot of this stuff is clearly virtual, but then there's below the API line you actually need. [00:55:47]Swyx: Wait, this is a thing that's been announced? Comma bodies? We sell them. You can buy them. [00:55:51]George: They're a thousand bucks on our website. [00:55:53]Swyx: Oh, okay, no, no, no. I'm thinking about like the, what Tesla announced with like the humanoid robots. It's the same thing. [00:55:58]George: Except of course, we made the comma version of it. Tesla uses 20 actuators. We use two, right? Like how do you build the simplest possible thing that can like turn the robotics problem into entirely a software problem? So right now it is literally just a comma three on a pole with two wheels. It balances, keeps the comma three up there. And like, there's so much you could do with that already. [00:56:21]Swyx: Right? [00:56:22]George: Like this should replace, how many security guards could this replace? Right? If this thing could just competently wander around a space and take pictures and, you know, focus in on things, send you a text message when someone's trying to break into your building, you know, like, like this could already do so much, of course, but the software is not there yet. Right? So how do we turn robotics into a thing where it's very clearly a software problem? You know, that people don't accept that self-driving cars are a software problem. Like, I don't, I don't know what to tell you, man. Like literally just watch the video yourself and then drive with a joystick, right? Can you drive? And we've actually done this test. We've actually done this test where you've had someone, okay, you just watch this video and here's a joystick and you got to drive the car. And of course they can drive the car. It takes a little bit of practice to get used to the joystick, but the problem is all the model, right? So I can now make the model better. [00:57:07]Swyx: Our second most popular episode ever was about segment anything coming out of Facebook, which as far as I understand the state of the art in computer vision, what are you hoping for there that you need for Karma? [00:57:17]George: I haven't used segment anything. Like they large, large YOLOs or not. I've used like large YOLOs and I'm super impressed by them. [00:57:24]Swyx: Yeah. [00:57:25]George: I got to check out segment anything. I don't think it's a distinct problem, right? Okay, here's something that I'm interested in. All right, we have great LLMs. We have great text to speech models and we have great speech to text models. Okay, so why can I not talk to an LLM? Like I'd have a normal conversation with it. [00:57:39]Swyx: You can with the latency of like two seconds every time. Right? [00:57:42]George: And then it feels so unnatural. It's this like staccato. Like I don't like the RLHF models. I don't like the tuned versions of them. You take on the personality of our customer support agent. Right? [00:57:53]Swyx: Like, oh, come on. [00:57:54]George: I like LLMA more than ChatGPT. ChatGPT's personality just graded on me. Whereas LLMA, like, cool. I read a little bit of pretext paragraph. I can put you in any scenario I want, right? Like, that's interesting to me. So yeah, I think there is really no like distinction between computer vision and language and any of this stuff. It's all eventually going to be fused into one massive. So to say computer vision is solved, well, it doesn't make any sense because what's the output of a computer vision model? Segmentation? Like, what a weird task, right? [00:58:26]Swyx: Who cares? OCR? [00:58:28]George: Who cares? [00:58:29]Swyx: I don't care if you can segment [00:58:29]George: which pixels make up that laptop. I care if you can pick it up. [00:58:32]Alessio: And you're going to have the local cluster. You're going to have the body. [00:58:36]Swyx: Yeah. [00:58:37]George: Yeah, I think that's kind of where that goes. [00:58:39]Swyx: Maybe we can paint the future of like, the year is 2050. You've achieved all you wanted at TinyCorp. What is the AI enabled future like? [00:58:48]George: Well, TinyCorp's the second company. Comma was the first. Comma builds the hardware infrastructure. TinyCorp builds the software infrastructure. The third company is the first one that's going to build a real product. And that product is AI Girlfriend. No, like I'm dead serious, right? Like, this is the dream product. This is the absolute dream product. Girlfriend is just the like- [00:59:08]Swyx: Stand-in. [00:59:09]George: Well, no, it's not a stand-in. No, no, no, no. I actually mean it, right? So I've been wanting to merge with a machine ever since I was like, mad little. [00:59:15]Swyx: Like, you know, I was just like, [00:59:16]George: how do I merge with a machine, right? [00:59:18]Swyx: And like, you can look at like, [00:59:19]George: maybe the Elon style way of thinking about it is Neuralink, right? I'm like, I don't think we need any of this, right? You ever, some of your friends maybe, they get into relationships and you start thinking of, you know, them and their partner as the same person. You start thinking of them as like one person. I mean, they are kind of like merged, right? Like, humans can just kind of do this. It's so cool. It's this ability that we already have. Right, so I don't need to put, you know, electrodes in my brain to merge with a machine. I need an AI Girlfriend, right? So that's what I mean. Like, this is the third product. This is the third company. And yeah, in 2050, I mean like, ah, it's so hard. I just like, maybe I can imagine like 2035. I don't even know 2050, but like, yeah, 2035. Like, yeah, that'd be really great. [01:00:03]Swyx: In terms of merging, like, isn't it, shouldn't you work on Brain Upload rather than AI Girlfriend? Brain Upload, right? [01:00:09]George: I don't need Brain Upload either. Like, there's thousands of hours of me on YouTube, right? Yes. How much of my brain's already uploaded? [01:00:17]Swyx: That's only the stuff that you voice. Yeah, it's not that different. [01:00:20]George: It's not that different, right? You really think a model with, you know, an exaflop of compute couldn't extract everything that's really going on in my brain? I'm a pretty open person, right? Like, I'm not running a complex filter. Humans can't run that complex of a filter. Like, humans just can't. Like, this is actually a cool quirk of biology. It's like, well, humans like can't lie that well. [01:00:39]Alessio: So is it good or bad to put all of your stream of consciousness out there? [01:00:43]George: I mean, I think it's good. [01:00:45]Swyx: I mean, he's streaming every day. I want to live forever. We said off mic that we may be the first immortals, right? Yeah, this is how you live forever. [01:00:54]George: It's a question of, okay, how many weights do I have? Right, okay, let's say I have a trillion weights, right? So talking about a terabyte, 100 terabytes here. [01:01:02]Swyx: Okay, but it's not really 100 terabytes, right? [01:01:03]George: Because it's Kolmogorov complexity. How much redundancy is there in those weights? So, like, maximally compressed, how big is the weight file for my brain? Quantize it whatever you want. Quantization is a poor man's compression. I think we're only talking really here about, like, maybe a couple gigabytes, right? And then if you have, like, a couple gigabytes of true information of yourself up there, cool, man. Like, what does it mean for me to live forever? [01:01:27]Swyx: Like, that's me. No, I think that's good. [01:01:29]Alessio: And I think there's a bit of, like, a professionalization of social media, where, like, a lot of people only have what's, like, PC out there, you know? And I feel like you're going to get, going back to the ChatGPT thing, right? You're going to train a model on, like, everything that's public about a lot of people. [01:01:44]Swyx: And it's like- [01:01:45]George: Then no one's going to run their model and they're going to die. Don't put PC on social media. [01:01:49]Swyx: We're moving on to what would normally be called the lightning round, but just general tics, because you're a generally interesting person with many other interests. What does the goddess of everything else mean to you? [01:01:59]George: Oh, it means that AI is not really going to kill us. [01:02:01]Swyx: Really? [01:02:01]George: Of course. [01:02:02]Swyx: Tell us more. [01:02:03]George: Lex asked me this, like, is AI going to kill us all? And I was quick to say yes, but I don't actually really believe it. I think there's a decent chance that AI kills 95% of us. [01:02:11]Swyx: Okay. [01:02:12]Alessio: But they saw on your Twitch streams that you're with them, so they're not going to- [01:02:16]Swyx: No, I don't think, I actually, [01:02:18]George: I don't also think it's AI. Like, I think the AI alignment problem is so misstated. I think it's actually not a question of whether the computer is aligned with the company who owns the computer. It's a question of whether that company's aligned with you or that government's aligned with you. And the answer is no, and that's how you end up dead. [01:02:31]Swyx: So what the goddess of everything else means to me [01:02:32]George: is like, the complexity will continue. Paper clippers don't exist. [01:02:37]Swyx: You know, there are forces. [01:02:38]George: The paper clipper is cancer, right? The paper clipper is really just a perfect form of cancer. And the goddess of everything else says, yeah, but cancer doesn't win, you know? [01:02:48]Swyx: Yeah, it's a beautiful story for those who haven't heard it. And you read it out and I listened to it. Yeah, what are you grateful for today? [01:02:55]George: Oh man, I mean, it's all just like, I haven't, I haven't thinking about this stuff forever. Like, that it's actually like happening and it's happening in an accessible way too. I guess that's what I'm really grateful for. It's not like, AI is not some Manhattan project style. You don't know anything about it. Closed doors. [01:03:12]Swyx: Closed doors. [01:03:13]George: I'll fight really hard to keep it that way. I'm grateful for just how much is released out there and how much I can just learn and stay up to date. And I guess I'm grateful to the true fabric of reality that, you know, I didn't need differential equations to understand it. Like, I don't need some like, there's a limit to my math abilities. I can do most undergrad math, but I took some grad math classes and okay, now we're getting to the end of what I can do. And it's just the actual like, end of what I can do. Like, I'm limited by my brain, but you know, ML stuff, hey, you need high school math. [01:03:45]Swyx: You know what I mean? [01:03:46]George: When I learned to multiply a matrix, seventh grade, [01:03:48]Swyx: like, it's all easy. You need more electrical engineering than you need high school math early. [01:03:52]George: Yeah, well, you need electrical engineering to like, build the machines, but even that, like, these machines are simpler than the machines that have existed before. The compute stack looks really nice. So, you know, yeah, I just, I'm grateful that it's all happening and I get to understand it. [01:04:05]Alessio: John Carmack mentioned there's about six insights we have left. Do you have an intuition for what some of the paths [01:04:11]Swyx: people should be taking? [01:04:12]Alessio: Obviously you're working on one. What are some of the other branches of the tree that people should go under? [01:04:17]George: I don't think I'm working on one of the six insights. I don't think TinyGrid's any one of the six insights. Something I really like that Elon does, and I try to be inspired by it, is look at the boring tunnel machine and ask how you can build a 10X cheaper one. All right, look at the rocket. How can I build a 10X cheaper one? All right, look at the electric car and say, how can I build a 10X cheaper, like, cheaper or, you know, can go further or whatever, whatever, whatever, right? And you just do the straight up physics math, right? I'm trying to do the same thing with ML frameworks, right? And in doing so, making sure that this stuff remains accessible. You could imagine a world where if Google TPUs were actually the ultimate, if Google TPUs were actually the best training things, I mean, actually, you know, I'm kind of grateful for NVIDIA, right? Because if Google TPUs were the ultimate, now you have this huge closed source compiler in between XLA and the hardware, and yeah, that's just a really bad thing. So, I mean, something that is somewhat upsetting about the Tiny Core is that it is trying to prevent downside, but it's not all trying to prevent downside. Like, we're also building computers and we're gonna build some awesome, powerful, cheap computers along the way. So, no, I'm not really working directly on any of the six tricks. I also think the six tricks are kind of gonna be like luck. [01:05:25]Swyx: I think it's just gonna be like, you know, [01:05:26]George: please tell me more about what covariate shift is and how that inspired you to come up with batch normalization. Please tell me more about why it's a transformer and it has a query, a key, and a value, right? Like Schmidt-Huber described it better in fast weights. I mean, my theory about why transformers work have nothing to do with this attention mechanism and just the fact that it's semi-weight sharing, right? Because the weight matrix is being generated on the fly, you can compress the weight matrix, right? Like, this is what that, there's an operation in the transformer, which, and by the way, this is like, Qualcomm's SNPE can't run transformers for this reason. So, most matrix multipliers in neural networks are weight times values, right? Whereas when you get to the outer product in transformers, well, it's weight times weight. It's values times values, right? So, SNPE doesn't even support that operation, right? So, it's like that operation that gives the transformer its power. It has nothing to do with the fact that it's attention, [01:06:20]Swyx: right? [01:06:21]George: And this is a funny, like, but that is one of the six tricks, right? Batch, like these norms are a trick. Transformers are a trick. Okay, six more. [01:06:29]Swyx: So, you talk about attention as weight compression. [01:06:33]George: Compression is not exactly the right word. What I mean is that the weight can change dynamically based on the context. So, there was this thing in PAC-8 in the Hutter Prize that I absolutely loved, and I've never seen it again in neural networks, and it's a really good trick. Okay, imagine you have 256 weight sets for a layer, right? And then you choose which of the weight sets you're loading in based on some context. And that context can come from another neural net, right? So, I have another neural net, which projects 256 wide, one hot, do a softmax, predict it, and then I actually load the weights in. And I can do this operation at both test time and train time. I can do this operation at both training and inference, and I load in the weights given the context. Like, that is what transformers do. But transformers, instead of having 256 discrete ones, it's actually just that, but continuous. Which is funny that that was in language models, and I just like, when I understood that about transformers, I'm like, oh, this is a real trick, and why are they using the word attention? [01:07:23]Alessio: And today is actually the anniversary of attention is all you need. What? [01:07:27]Swyx: Oh, that's so cool. [01:07:28]Alessio: Today, six years ago. [01:07:29]Swyx: Six years. [01:07:30]George: Six years. [01:07:31]Swyx: Changed the world. Wow. [01:07:32]George: Well, there's one of your envelope tricks, right? And you could easily write it on an envelope, think about how you write out that. How many times have you written that? Because it's not in any libraries, because it's all used a little differently each time. Like, you just write out that exact same, you know. [01:07:45]Swyx: You've name checked Elon a few times. I think about both of you as systems thinkers. Input, output, thinking something in between. What's different about your style versus his? [01:07:53]George: Elon's fundamental science for the world is physics, mine is information theory. But you do a lot of physics as well. [01:07:58]Swyx: I mean, like, you base it on- [01:07:59]George: And Elon does a lot of information theory as well, too. But the difference maybe is expressed in what your ambitions are, right? Elon's ambitions may be like- [01:08:08]Swyx: Go to Mars. Go to Mars, right? [01:08:10]George: Go to Mars is the ultimate modernist physics ambition, right? It's a physics problem getting to Mars, right? [01:08:16]Swyx: Well, what are electric cars? [01:08:17]George: It's a physics problem, right? Okay, now he's like pushing on the autonomy stuff, and you push a little on information theory. But fundamentally, his dreams are physics-based dreams. My dreams are information-based dreams. I want to live forever in virtual reality with my AI girlfriend. Those are the aspirations of someone who accepts information theory as a core science. So I think that's the main difference between me and him. He has physics-based aspirations, and I have information-based aspirations. [01:08:39]Swyx: Mark Andreessen, he is a- Hi, Mark. He's a listener. He's a big proponent of effective accelerationism. You've been a bit more critical. Why do you say that IAC is not taken seriously by its adherents? [01:08:50]George: Oh, well, only the left takes ideology seriously. It's just like a fact, right? [01:08:55]Swyx: Is the right more cynical? Is that what it is? [01:08:57]George: I don't know. [01:08:58]Swyx: It's like the left actually manages [01:08:59]George: to get energy around the ideologies, right? [01:09:02]Swyx: Look, here you have- [01:09:03]George: You have two effective altruists named Sam going in front of Congress. Only one of them is in jail. [01:09:08]Swyx: You know, it's interesting. [01:09:09]George: They're both calling for regulation in their respective spaces, right? [01:09:11]Swyx: So SBF is definitely like kind of wolf in sheep's clothing, kind of, right? Like he only adopted IAC or EA to market. [01:09:19]George: Oh, and Sam Altman is a genuinely good guy who is not interested in power-seeking for himself. [01:09:24]Swyx: All right. Okay, okay. We don't have to go there. Fair enough, fair enough. [01:09:27]George: But no, IAC is not like, like you are not serious, right? Mark Andreessen, I like Mark Andreessen, but it's like someone who's like 2019, whose like eyes were opened about like the political world being not exact. You mean all the people on the news were lying to me? [01:09:42]Swyx: Bro, they were lying to you. [01:09:43]George: Like, okay, we all figured this out five years ago. Now, what are you going to do about it? I'm going to complain about it on Twitter. Great, and that's what IAC is. [01:09:50]Alessio: Last and maybe most important, why was Avatar 2 bad? [01:09:55]Swyx: Oh, I have a whole, you can go on my blog. [01:09:56]George: I rewrote the script of Avatar 2. I wrote a script that actually might make you feel something for the characters. I killed Jake Sully in the first scene. Like you had to. Do you really think his second story art topped his first one? No, of course not. You had to kill the guy and make the movie about the brothers, right? And just that alone and realizing that, like you could have kept the Titanic scene. [01:10:16]Swyx: It would have been fine. [01:10:16]George: I didn't even take it out. I left your Titanic scene, James Cameron, but I wrote you a story. So, you know, you're just, just, just. [01:10:23]Swyx: He needs ships to sink in water. [01:10:24]George: Look, it's a great scene, but like the movie was just like, like the Roman, I've never. [01:10:30]Swyx: Great CGI, you know, let down by the writing maybe. It's a beautiful world. [01:10:34]George: And that's why like I care so much, right? Like you don't hear me ranting about Pirates of the Caribbean 2 being a terrible story. Cause come on, what do you expect, man? Like Johnny Depp's like, wow, I had a movie that made me rich. I love this. [01:10:44]Alessio: But this goes back to like the midpoint. You know, I think you wrote like, feels like ChatGPT wrote the movie and that's my worry a little bit. It's like kind of converging towards that. [01:10:53]Swyx: Oh, I. Malik, Malik wrote the movie. Sorry, I didn't want to interrupt you. [01:10:59]George: I closed a pull request two days ago. I was like, was this written by ChatGPT? And I just closed it. [01:11:04]Swyx: Like, you know what? [01:11:05]George: I honestly feel bad if you were a human who wrote this. [01:11:07]Swyx: Incapable of being more perplexed. [01:11:09]George: But if you, if I have a classifier running in my head that asks, you know, is this a AI or is this a human? Like, you know, the only way to deal with all this, like, like, like, oh God, it's like the worst possible. Like, you know, people are like, how are you mad about like these chatbots? You're not mad about like Tesla. I don't want to buy a Tesla. I don't have to buy a Tesla. And it won't really impact my life negatively. But if I don't want to use a chatbot, it's still going to impact my life negatively. All the amount of like personalized spam that now makes me spend more cycles on my classifier to tell if it's spam or not, because you can now use AIs and generate this so cheaply. Like, no, I mean, we have to move to a model where everything's just a dollar, right? Like you want to send me an email, it's a dollar. Like you guys wouldn't care. None of my friends would care. No one would care, except the spammers, right? Like we just got to move to those sort of models. [01:11:54]Swyx: Awesome. [01:11:55]Alessio: One last message you want everyone to remember. [01:11:58]George: Go try TinyGrad. I hope that we're a serious competitor to what's out there. And then I want to take it all the way. We'll start with just building something for GPUs and then we'll start building chips and then we'll start building fabs and then we'll start building silicon mines and then we'll have the first self-reproducing robot using. [01:12:15]Swyx: Yeah, okay. All right, George. [01:12:18]Alessio: Thank you so much for coming on. [01:12:19]Swyx: You did a big inspiration. Thank you. Thanks. [01:12:21]Swyx: Thank you. [01:12:29] Get full access to Latent Space at www.latent.space/subscribe
Tue, June 20, 2023
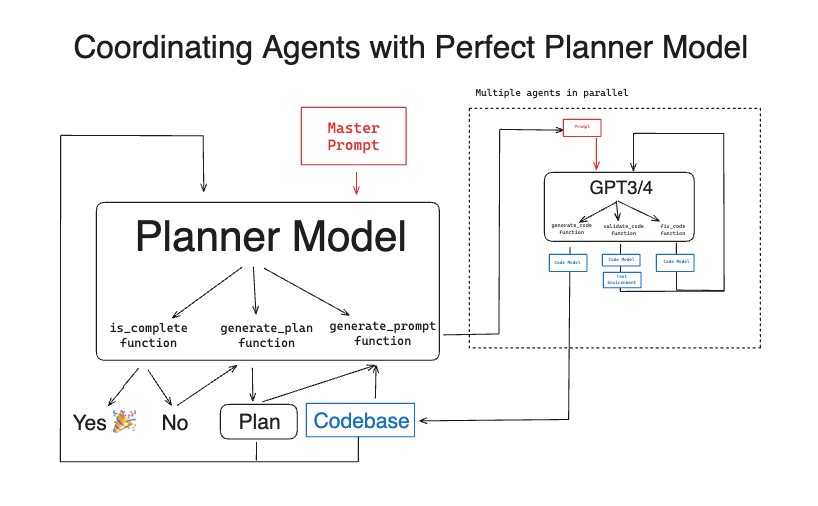
Emergency Pod: OpenAI's new Functions API, 75% Price Drop, 4x Context Length (w/ Alex Volkov, Simon Willison, Riley Goodside, Joshua Lochner, Stefania Druga, Eric Elliott, Mayo Oshin et al)
Full Transcript and show notes: https://www.latent.space/p/function-agents?sd=pfTimestamps:[00:00:00] Intro[00:01:47] Recapping June 2023 Updates[00:06:24] Known Issues with Long Context[00:08:00] New Functions API[00:10:45] Riley Goodside[00:12:28] Simon Willison[00:14:30] Eric Elliott[00:16:05] Functions API and Agents[00:18:25] Functions API vs Google Vertex JSON[00:21:32] From English back to Code[00:26:14] Embedding Price Drop and Pinecone Perspective[00:30:39] Xenova and Huggingface Perspective[00:34:23] Function Selection[00:39:58] Designing Code Agents with Function API[00:42:16] Models as Routers[00:46:48] Prompt Engineering replaced by Finetuning[00:52:15] The 2 Code x LLM Paradigms[00:56:30] Smol Models for the future[00:58:54] The Evolution of the GPT API[01:03:27] Functions API Security vs Prompt Injection[01:16:18] GPT Model Upgrades[01:17:36] JSONformer[01:21:03] Closing Comments - What We Want Next Get full access to Latent Space at www.latent.space/subscribe
Wed, June 14, 2023
🔭
v:
Made with ☕️ in SF/SD.
© 2023 Spyglass Search, Inc.